6) AWS S3를 이용한 웹 호스팅
Index
- 에밀리 시간표 웹 페이지
- AWS S3란?
- 도메인 등록
- S3 버킷 생성
- 웹 사이트 데이터 업로드
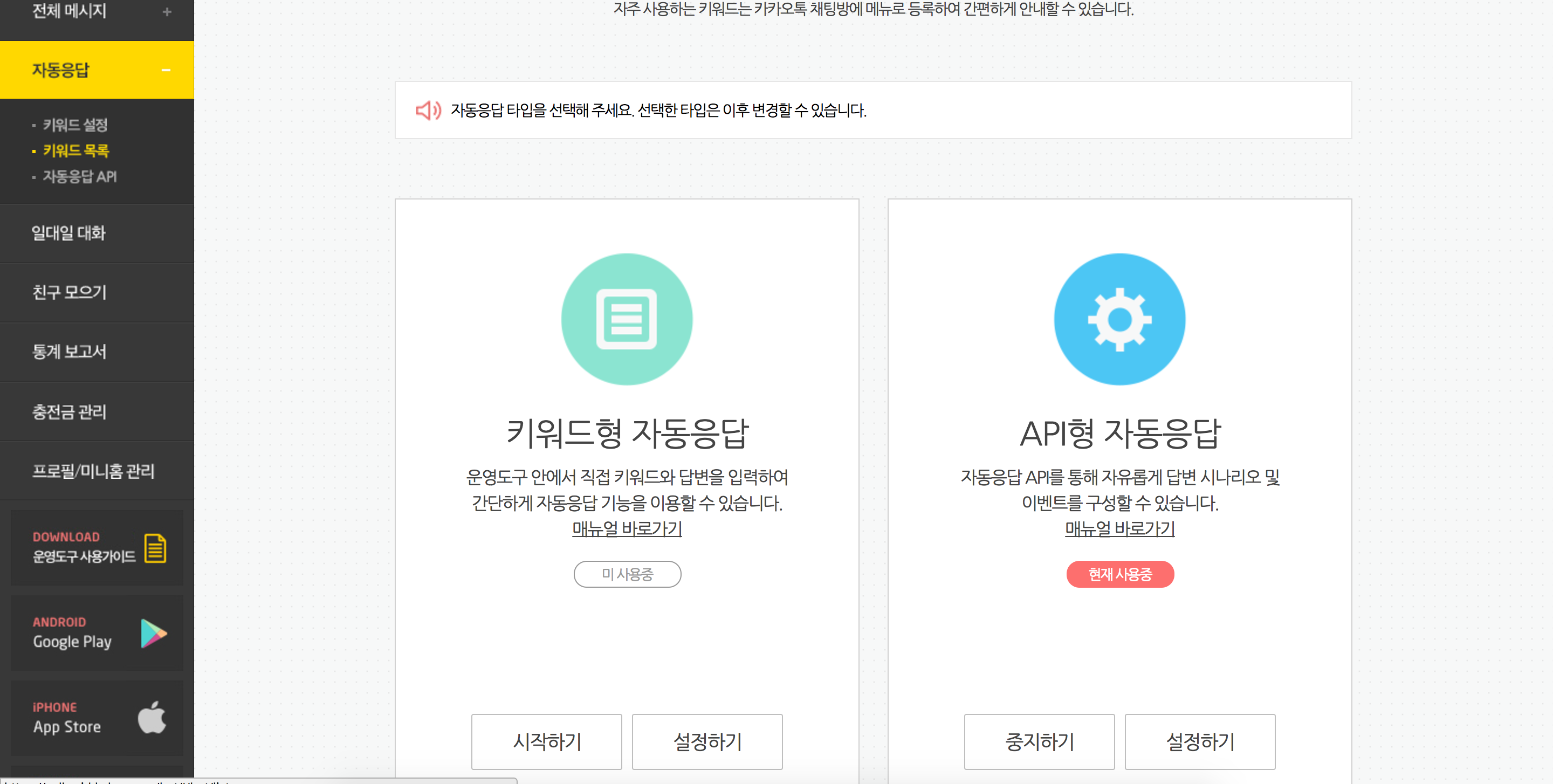
- 버킷 정책(Permissions) 설정
- 버킷 정적 웹 사이트 호스팅 기능 활성화
- 버킷 Record Set 설정
