NoSuchMethodException & NoSuchMethodError 해결하기
애플리케이션에서 사용하는 라이브러리의 버전을 업데이트하거나 혹은 새로운 라이브러리를 추가하는 과정에서 종종 NoSuchMethodError을 마주하게 된다.
이번에는 NoSuchMethodErrors 대한 내용과 해결하는 방법에 대해서 알아보자.
애플리케이션에서 사용하는 라이브러리의 버전을 업데이트하거나 혹은 새로운 라이브러리를 추가하는 과정에서 종종 NoSuchMethodError을 마주하게 된다.
이번에는 NoSuchMethodErrors 대한 내용과 해결하는 방법에 대해서 알아보자.

Spring Boot를 사용하고 있는 애플리케이션에서 이전에 살펴본 Micrometer를 이용해서 metric을 생성하고 Prometheus를 이용해 수집, 그리고 Grafana로 시각화하는 시스템을 만들어보자.
micrometer.io에서는 Micrometer에 대해서 다음과 같이 소개하고 있다.
Micrometer provides a simple
facadeover the instrumentationclientsfor the most popularmonitoring systems, allowing you to instrument yourJVM-based applicationcode without vendor lock-in. ThinkSLF4J, but for metrics
Micrometer는 JVM 기반의 애플리케이션에서 다양한 모니터링 도구가 제공하는 클라이언트 라이브러리에 대한 facade를 제공한다. 로깅 관련된 시스템에서는 SLF4J가 있다면 모니터링(metric) 시스템에서는 Micrometer가 있는 것이다.
즉, 모니터링 시스템을 만드는 vendor들은 Micrometer 인터페이스를 따르기 때문에 Micrometer를 사용하면 애플리케이션 내의 코드 상에서는 모니터링 시스템 클라이언트로 어떤 것을 사용할지에 대한 고민에서 벗어나 Micrometer를 이용해 애플리케이션 metric을 수집하기만 하면 된다.
(모니터링 시스템을 선택하는 것은 런타임 시점에 정해진다고 생각하면 된다.)
해당 포스팅에서 사용된 예제 코드는 spring-boot validation example에서 확인 가능합니다.
Bean Validation은 Java 생태계에서 유효성(Validation) 검증 로직을 구현하기위한 사실상의 표준이다. Bean Validation은 Spring과 Spring Boot에도 잘 통합되어 있다.
최근 사내에서 Kafka 관련된 설정을 리팩토링하는 작업을 했습니다. SpringBoot를 도입하며 Kafka 설정 관련된 부분들을 SpringBoot의 @ConfigurationProperties를 이용하도록 변경하고, XML 기반의 빈 생성 부분을 Java Config 기반으로 변경했습니다.
현재 프로젝트에서는 여러가지 이유로 기존의 Kafka Producer를 확장(extends)해서 사용하고 있는데, 이번에 리팩토링 관련한 PR에서 확장해서 사용하고 있는 Kafka Producer에서 close 메서드를 구현하고 있는지 확인해달라는 리뷰를 받았습니다.
컨테이너에 등록된 Bean이 DisposableBean interface를 구현하고 있거나 @PreDestroy 어노테이션 또는 destroyMethod 속성을 사용하고 있다면 Bean의 Lifecycle 마지막에 자원을 해제하거나 필요한 작업을 수행할 수 있습니다. 그러나 위의 방법 말고도 Spring container에서 Bean을 제거 할 때, close() 와 shutdown() 메서드를 호출합니다.
Kafka Producer는 Closeable interface를 구현(implement)하고 있기 때문에 close 메서드를 포함하고 있습니다. Kafka Producer가 Bean으로 등록되어 있고 후에 소멸될 때 close 메서드가 호출되어 해당 자원이 모두 해제될 것입니다.
따라서 제가 받았던 리뷰는 기존 Kafka Producer를 확장한 것을 Bean으로 등록해 사용하고 있는데, 해당 확장 클래스가 close 메서드를 제대로 구현해 Bean이 소멸 될 때 호출될 close 메서드에서 자원이 제대로 해제하고 있는지 확인해 달라는 것이었습니다.
AutoCloseable 은 try-with-resource 구문과 함께 사용됩니다.
이번 리뷰를 통해 Bean의 LifeCycle과 close, shutdown 메서드에 대해 다시 살펴보는 계기가 되었습니다.
Initialize 메서드는 Bean Object가 생성되고 DI를 마친 후 실행되는 메서드입니다. 일반적으로 Object의 초기화 작업이 필요한 경우 생성자에서 처리하지만 DI를 통해 Bean이 주입된 후에 초기화할 작업이 있다면 초기화 메서드를 이용해서 초기화를 진행할 수 있습니다.
초기화 하고 싶은 메서드에 @PostConstruct 어노테이션을 붙여주면 Spring이 해당 메서드를 초기화시에 호출합니다. PostConstruct는 JSR-250 스펙에 포함되어 있기 때문에 JSR-250을 구현한 다른 프레임워크 혹은 라이브러리에서도 동작합니다. 다른 초기화 메서드에 비해 Spring에 의존적이지 않다는 장점이 있습니다.
