4) 학식 메뉴 크롤링 하기
Index
인천대학교-에밀리에 처음 추가한 기능은 교내 식당의 메뉴를 알려주는 기능이였습니다. 학교 DB에 접근할 수 있는 권한이 없었기 때문에 하루마다 매일 갱신되는 식당의 메뉴를 알기 위해서는 학교 홈페이지에서 데이터를 참조하는 방법밖에 없었습니다. 이를 해결하기 위해 **크롤링**에 대해 공부하고 구현했던 방법에 대해 포스팅하려 합니다.
## 크롤링이란?Node 버전은 6.6.0을 사용합니다.
우리가 흔히 부르는 **크롤링(crawling)**이란 **스크래핑(scraping)**이라고도 합니다. 즉 웹 페이지를 그대로 가져와 데이터를 추출해 내는 행위입니다. 크롤링 하는 소프트웨어를 크롤러(crawler)라고 부릅니다.
웹 크롤러(web crawler)는 조직적, 자동화된 방법으로 월드 와이드 웹(WWW)을 탐색하는 프로그램입니다. 검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링을 합니다. 웹 크롤러는 대체로 방문한 사이트의 모든 페이지 복사본을 생성하는데 사용되며, 검색 엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱합니다.
웹 크롤러는 시드(seeds)라고 불리는 URL 리스트에서부터 시작해서 페이지의 모든 하이퍼링크를 인식하여 URL 리스트를 갱신합니다. 갱신된 리스트를 재귀적으로 다시 방문합니다.
결국 웹 크롤러는 엄청난 분량의 웹문서를 사람이 직접 구별해서 모으는 일은 거의 불가능하기 때문에, 이를 자동으로 수행해 주는 것입니다.
웹은 기본적으로 HTML 형태로 되어 있습니다. 아래와 같이 **페이지 소스 보기**를 통해 확인할 수 있습니다.
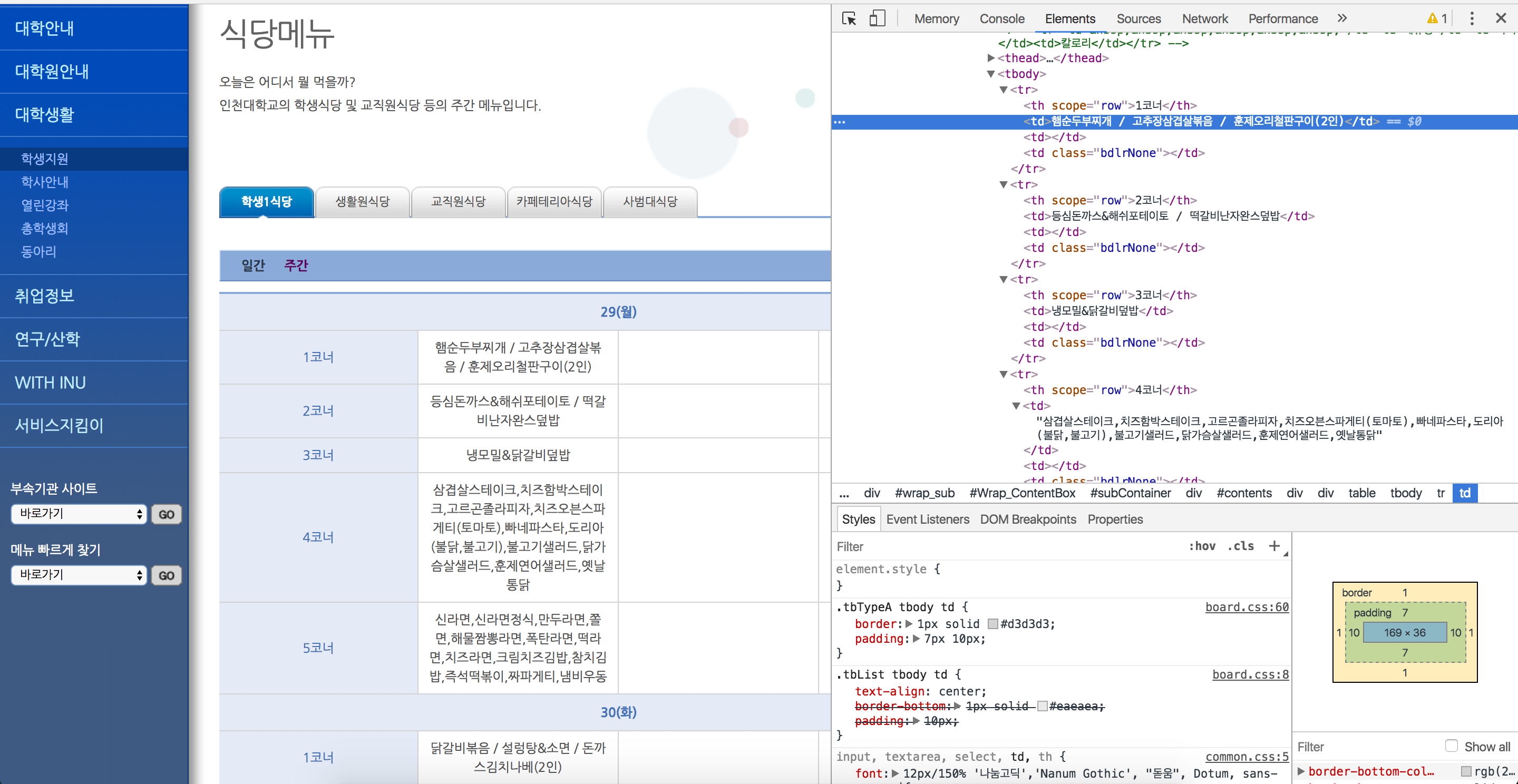
위와 같은 HTML의 형태를 분석해서 원하는 정보만을 뽑아오는 것을 **웹 크롤링**작업이라고 합니다.
웹 사이트의 데이터를 수집하는데 있어서 2가지 단계만 기억하면 됩니다. 일반적으로는 이 2가지 과정을 합쳐 크롤링이라고 부르지만, 각각의 단계는 명확히 구분됩니다.
1.Scraping : 데이터를 어떻게 가져올 것인가?
2.Parsing : 가져온 데이터를 어떻게 추출할 것인가?
## Scraping - 데이터 가져오기
Javascript에서 웹 페이지 데이터를 가져오기 위해서 request 모듈을 사용합니다.
먼저 request 모듈을 설치합니다.
1 | npm install request --save |