## 에밀리 시간표 웹 페이지
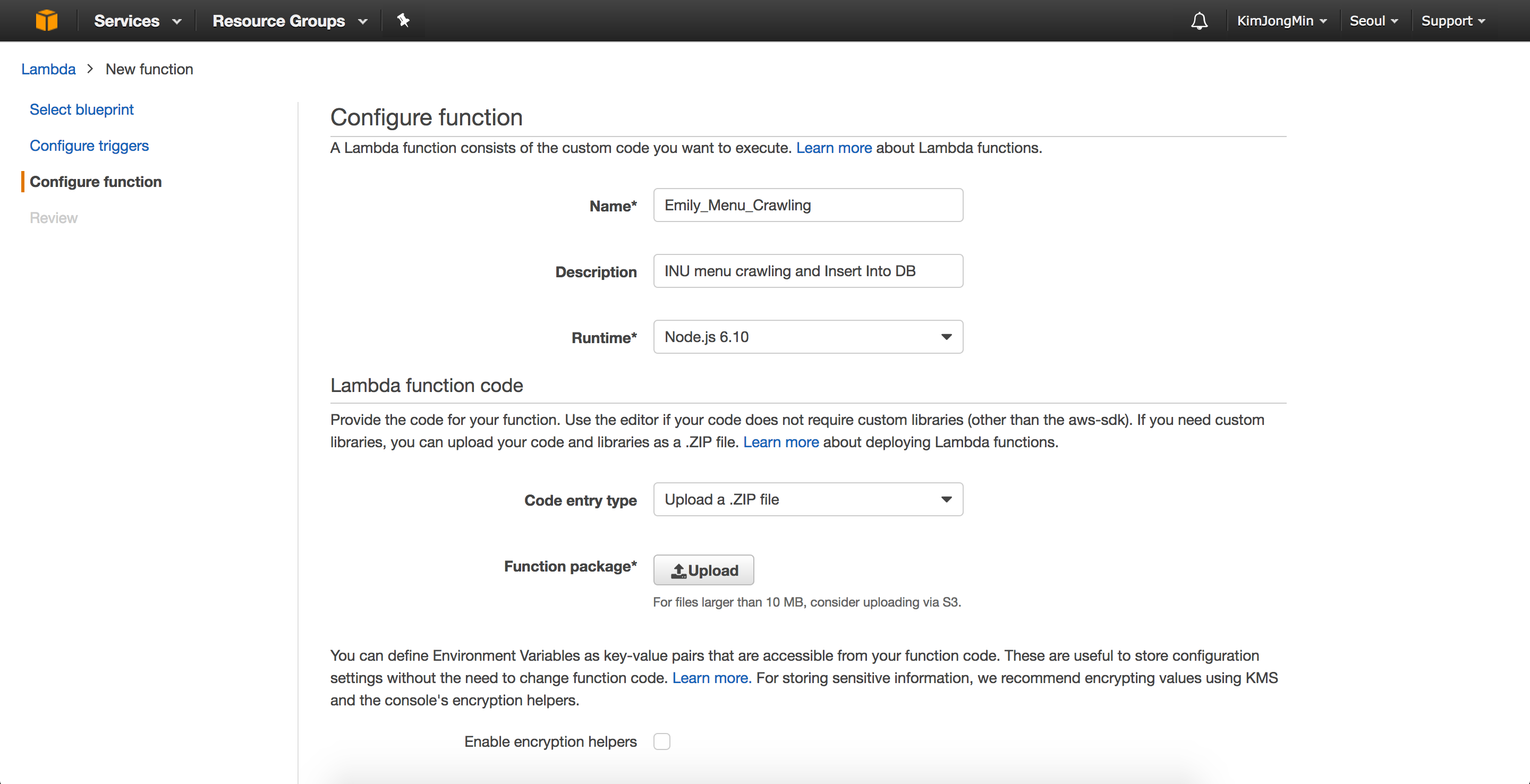
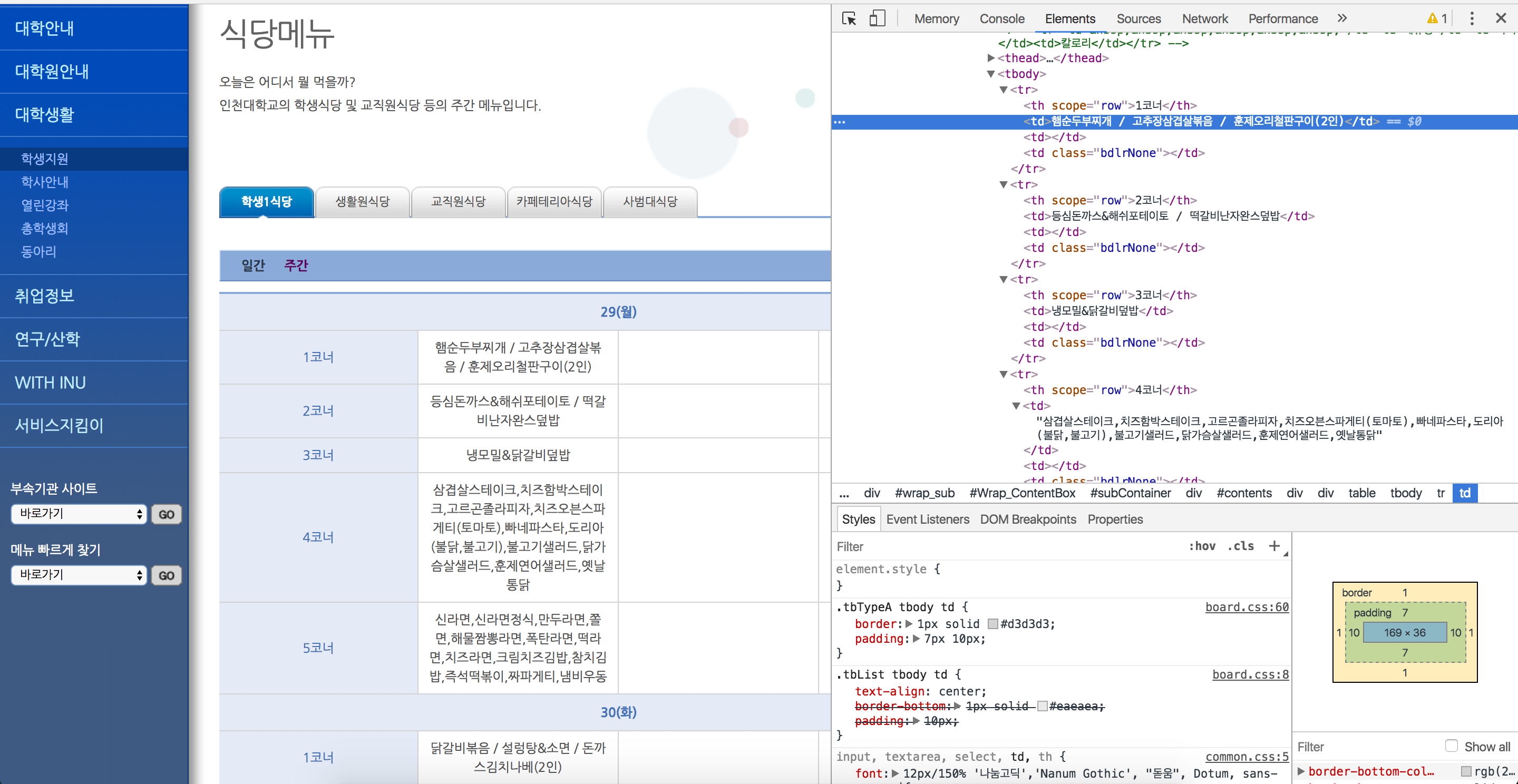
학생들에게 필요한 기능이 어떤게 있을까 생각하다 에밀리에 **시간표 기능**을 추가하게 되었습니다. 학생들이 수강하고 있는 수업 데이터를 얻을 수 있으면 좋겠지만 학교 DB에 접근할 수 있는 권한이 없기 때문에 학생들이 직접 에밀리를 통해 시간표를 등록하도록 만들어야 했습니다.