JSR-250
JSR 250 is a Java Specification Request with the objective to develop annotations (that is, information about a software program that is not part of the program itself) for common semantic concepts in the Java SE and Java EE platforms that apply across a variety of individual technologies.
1 |
|
InitializingBean 인터페이스를 구현하면 Spring이 afterPropertiesSet 메서드를 초기화시에 호출합니다.
1 |
|
@Bean 어노테이션을 이용해 Bean을 생성할 때, @Bean 어노테이션의 initMethod 속성을 이용해 초기화 메서드를 지정할 수 있습니다.
1 |
|
Destroy 메서드는 스프링 컨테이너가 종료 될 때, 호출되어 Bean이 사용한 리소스들을 반환하거나 종료 시점에 처리해야할 작업이 있을 경우 사용합니다.
@PreDestroy 도 PostConstruct처럼 JSR-250 스펙에 포함되어 있기 때문에 JSR-250을 구현한 다른 프레임워크 혹은 라이브러리에서도 동작합니다. 컨테이너가 종료 될 때 실행하고 싶은 메서드에 어노테이션을 붙여주면 Spring이 컨테이너 종료 시 해당 메서드를 호출합니다.
1 |
|
DisposableBean 인터페이스를 구현하면 Spring이 destroy 메서드를 호출합니다.
1 | lf4j |
@Bean 어노테이션을 이용해 Bean을 생성할 때, @Bean 어노테이션의 destroyMethod 속성을 이용해 컨테이너 종료시 실행하고자 하는 메서드를 지정할 수 있습니다.
1 |
|
close와 shutdown 메서드는 DisposableBeanAdapter에 의해 실행됩니다.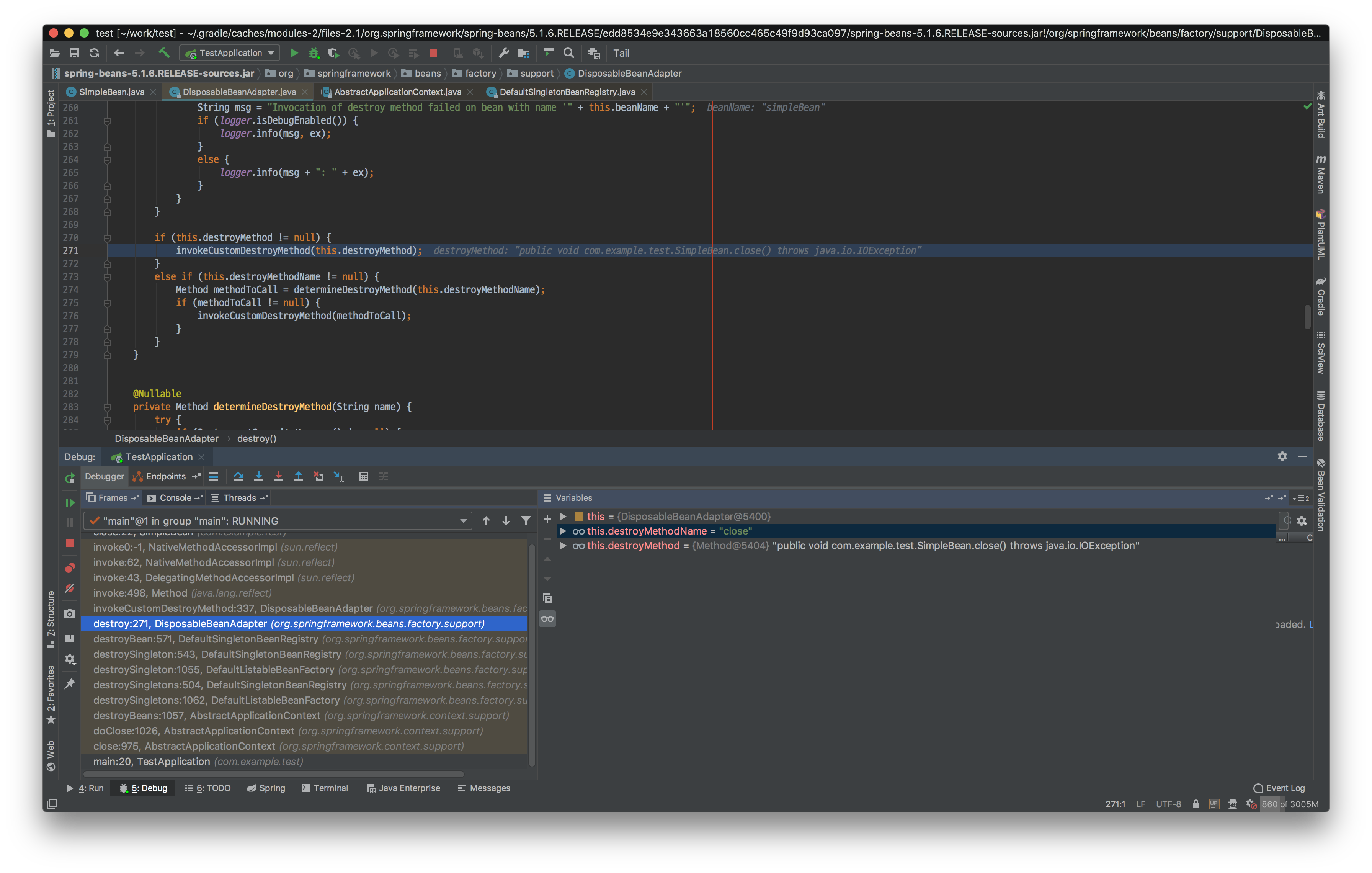
일반적으로 @Bean 어노테이션은 @Configuration 어노테이션이 사용된 클래스 내의 메서드에 선언이 됩니다. 이 경우 @Bean 어노테이션을 사용하는 메서드는 같은 클래스의 다른 @Bean 메소드를 직접 호출하여 참조할 수 있습니다. 이렇게하면 bean 간의 참조(reference)가 강하게 만들어집니다.