1 | const request = require('request'); |
위의 코드를 실행하면 아래와 같이 제가 얻고자 했던 학식 메뉴의 데이터를 포함한 웹 페이지 데이터를 가져옵니다. 해당 데이터는 크롬에서 **보기 - 개발자 정보 - 소스 보기**를 통해서도 확인이 가능합니다.
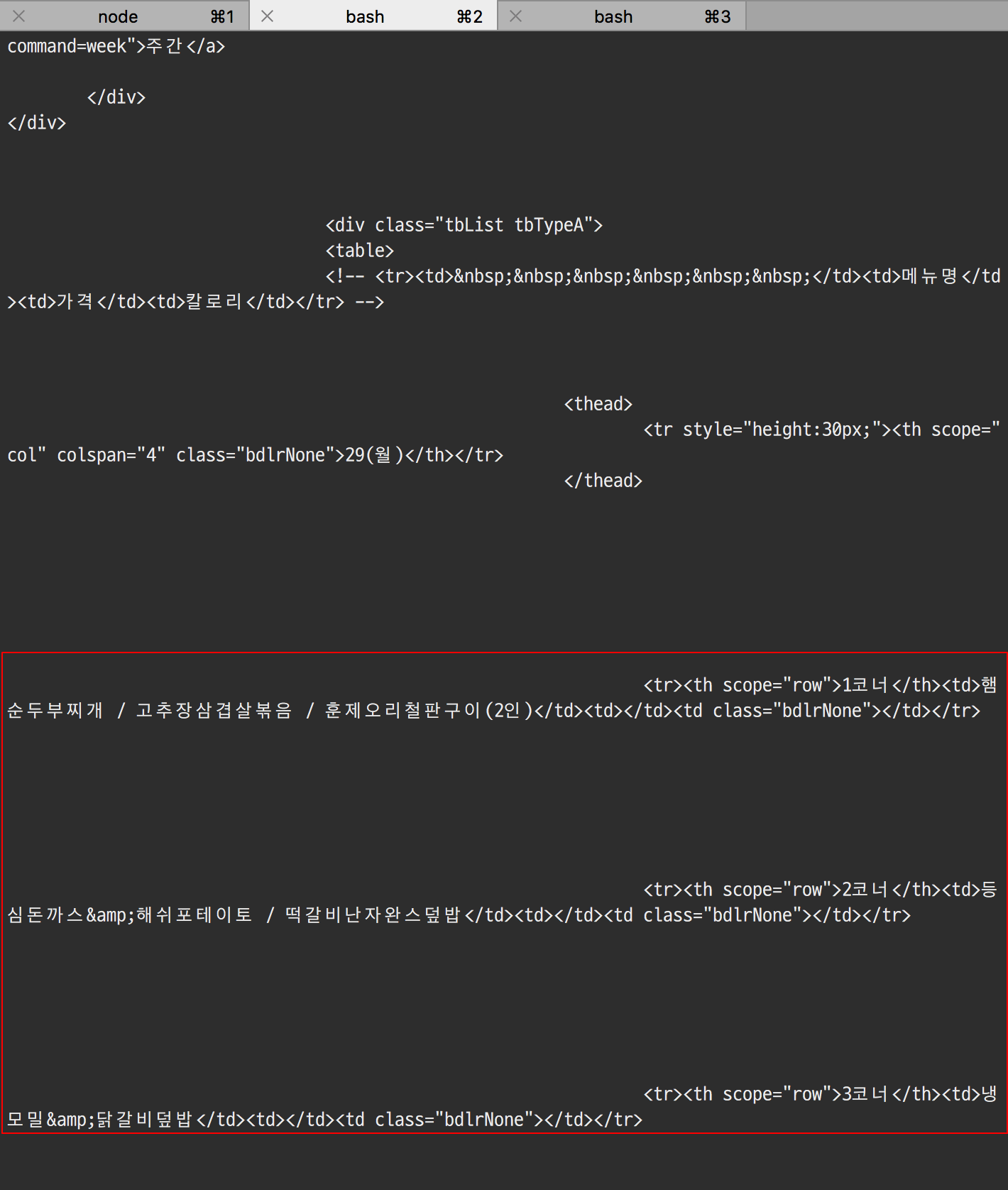
## Parsing - 데이터 추출하기
Scraping을 통해 가져온 데이터에서 원하는 데이터만을 추출(Parsing)하기 위해 cheerio 모듈을 사용합니다.
cheerio 모듈을 설치합니다.
1 | npm install cheerio --save |
cherrio 모듈을 사용하면 웹 클라이언트 자바스크립트 라이브러리인 jQuery 에서 사용하는 것 처럼 style을 통해 element를 선택할 수 있어, 기존의 선택자 방식을 그대로 사용할 수 있습니다.
따라서 cherrio를 사용하기 위해서는 Request 모듈을 통해 가져온 HTML 데이터에서 어떤 element가 우리가 원하는 데이터를 갖고 있는지 파악할 필요가 있습니다.
웹 페이지의 HTML 구조는 크롬의 **보기 - 개발자 정보 - 개발자 도구**를 통해 확인할 수 있습니다.