학교 홈페이지에서 제공하는 **수업 목록(엑셀 파일)**를 활용(파싱)하여 시간표 데이터를 만들고, 이를 학생들이 쉽게 등록 및 수정할 수 있도록 웹 페이지를 만들었습니다 (아무래도 전공도 다양하고 수업의 수도 많다보니 단순히 버튼 및 텍스트로 상호작용하여 시간표를 등록하는것은 불편하다고 판단해 시간이 좀 더 걸리더라도 웹 페이지를 만들기로 결정했었습니다.)
학생들이 많이 사용하는 여러 시간표 앱 및 웹 서비스를 참고해서 다음과 같은 **시간표 등록 및 수정 페이지**를 만들었습니다.

참고로 에밀리 시간표 등록 및 수정 페이지는 **React(Starter-Kit)**를 이용해서 만들었습니다. 아무래도 회사에서 React Native를 사용해서 앱을 개발하다보니 React를 사용해 웹 개발을 함에 있어서도 도움이 많이 되었습니다.
## AWS S3란?
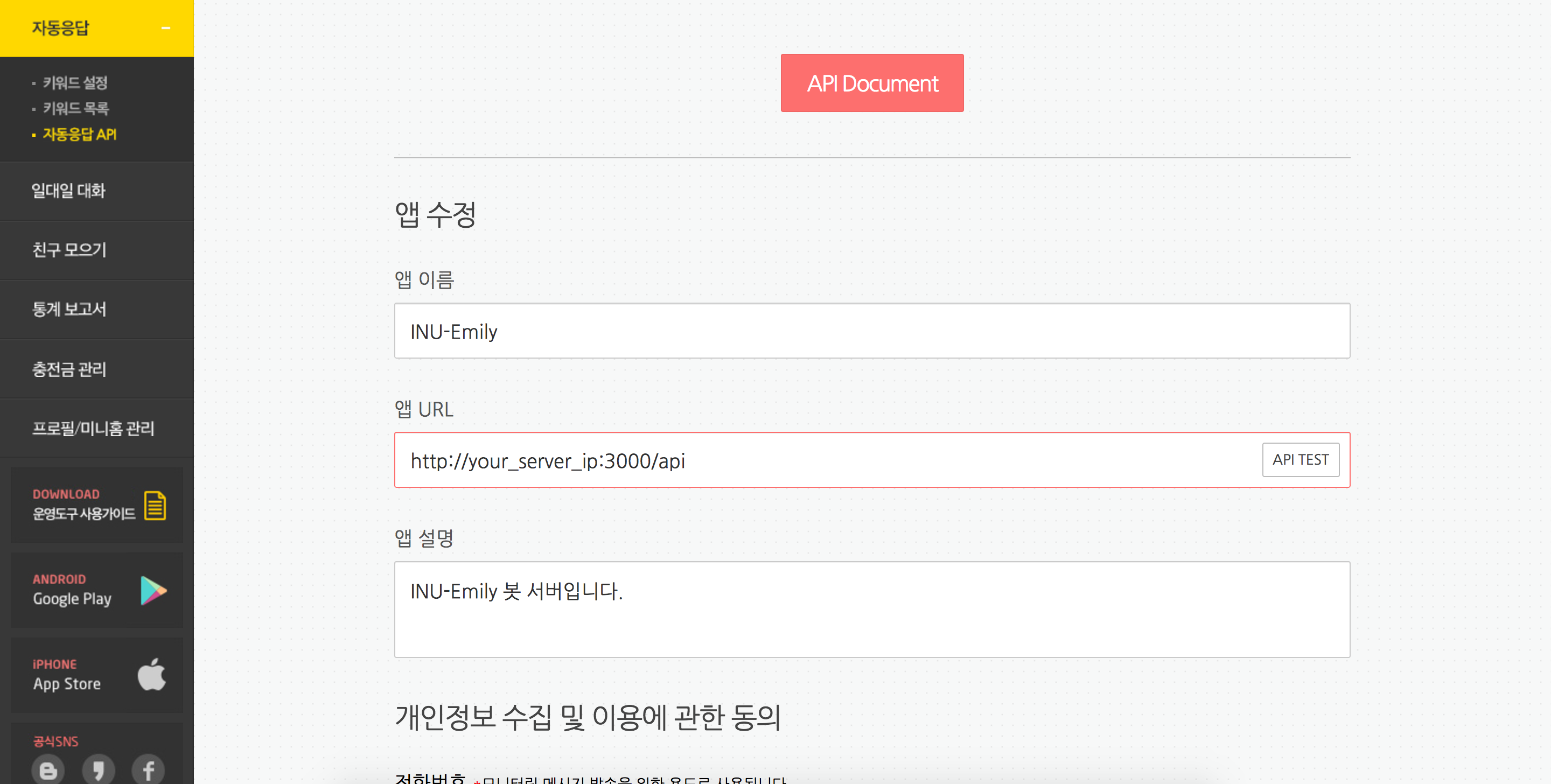
사용자들이 에밀리 시간표 페이지를 사용할 수 있도록 하기 위해서는 웹 페이지를 호스팅해야합니다. 간단히 호스팅할 수 있는 여러 방법들이 있지만, AWS 공부도 할겸 S3를 이용해 호스팅해보기로 생각했습니다.
먼저 S3에 대해 간단하게 알아보겠습니다. **S3(Simple Storage Service)**는 파일을 저장하기 위한 Storage입니다. 일반적인 파일시스템의 개념과는 약간 다르며, 파일 이름을 대표하는 key와 파일 자체로 구분되는 Object Storage입니다.
S3는 **정적 웹사이트 호스팅 기능**을 사용하는 S3 버킷을 **Route 53**을 통해 도메인과 연결해 사용할 수 있습니다. 여기서 동적 웹 사이트 PHP, JSP 등 서버 측 처리에 의존하는 사이트는 S3를 이용해 호스팅할 수 없습니다. 오직 개별 웹 페이지에서 정적 컨텐츠를 포함하며, 클라이언트 측 스크립트를 포함하고 있는 정적 웹 사이트만이 호스팅 가능합니다. (React의 경우 webpack을 통해 번들링된 파일을 호스팅하면 됩니다.)