아래 코드의 실행 후 로그를 통해 a() 메서드의 결과로 생성되는 A 클래스의 빈은 b() 와 c() 메서드에서 a() 메서드를 직접 호출해 참조가 되는 것을 확인할 수 있습니다.
1 |
|
이러한 관계를 **빈 간의 참조(inter-bean references)**라 부릅니다. 이러한 빈 간의 참조는 @Configuration 클래스의 @Bean이 cglib wrapper에 의해 래핑되기 때문에 동작하게 됩니다.(@Bean 메서드에 대한 호출을 가로채고 Bean 인스턴스를 컨텍스트에서 반환하게 됩니다.)
처음 알게된 분도 계실 수 있을텐데요, @Bean 메소드는 @Configuration으로 주석을 달지 않은 클래스 내에서도 선언 될 수도 있습니다. 이런 경우, @Bean 메서드는 **lite mode**로 처리됩니다.
lite mode의 Bean 메서드는 스프링 컨테이너에 의해 일반 팩토리 메서드로 처리됩니다. 그렇기 때문에, lite mode에서는 빈 간의 참조가 지원되지 않습니다.
1 |
|
스프링이란 어떤 것이다라고 한마디로 정의하기는 쉽지 않다. 스프링에 대해 가장 잘 알려진 정의는 이렇다.
자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경량급 애플리케이션 프레임워크
정의를 봐도 스프링이 무엇인지 감이 바로 오지는 않는다. 하지만 이 정의에는 스프링의 중요한 특징이 잘 담겨 있다.
애플리케이션 프레임워크
일반적으로 라이브러리나 프레임워크는 특정 업무 분야나 한 가지 기술에 특화된 목표를 가지고 만들어진다. 그러나 애플리케이션 프레임워크는 조금 다르다.
애플리케이션 프레임워크는 특정 계층이나, 기술, 업무 분야에 국한되지 않고 애플리케이션의 전 영역을 포괄하는 범용적인 프레임워크를 말한다. 애플리케이션 프레임워크는 애플리케이션 개발의 전 과정을 빠르고 편리하며 효율적으로 진행하는데 일차적인 목표를 두는 프레임워크다.
단지 여러 계층의 다양한 기술을 한데 모아뒀기 때문에 애플리케이션 프레임워크라고 불리는 건 아니다. 애플리케이션의 전 영역을 관통하는 일관된 프로그래밍 모델과 핵심 기술을 바탕으로 해서 각 분야의 특성에 맞는 필요를 채워주고 있기 때문이다.
경량급
스프링이 경량급이라는 건 스프링 자체가 아주 가볍다거나 작은 규모의 코드로 이뤄졌다는 뜻은 아니다.
그럼에도 가볍다고 하는 이유는 불필요하게 무겁지 않다는 의미다. 특히 스프링이 처음 등장하던 시절의 자바 주류 기술이었던 예전의 EJB 같은 과도한 엔지니어링이 적용된 기술과 스프링을 대비시켜 설명하려고 사용했던 표현이다.
스프링은 가장 단순한 서버환경인 톰캣(Tomcat)이나 제티(Jetty)에서도 완벽하게 동작한다. 단순한 개발툴과 기본적인 개발환경으로도 엔터프라이즈 개발에서 필요로 하는 주요한 기능을 갖춘 애플리케이션을 개발하기에 충분하다. 스프링의 장점은 그런 가볍고 단순한 환경에서도 복잡한 EJB와 고가의 WAS를 갖춰야만 가능했던 엔터프라이즈 개발의 고급 기술을 대부분 사용할 수 있다는 점이다.
결과적으로 스프링은 EJB를 대표로 하는 기존의 많은 기술이 불필요하게 무겁고 복잡했음을 증명한 셈이고, 그런 면에서 스프링은 군더더기 없이 깔끔한 기술을 가진 ‘경량급’ 프레임워크라고 불린 것이다.