학식 메뉴 데이터를 포함하고 있는 table은 다음과 같은 구조를 갖고 있습니다.
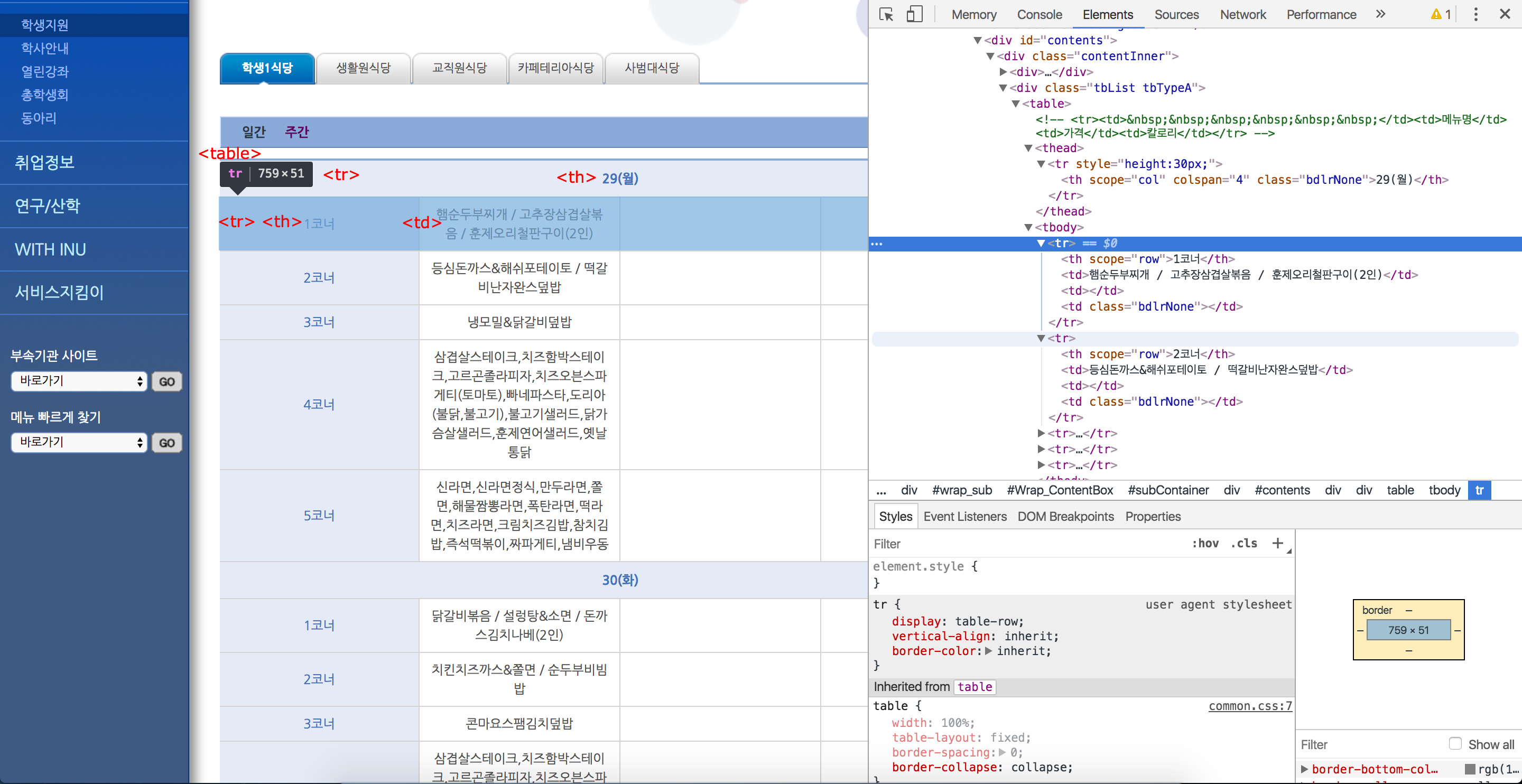
1 | <table> |
제가 필요한 데이터는 1. 날짜, 2. 코너, 3. 메뉴 인데 이 데이터는 다음과 같은 구조로 존재합니다.
table 태그 안에 thead > tr > th 에는 날짜, tbody > tr > th 에는 코너, tbody > tr > td 에는 메뉴가 있습니다.
thead와 tbody 태그를 사용해서 데이터를 추출할 수 있지만 테이블이 규칙적으로 만들어져 있기 때문에 table 태그의 tr 태그만 추출한 후 규칙을 이용해서도 쉽게 데이터를 추출 할 수 있습니다.
table에서 하루의 식단은 6개의 tr 태그마다 반복 되고 있습니다.
1번째 tr 태그는 th 태그 안에 날짜 데이터를 갖고 있고,
2번째~6번째 tr 태그는 th 태그 안에는 코너 데이터를, td 태그 안에는 메뉴 데이터를 갖고 있습니다.
이를 이용해 다음과 같이 코드를 작성할 수 있습니다.
1 | const request = require('request'); |
결과는 다음과 같습니다.