## 도메인 등록
이미 등록된 도메인이 있다면 이 단계를 생략하면 됩니다. 그러나 inuemily.com과 같이 등록된 도메인 이름이 없는 경우, 원하는 도메인 이름을 만들어 등록해야 합니다.
도메인이 없으시다면 AWS의 Route53 - Registered domains를 통해 도메인을 생성하고, AWS가 아닌 다른 서비스로부터 도메인을 사용중 이라면 기존 도메인 DNS 서비스 역할을 하는 AWS Route53으로 마이그레이션을 해야 S3를 이용한 정적 웹사이트 호스팅이 가능합니다. 마이그레이션 관련해서는 AWS 문서를 참고하면 좋을것 같습니다.
저는 다음과 같이 inuemily.com 이라는 도메인을 갖고 있습니다.
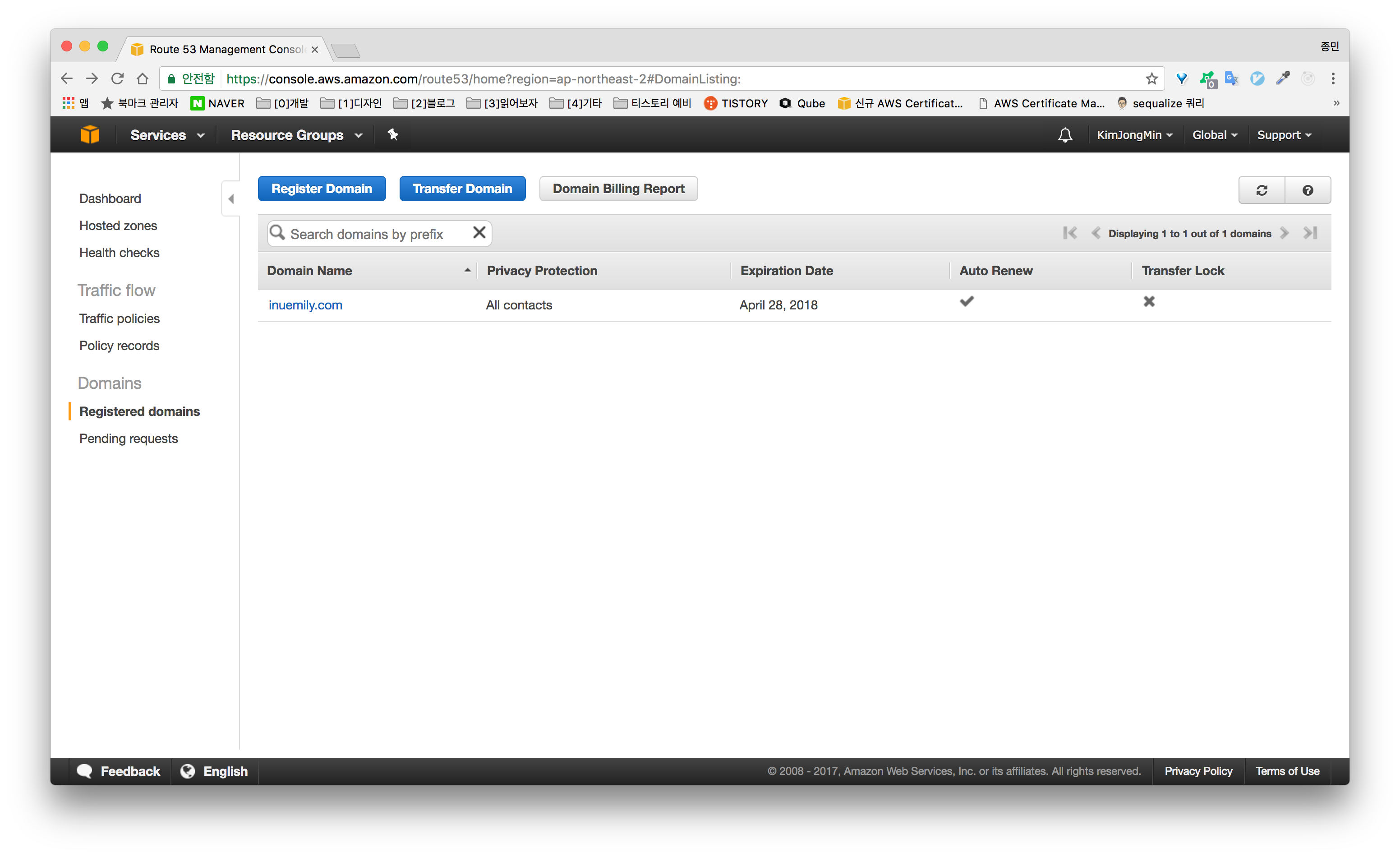
## S3 버킷 생성
inuemily.com과 같은 루트 도메인, www.inuemily.com과 같은 하위 도메인 양쪽의 요청을 모두 지원하려면 두 개의 버킷을 생성해야합니다. 하나의 버킷에 컨텐츠를 포함하고 다른 버킷은 컨텐츠를 포함하는 버킷에 redirection 하도록 버킷을 구성할 것입니다.
먼저 버킷 이름을 호스팅할 웹 사이트 이름과 일치하게 생성합니다. 저는 inuemily.com과 www.inuemily.com 이름으로 버킷을 생성했습니다.