만들어진 코드가 지원하는 기술수준은 비슷하더라도 그것을 훨씬 빠르고 간편하게 작성하게 해줌으로써 생산성과 품질 면에서 유리하다는 것이 바로 경량급이라는 말로 표현되는 스프링의 특징이다.
자바 엔터프라이즈 개발을 편하게
스프링은 근본적인 부분에서 엔터프라이즈 개발의 복잡함을 제거해내고 진정으로 개발을 편하게 해주는 해결책을 제시한다. 단순히 편리한 몇 가지 도구나 기능을 제공해주는 차원이 아니다.
편리한 애플리케이션 개발이란 개발자가 복잡하고 실수하기 쉬운 로우레벨 기술에 많은 신경을 쓰지 않으면서도 애플리케이션의 핵심인 사용자의 요구사항, 즉 비즈니스 로직을 빠르고 효과적으로 구현하는 것을 말한다.
오픈소스
스프링을 사용해서 엔터프라이즈 애플리케이션 개발을 편하게 하려는 이유는 뭘까? 원래 엔터프라이즈 개발이란 편하지 않기 때문이다.
자바 엔터프라이즈(JavaEE) 개발이 실패하는 가장 대표적인 이유는 ‘엔터프라이즈 시스템 개발이 너무 복잡해져서’였다.
엔터프라이즈 시스템 개발이 복잡한 원인은 크게 두 가지가 있다. (엔터프라이즈 시스템이란 서버에서 동작하며 기업과 조직의 업무를 처리해주는 시스템을 말한다.)
전통적인 자바 엔터프라이즈 개발 기법은 대부분 비즈니스 로직의 복잡한 구현 코드와 엔터프라이즈 서비스를 이용하는 기술적인 코드가 자꾸 혼재될 수 밖에 없는 방식이었다. 결국 개발자가 동시에 그 두 가지를 모두 신경 써서 개발해야 하는 과도한 부담을 줬고, 그에 따라 전체적인 복잡함은 몇 배로 가중됐다.
엔터프라이즈 개발의 근본적인 복잡함의 원인은 제거할 대상은 아니다. 현실적으로는 불가능하기 때문이다.
근본적으로 엔터프라이즈 개발에 나타나는 복잡함의 원인은 제거 대상이 아니다. 대신 그 복잡함을 효과적으로 상대할 수 있는 전략과 기법이 필요하다. 문제는 비즈니스 로직의 복잡함을 효과적으로 다루기 위한 방법과 기술적인 복잡함을 효과적으로 처리하는 데 적용되는 방법이 다르다는 점이다. 따라서 두 가지 복잡함이 코드에 한데 어우러져 나타나는 전통적인 개발 방식에서는 효과적으로 복잡함을 다루기가 힘들다. 따라서 가장 먼저 할 일은 성격이 다른 이 두 가지 복잡함을 분리해내는 것이다.
스프링의 기본적인 전략은 비즈니스 로직을 담은 애플리케이션 코드와 엔터프라이즈 기술을 처리하는 코드를 분리시키는 것이다. 이 분리를 통해 두 가지 복잡함의 문제를 효과적으로 공략하게 해준다.
기술적인 복잡함을 분리해서 생각하면 그것을 효과적으로 상대할 수 있는 적절한 전략을 발견할 수 있다. 스프링은 엔터프라이즈 기술을 적용했을 때 발생하는 복잡함의 문제를 두 가지로 분류하고 각각에 대한 적절한 대응 방법을 제공한다.
첫 번째 문제 : 기술에 대한 접근 방식이 일관성이 없고, 특정 환경에 종속적이다.
일관성 없는 기술과 서버환경의 변화에 대한 스프링의 공략 방법은 바로 서비스 추상화다. 앞에서 보았던 트랜잭션 추상화, OXM 추상화, 데이터 액세스에 관한 일관된 예외변환 기능, 데이터 액세스 기술에 독립적으로 적용 가능한 트랜잭션 동기화 기법 등이 대포적인 예다. 기술적인 복잡합은 일단 추상화를 통해 로우레벨의 기술 구현 부분과 기술을 사용하는 인터페이스를 분리하고, 환경과 세부기술에 독립적인 접근 인터페이스를 제공하는 것이 가장 좋은 해결책이다.
두 번째 문제 : 기술적인 처리를 담당하는 코드가 성격이 다른 코드에 섞여서 등장한다.
책임에 따라 계층을 구분하고 그 사이에 서로의 기술과 특성에 의존적인 인터페이스나 예외처리 등을 최대한 제거한다고 할지라도 근본적으로 엔터프라이즈 서비스를 적용하는 한 이런 문제는 쉽게 해결할 수 없다. 이런 기술과 비즈니스 로직의 혼재로 발생하는 복잡함을 해결하기 위한 스프링의 접근 방법은 바로 AOP다.
AOP는 최후까지 애플리케이션 로직을 담당하는 코드에 남아 있는 기술 관련 코드를 깔끔하게 분리해서 별도의 모듈로 관리하게 해주는 강력한 기술이다.