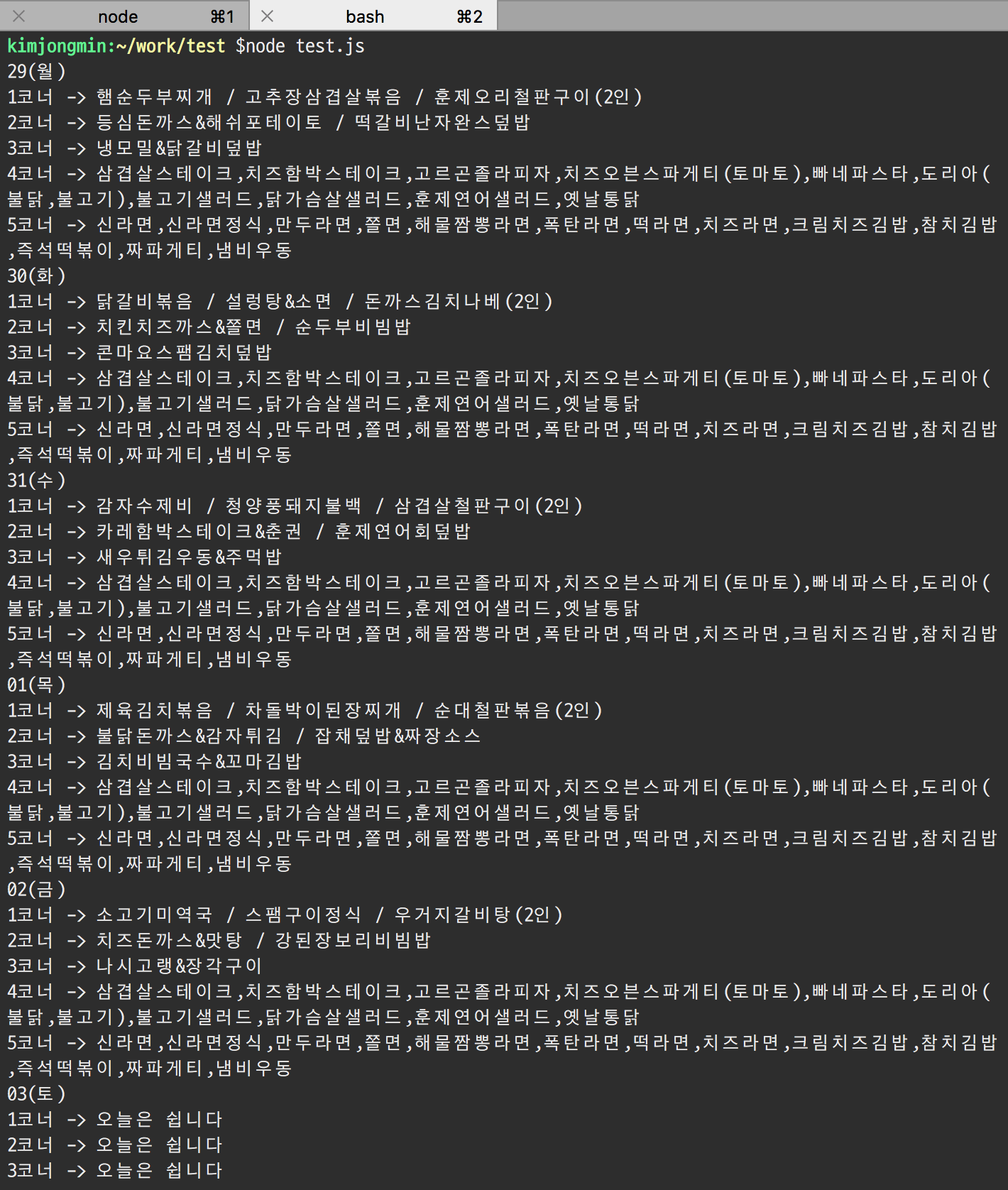
## 크롤링 이후
크롤링을 통해 원하는 데이터를 추출했다면 이를 활용해야 합니다. 에밀리에서는 사용자의 요청(학생식당, 카페테리아, 사범대식당, 기숙사식당, 교직원식당)에 따라 해당하는 식당의 메뉴를 제공합니다.
메뉴라는 데이터 특성상 실시간으로 변경되는 데이터가 아니기 때문에 한번 크롤링 하고 나면 사용자의 요청(식당)에 따라 다른 응답해주면 될 뿐 데이터 자체는 요일이 변경되지 않는이상 계속 유효합니다. 따라서 학교 사이트에서 메뉴를 크롤링하는 행위는 학교 메뉴가 갱신되는 일주일 주기마다 한번씩만 하고 크롤링한 데이터를 DB에 저장한다면 사용자의 요청마다 반복적인 크롤링을 하지 않을 수 있습니다.
이를 위한 해결 방법으로는 node-schedule 모듈을 사용해서 정해진 시간마다 실행되도록 하는 방법이 있습니다.
혹은 AWS-Lambda를 사용할 수도 있습니다.
저는 AWS-Lambda 를 사용해서 스케쥴링을 하였는데 이와 관련된 내용은 다음에 포스팅하도록 하겠습니다.
4) 학식 메뉴 크롤링 하기