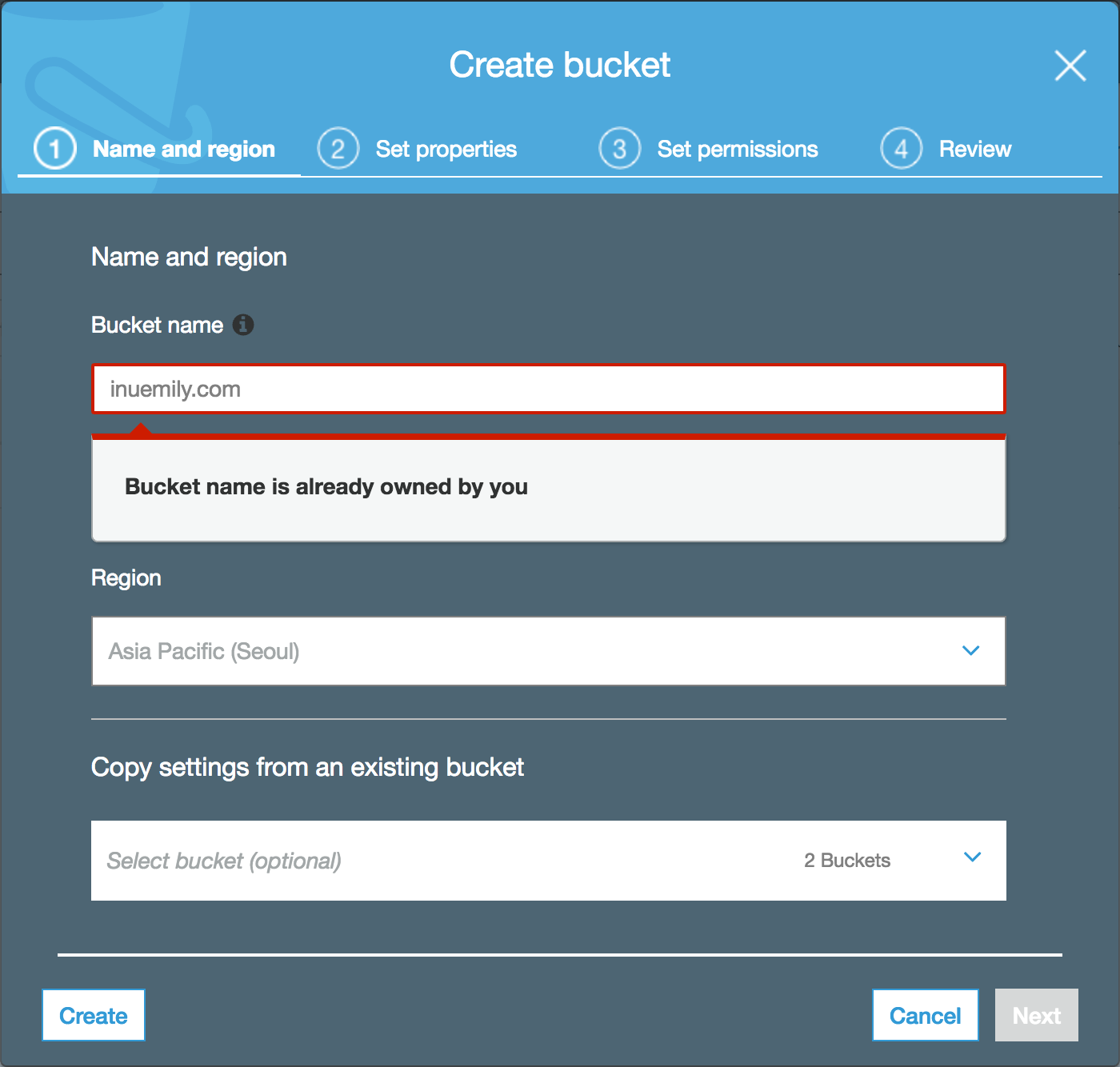
## 웹 사이트 데이터 업로드
2개의 버킷을 모두 생상하였다면 루트 도메인 버킷(inuemily.com)에 컨텐츠를 업로드합니다. 두 번째 버킷(www.inuemily.com)은 추후에 이 루트 도메인 버킷으로 redirection 하도록 설정할 것입니다.
S3 버킷에 파일을 업로드하는 방법으로는 1) 드래그 앤 드롭, 2) AWS CLI 사용 과 같이 2가지 방법이 있습니다. 저는 드래그 앤 드롭을 이용해서 파일을 업로드 하였습니다. (webpack으로 번들링되어 나온 public 폴더의 파일들을 업로드 하였습니다.)
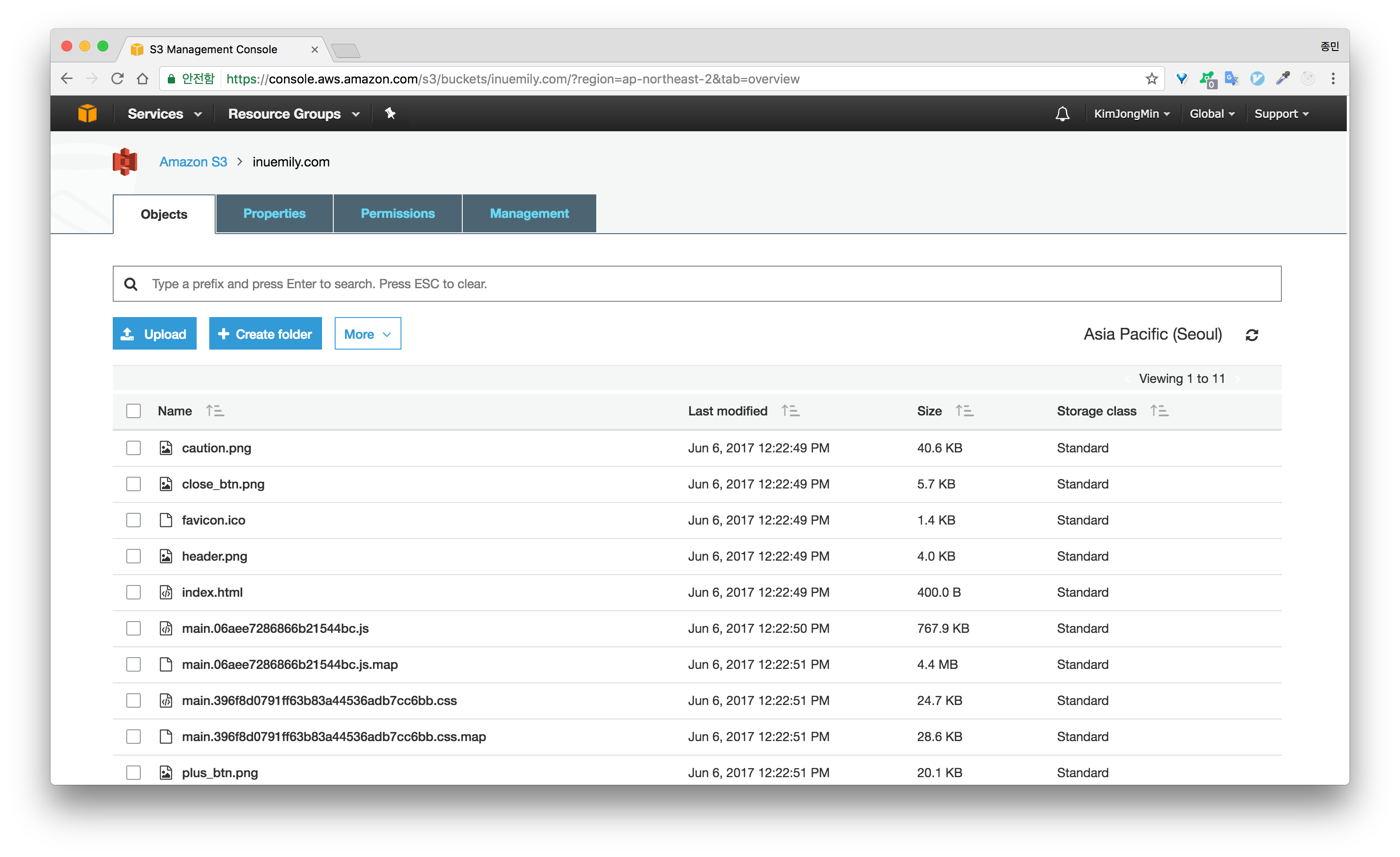
## 버킷 정책(Permissions) 설정
버킷을 생성하고 파일을 업로드했지만 모든 사용자가 버킷에 업로드한 모든 컨텐츠에 접근할 수 있도록 **버킷 정책(Permissions)**을 설정해야 합니다.