비즈니스 로직의 복잡함을 상대하는 전략은 자바라는 객체지향 기술 그 자체다. 스프링은 단지 객체지향 언어의 장점을 제대로 살리지 못하게 방해했던 요소를 제거하도록 도와줄 뿐이다.
객체지향의 설계 기법을 잘 적용할 수 있는 구조를 만들기 위해 DI 같은 유용한 기술을 편하게 적용하도록 도와주는 것이 스프링의 기본 전략이다.
지금까지 보았듯이 기술적인 복잡함을 효과적으로 다루게 해주는 기법은 모두 DI를 바탕으로 하고 있다. 서비스 추상화, 템플릿/콜백, AOP와 같은 스프링의 기술은 DI 없이는 존재할 수 없는 것들이다.
그리고 DI는 객체지향 설계 기술 없이는 그 존재의미가 없다. DI란 특별한 기술이라기보다는 유연하게 확장할 수 있는 오브젝트 설계를 하다 보면 자연스럽게 적용하게 되는 객체지향 프로그래밍 기법일 뿐이다. 스프링은 단지 그것을 더욱 편하고 쉽게 사용하도록 도와줄 뿐이다.
기술적인 복잡함을 해결하는 문제나 기술적인 복잡함이 비즈니스 로직에 침범하지 못하도록 분리하는 경우에도 DI가 바탕이 된 여러 가지 기법이 활용된다. 반면에 비즈니스 로직 자체의 복잡함을 해결하려면 DI보다는 객체지향 설계 기법이 더 중요하다.
스프링 핵심 개발자들은 “스프링의 정수(essence)”는 엔터프라이즈 서비스 기능을 POJO에 제공하는 것”이라고 했다. 엔터프라이즈 서비스라고 하는 것은 보안, 트랜잭션과 같은 엔터프라이즈 시스템에서 요구되는 기술을 말한다. 이런 기술을 POJO에 제공한다는 말은, 뒤집어 생각해보면 엔터프라이즈 서비스 기술과 POJO라는 애플리케이션 로직을 담은 코드를 분리했다는 뜻이기도 하다. ‘분리됐지만 반드시 필요한 엔터프라이즈 서비스 기술을 POJO 방식으로 개발된 애플리케이션 핵심 로직을 담은 코드에 제공한다’는 것이 스프링의 가장 강력한 특징과 목표다.
스프링 애플리케이션은 POJO를 이용해서 만든 애플리케이션 코드와, POJO가 어떻게 관계를 맺고 동작하는지를 정의해놓은 설계정보로 구분된다. DI의 기본 아이디어는 유연하게 확장 가능한 오브젝트를 만들어두고 그 관계는 외부에서 다이내믹하게 설정해준다는 것이다. 이런 DI의 개념을 애플리케이션 전반에 걸쳐 적용하는 것이 스프링의 프로그래밍 모델이다.
스프링의 주요 기술인 IoC/DI, AOP, 서비스추상화는 애플리케이션을 POJO로 개발할 수 있게 해주는 가능기술이라고 불린다.
POJO는 Plain Old Java Object의 첫 글자를 따서 만든 약자다.
단순하게 보자면 그냥 평범한 자바오브젝트라고 할 수 있지만 좀 더 명확하게 하자면 적어도 다음의 조건을 충족해야 POJO라고 불릴 수 있다.
특정 규약에 종속되지 않는다.
POJO는 자바 언어와 꼭 필요한 API 외에는 종속되지 않아야 한다. 따라서 EJB2와 같이 특정 규약을 따라 비즈니스 컴포넌트를 만들어야 하는 경우는 POJO가 아니다. 특정 규약을 따라 만들게 하는 경우는 대부분 규약에서 제시하는 특정 클래스를 상속하도록 요구한다. 그럴 경우 자바의 단일 상속 제한 때문에 더 이상 해당 클래스에 객체지향적인 설계 기법을 적용하기가 어려워지는 문제가 생긴다. 또한 규약이 적용된 환경에 종속적이 되기 때문에 다른 환경으로 이전이 힘들다는 문제점이 있다.
특정 환경에 종속되지 않는다.
어떤 경우는 특정 벤더의 서버나 특정 기업의 프레임워크 안에서만 동작 가능한 코드로 작성되기도 한다. 또 환경에 종속적인 클래스나 API를 직접 쓴 경우도 있다. 순수한 애플리케이션 로직을 담고 있는 오브젝트 코드가 특정 환경에 종속되게 만드는 경우라면 그것 역시 POJO라고 할 수 없다. POJO는 환경에 독립적이어야한다.
특히 비즈니스 로직을 담고 있는 POJO 클래스는 웹이라는 환경정보나 웹 기술을 담고 있는 클래스나 인터페이스를 사용해서는 안된다. 비즈니스 로직을 담은 코드에 HttpServletRequest나 HttpSession, 캐시와 관련된 API가 등장하거나 웹 프레임워크의 클래스를 직접 이용하는 부분이 있다면 그것은 진정한 POJO라고 볼 수 없다.