다음의 코드를 복사하여 아래 사진과 같이 버킷 정책을 설정합니다. (10번째 라인의 inuemily.com을 자신의 버킷 이름으로 변경해야 합니다.) 두 번째 버킷에는 파일을 업로드하지 않기 때문에 따로 정책을 설정해주지 않아도 됩니다.
1 | { |
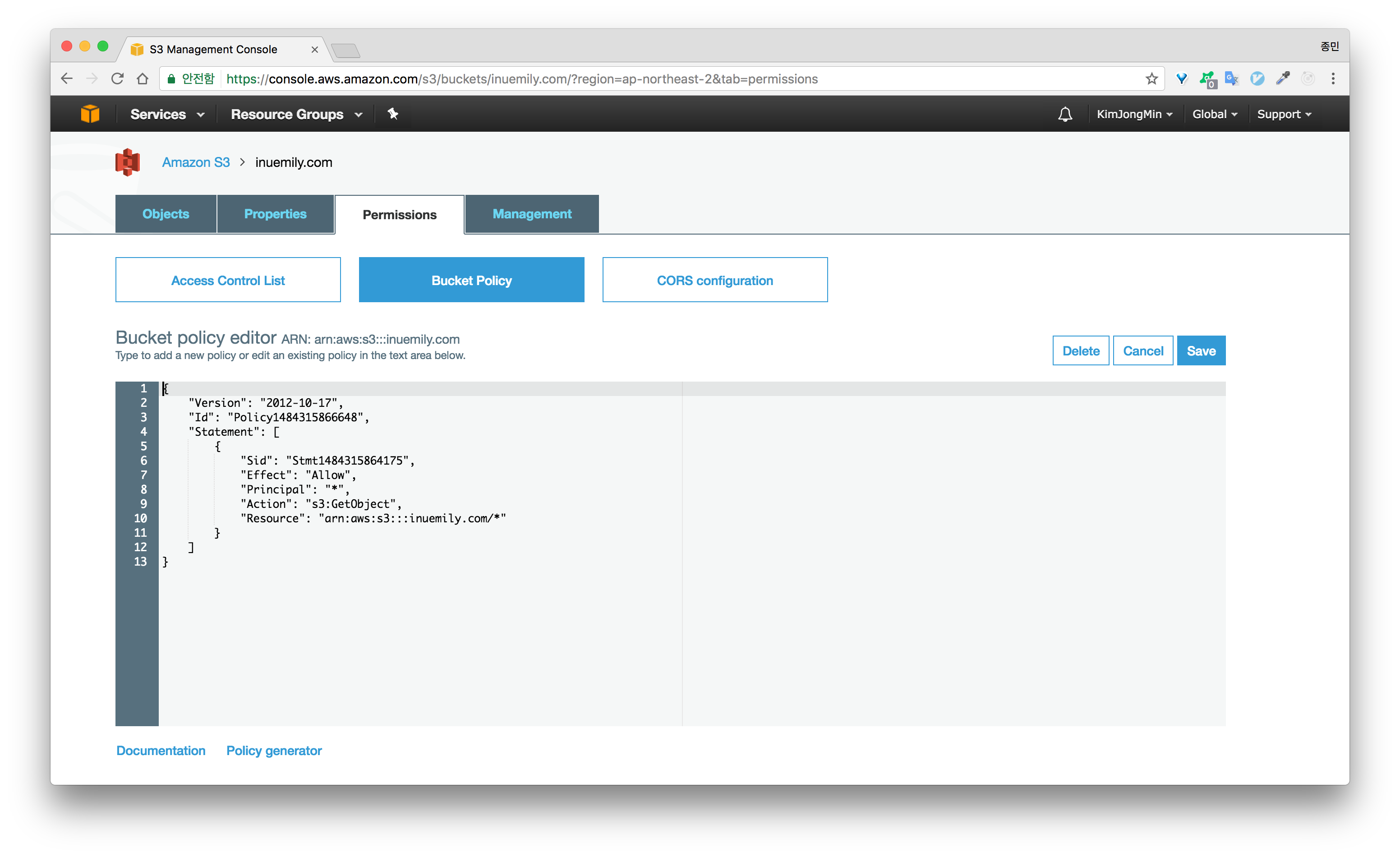
## 버킷 정적 웹 사이트 호스팅 기능 활성화
파일 업로드와 정책 설정이 끝난 버킷을 정적 웹 사이트 호스팅으로 사용할 수 있도록 기능을 활성화 해야합니다.
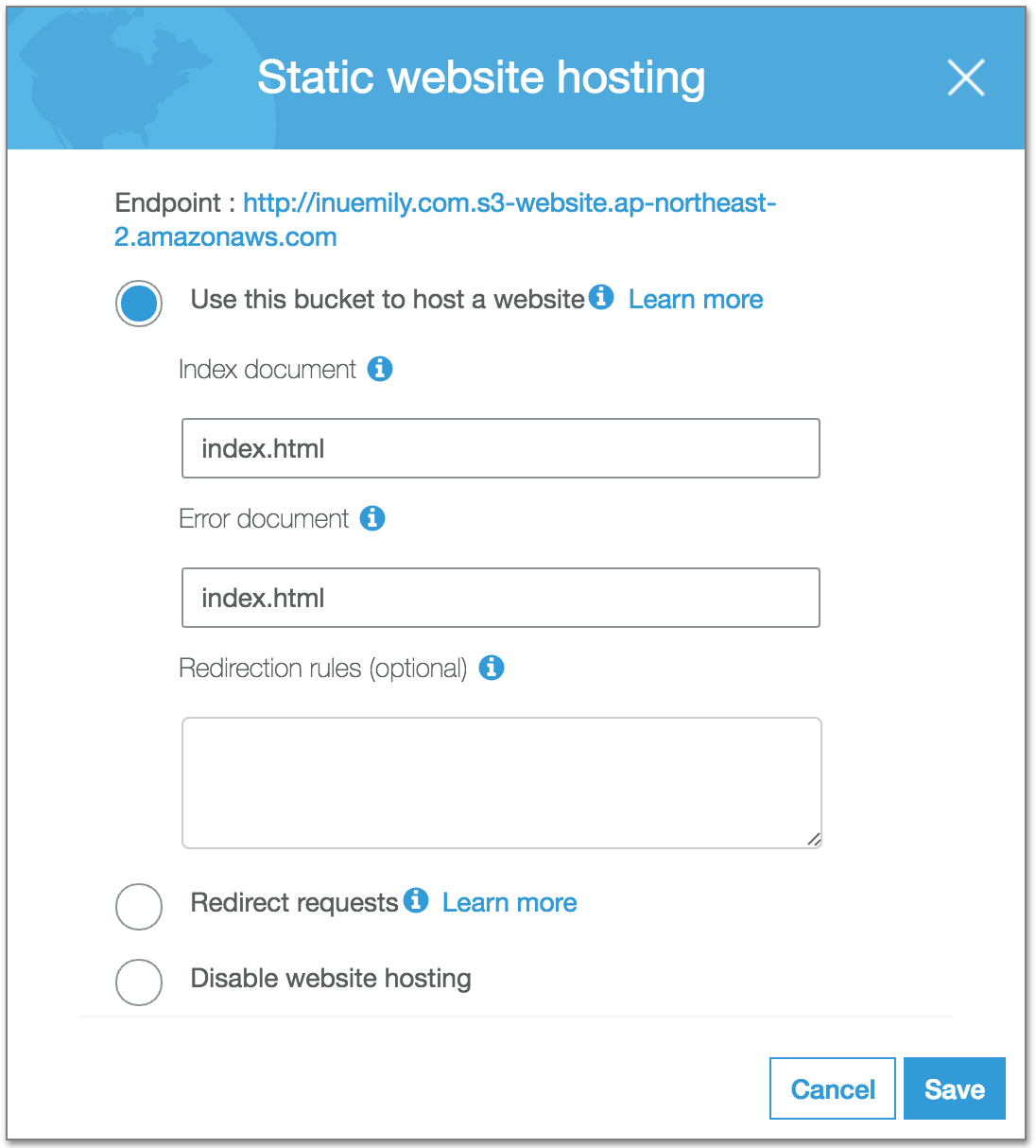
루트 버킷을 정적 웹 호스팅에 사용하기 때문에 User this bucket to host a website 에 체크를 하고, index document에는 자신이 작성한 웹 페이지의 index page의 파일명을 기재합니다. 저의 경우 좀 전에 버킷에 업로드한 파일을 보면 index.html이 있고, 이 파일이 index page의 파일이기 때문에 index.html을 기재했습니다.
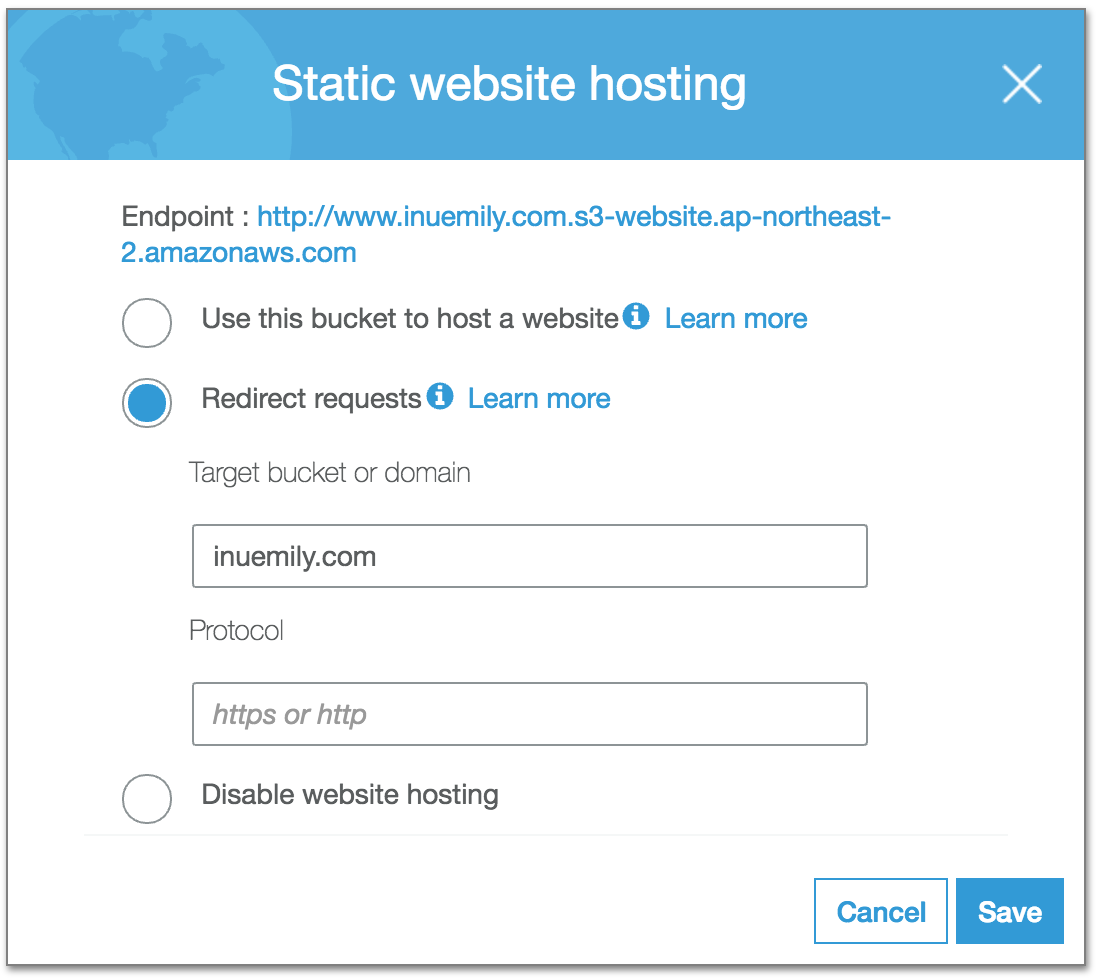
이번에는 두번째 버킷으로 들어오는 요청을 루트 버킷으로 redirection 할 수 있도록 설정을 합니다. 루트 버킷과는 달리 **Redirect requests**에 체크를 하고, Target bucket or domain에 루트 버킷의 이름을 기재합니다.