단지 자바의 문법을 지키고, 순수하게 JavaSE API만을 사용했다고 해서 그 코드를 POJO라고 할 수는 없다. POJO는 객체지향적인 자바 언어의 기본에 충실하게 만들어져야 하기 때문이다.
POJO가 될 수 있는 조건이 그대로 POJO의 장점이 된다.
특정한 기술과 환경에 종속되지 않는 오브젝트는 그만큼 깔끔한 코드가 될 수 있다. 로우레벨의 기술과 환경에 종속적인 코드가 비즈니스 로직과 함께 섞여 나오는 것만큼 지저분하고 복잡한 코드도 없다.
POJO로 개발된 코드는 자동화된 테스트에 매우 유리하다. 환경의 제약은 코드의 자동화된 테스트를 어렵게 한다. 컨테이너에서만 동작을 확인할 수 있는 EJB 2는 테스트하려면 서버의 구동 및 빌드와 배치 과정까지 필요하다. 자동화된 테스트가 불가능한 건 아니지만 매우 복잡하고 번거로우므로 대부분 수동 테스트 방식을 선호한다. 그에 반해 어떤 환경에도 종속되지 않은 POJO 코드는 매우 유연한 방식으로 원하는 레벨에서 코드를 빠르고 명확하게 테스트할 수 있다.
객체지향적인 설계를 자유롭게 적용할 수 있다는 것도 큰 장점이다.
스프링은 POJO를 이용한 엔터프라이즈 애플리케이션 개발을 목적으로 하는 프레임워크이다. POJO 프로그래밍이 가능하도록 기술적인 기반을 제공하는 프레임워크를 POJO 프레임워크라고 한다. 스프링은 엔터프라이즈 애플리케이션 개발의 모든 영역과 계층에서 POJO 방식의 구현이 가능하게 하려는 목적으로 만들어졌다.
스프링을 이용하면 POJO 프로그래밍의 장점을 그대로 살려서 엔터프라이즈 애플리케이션의 핵심 로직을 객체지향적인 POJO를 기반으로 깔끔하게 구현하고, 동시에 엔터프라이즈 환경의 각종 서비스와 기술적인 필요를 POJO 방식으로 만들어진 코드에 적용할 수 있다.
스프링은 비즈니스 로직의 복잡함과 엔터프라이즈 기술의 복잡함을 분리해서 구성할 수 있게 도와준다. 하지만 자신은 기술영역에만 관여하지 비즈니스 로직을 담당하는 POJO에서는 모습을 감춘다. 데이터 액세스 로직이나 웹 UI 로직을 다룰 때만 최소한의 방법으로 관여한다. POJO 프레임워크로서 스프링은 자신을 직접 노출하지 않으면서 애플리케이션을 POJO로 쉽게 개발할 수 있게 지원해준다.
왜 두 개의 오브젝트를 분리해서 만들고, 인터페이스를 두고 느슨하게 연결한 뒤, 실제 사용할 대상은 DI를 통해 외부에서 지정하는 것일까? 직접 자신이 사용할 오브젝트를 new 키워드로 생성해서 사용하는 강한 결합을 쓰는 방법보다 나은 점은 무엇일까?
가장 간단한 답변은 **’유연한 확징이 가능하게 하기 위함’**이다. DI는 개방 폐쇄 원칙(OCP)이라는 객체지향 설계 원칙으로 잘 설명될 수 있다. 유연한 확장이라는 장점은 OCP의 ‘확장에는 열려 있다(개방)’에 해당한다. DI는 역시 OCP의 ‘변경에는 닫혀 있다(폐쇄)’라는 말로도 설명이 가능하다. 폐쇄 관점에서 볼 때 장점은 ‘재사용이 가능하다’라고 볼 수 있다.
핵심기능의 변경
DI의 가장 대표적인 적용 방법은 바로 의존 대상의 구현을 바꾸는 것이다. 디자인 패턴의 전략 패턴이 대표적인 예다. 실제 의존하는 대상이 가진 핵심기능을 DI 설정을 통해 변경하는 것이 대표적인 DI의 활용 방법이다.
핵심기능의 동적인 변경
두 번째 활용 방법은 첫 번째랑 비슷하게 의존 오브젝트의 핵심 기능 자체를 바꾸는 것이다. DI도 기본적으로는 런타임 시에 동적으로 의존 오브젝트를 연결해주는 것이긴 하지만, 일단 DI 되고 나면 그 후로는 바뀌지 않는다. 즉 동적인 방식으로 연결되지만 한 번 DI되면 바뀌지 않는 정적인 관계를 맺어주는 것이다. 하지만 DI를 잘 활용하면 애플리케이션이 동작하는 중간에 그 의존 대상을 다이내믹하게 변경할 수 있다.