## 버킷 Record Set 설정
이제 마지막 단계입니다. 지금까지 생성하고 설정을 마친 S3 버킷을 Route 53을 사용해 연결합니다. 도메인에 따른 호스팅 영역과 추가하는 별칭 레코드는 IP 주소 대신 S3 웹 사이트 엔드포인트를 사용함으로써 Route 53은 별칭 레코드와 S3 버킷이 존재하는 IP 주소 간 매핑을 유지합니다.
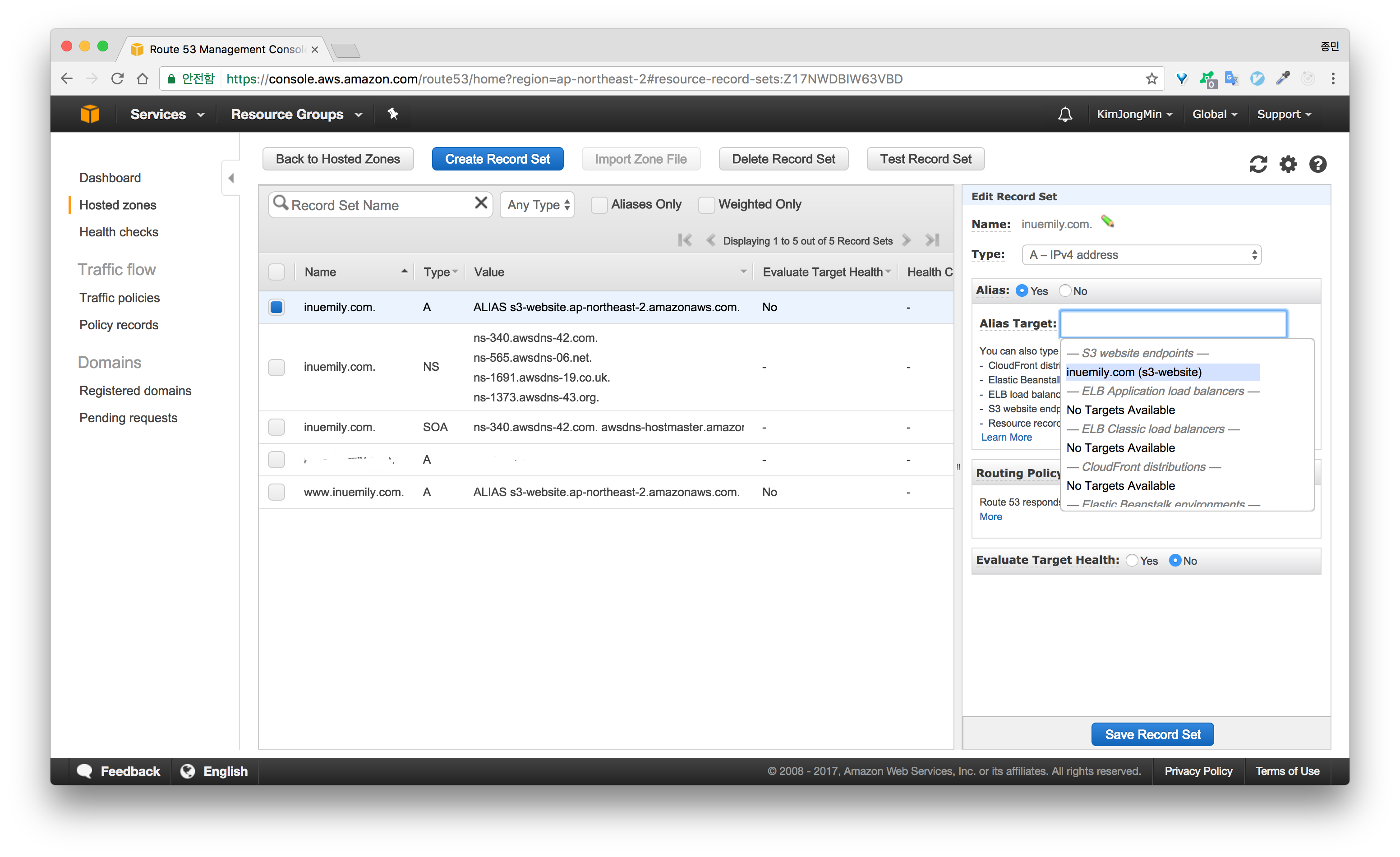
Route 53의 Record Set 까지 설정을 마치면 해당 루트 도메인과 서브 도메인을 통해서 사이트에 접속할 수 있습니다.