부가기능의 추가
세 번째 활용 방법은 핵심기능은 그대로 둔 채로 부가기능을 추가하는 것이다. 데코레이터 패턴을 생각해보면 된다. 인터페이스를 두고 사용하게 하고, 실제 사용할 오브젝트는 외부에서 주입하는 DI를 적용해두면 데코레이터 패턴을 쉽게 적용할 수 있다. 그래서 핵심기능과 클라이언트 코드에는 전혀 영향을 주지 않으면서 부가적인 기능을 얼마든지 추가할 수 있다.
인터페이스의 변경
사용하려고 하는 오브젝트가 가진 인터페이스가 클라이언트와 호환되지 않는 경우가 있다. 이렇게 클라이언트가 사용하는 인터페이스와 실제 오브젝트 사이에 인터페이스가 일치하지 않는 경우에도 DI가 유용하다. 디자인 패턴에서 말하는 오브젝트 방식의 어댑터 패턴의 응용이라고 볼 수 있다.
이를 좀 더 일반화해서 아예 인터페이스가 다른 다양한 구현을 같은 방식으로 사용하도록, 중간에 인터페이스 어댑터 역할을 해주는 레이어를 하나 추가하는 방법도 있다. 서비스 추상화(PSA)가 그런 방법이다. PSA는 클라이언트가 일관성 있게 사용할 수 있는 인터페이스를 정의해주고 DI를 통해 어댑터 역할을 하는 오브젝트를 이용하게 해준다. 이를 통해 다른 인터페이스를 가진 로우레벨의 기술을 변경하거나 확장해가면서 사용할 수 있는 것이다.
프록시
필요한 시점에서 실제 사용할 오브젝트를 초기화하고 리소스를 준비하게 해주는 지연된 로딩(lazy loading)을 적용하려면 프록시가 필요하다. 원격 오브젝트를 호출할 때 마치 로컬에 존재하는 오브젝트처럼 사용할 수 있게 해주는 원격 프록시를 적용하려고 할 때도 프록시가 필요하다. 두 가지 방법 모두 DI를 필요로 한다.
템플릿과 콜백
템플릿/콜백 패턴은 DI의 특별한 적용 방법이다. 반복적으로 등장하지만 항상 고정적인 작업 흐름과 그 사이에서 자주 바뀌는 부분을 분리해서 템플릿과 콜백으로 만들 고 이를 DI 원리를 응용해 적용하면 지저분하게 매번 만들어야 하는 코드를 간결하게 만들 수 있다.
싱글톤과 오브젝트 스코프
DI가 필요한 중요한 이유 중 한 가지는 DI 할 오브젝트의 생명주기를 제어할 수 있다는 것이다. DI를 프레임워크로 이용한다는 건 DI 대상 오브젝트를 컨테이너가 관리한다는 의미다. 오브젝트의 생성부터 관계 설정, 이용, 소멸에 이르기까지의 모든 과정을 DI 컨테이너가 주관하기 때문에 그 오브젝트의 스코프를 자유롭게 제어할 수 있다.
스프링의 DI는 기본적으로 싱글톤으로 오브젝트를 만들어서 사용하게 한다. 컨테이너가 알아서 싱글톤으로 만들고 관리하기 때문에 클래스 자체는 싱글톤을 고려하지 않고 자유롭게 설계해도 된다는 장점이 있다.
테스트
다른 오브젝트와 협력해서 동작하는 오브젝트를 효과적으로 테스트하는 방법은 가능한 한 고립시키는 것이다. 즉 다른 오브젝트와의 사이에서 일어나는 일을 테스트를 위해 조작할 수 있도록 만든다. 그래야만 테스트 대상인 오브젝트의 기능에 충실하게 테스트가 가능하다. 복잡한 테스트할 대상에 의존하는 오브젝트를, 테스트를 목적으로 만들어진 목 오브젝트로 대체하면 유용하다.
AOP도 스프링의 3개 기술중의 하나다. 사실 애스펙트 지향 프로그래밍은 객체지향 프로그래밍(OOP)처럼 독립적인 프로그래밍 패러다임이 아니다. AOP와 OOP는 서로 배타적이 아니라는 말이다.
객체지향 기술은 매우 성공적은 프로그래밍 방식임에 분명하다. 하지만 한편으로는 복잡해져 가는 애플리케이션의 요구조건과 기술적인 난해함을 모두 해결하는데 한계가 있기도 하다. AOP는 바로 이러한 객체지향 기술의 한계와 단점을 극복하도록 도와주는 보조적인 프로그래밍 기술이다.
IOC/DI를 이용해서 POJO에 선언적인 엔터프라이즈 서비스를 제공할 수 있지만 일부 서비스는 순수한 객체지향 기법만으로는 POJO의 조건을 유지한 채로 적용하기 힘들다. 바로 이런 문제를 해결하기 위해 AOP가 필요하다.
AOP를 자바 언어에 적용하는 기법은 크게 두 가지로 분류할 수 있다.
스프링과 같이 다이내믹 프록시를 사용하는 방법
이 방법은 기존 코드에 영향을 주지 않고 부가기능을 적용하게 해주는 데코레이터 패턴을 응용한 것이다. 만들기 쉽고 적용하기 간편하지만 부가기능을 부여할 수 있는 곳은 메소드의 호출이 일어나는 지점뿐이라는 제약이 있다. 인터페이스와 DI를 활용하는 데코레이터 패턴이 기반원리이기 때문이다.
자바 언어의 한계를 넘어서는 언어의 확장을 이용하는 방법
AspectJ라는 유명한 오픈소스 AOP 툴이 있다. AspectJ는 프록시 방식의 AOP에서는 불가능한 다양한 조인포인트를 제공한다. 메소드 호출뿐 아니라 인스턴스 생성, 필드 액세스, 특정 호출 경로를 가진 메소드 호출 등에도 부가기능을 제공할 수 있다. 이런 고급 AOP 기능을 적용하려면 자바 언어와 JDK의 지원만으로는 불가능하다. 그 대신 별도의 AOP 컴파일러를 이용한 빌드 과정을 거치거나, 클래스가 메모리로 로딩될 때 그 바이트 코드를 조작하는 위빙과 같은 별도의 방법을 이용해야 한다.
세 번째 기능기술은 환경과 세부 기술의 변화에 관계없이 일관된 방식으로 기술에 접근 할 수 있게 해주는 PSA(Portable Service Abstraction)다. POJO로 개발된 코드는 특정 환경이나 구현 방식에 종속적이지 않아야 한다. 스프링은 JavaEE를 기존 플랫폼으로 하는 자바 엔터프라이즈 개발에 주로 사용된다. 따라서 다양한 JavaEE 기술에 의존적일 수밖에 없다 .특정 환경과 기술에 종속적이지 않다는 게 그런 기술을 사용하지 않는다는 뜻은 아니다. 다만 POJO 코드가 그런 기술에 직접 노출되어 만들어지지 않는다는 말이다. 이를 위해 스프링이 제공하는 대표적인 기술이 바로 일관성 있는 서비스 추상화 기술이다.
AOP는 IoC/DI, 서비스 추상화와 더불어 스프링의 3대 기반기술중 하나다.
AOP를 바르게 이용하려면 OOP를 대체하려고 하는 것처럼 보이는 AOP라는 이름 뒤에 감춰진, 그 필연적인 등장배경과 스프링이 그것을 도입한 이유, 그 적용을 통해 얻을 수 있는 장점이 무엇인지에 대한 충분한 이해가 필요하다.
스프링에 적용된 가장 인기 있는 AOP의 적용 대상은 바로 선언적 트랜잭션 기능이다. 서비스 추상화를 통해 많은 근본적인 문제를 해결했던 트랜잭션 경계설정 기능을 AOP를 이용해 더욱 세련되고 깔끔한 방식으로 바꿔보자.
1 | public void upgradeLevels() throws Exception { |
얼핏 보면 트랜잭션 경계설정 코드와 비즈니스 로직 코드가 복잡하게 얽혀 있는듯이 보이지만, 자세히 살펴보면 뚜렷하게 두 가지 종류의 코드가 구분되어 있음을 알 수 있다. 비즈니스 로직 코드를 사이에 두고 트랜잭션 시작과 종료를 담당하는 코드가 앞뒤에 위치하고 있다.
또, 이 코드의 특징은 트랜잭션 경계설정의 코드와 비즈니스 로직 코드 간에 서로 주고받는 정보가 없다는 점이다. 다만 이 비즈니스 로직을 담당하는 코드가 트랜잭션의 시작과 종료 작업 사이에서 수행돼야 한다는 사항만 지켜지면 된다.
지금 UserService는 UserServiceTest가 클라이언트가 되어서 사용하고 있다. 현재 구조는 UserService 클래스와 그 사용 클라이언트 간의 관계가 강한 결합도로 고정되어 있다. 그래서 UserService를 인터페이스로 만들고 기존 코드는 UserService 인터페이스의 구현 클래스를 만들어넣도록 한다. 그러면 클라이언트와 결합이 약해지고, 직접 구현 클래스에 의존하고 있지 않기 때문에 유연한 확장이 가능해진다.
그런데 보통 이렇게 인터페이스를 이용해 구현 클래스를 클라이언트에 노출하지 않고 런타임 시에 DI를 통해 적용하는 방법을 쓰는 이유는, 일반적으로 구현 클래스를 바꿔가면서 사용하기 위해서다.
하지만 꼭 그래야 한다는 제약은 없다. 지금 해결하려고 하는 문제는 UserService에는 순수하게 비즈니스 로직을 담고 있는 코드만 두고 트랜잭션 경계설정을 담당하는 코드를 외부로 빼내려는 것이다.
그래서 다음과 같은 구조를 생각해볼 수 있다. UserService를 구현한 또 다른 구현 클래스를 만든다. 이 클래스는 사용자 관리 로직을 담고 있는 구현 클래스인 UserServiceImpl을 대신하기 위해 만든 게 아니다. 단지 트랜잭션의 경계설정이라는 책임을 맡고 있을 뿐이다. 그리고 스스로는 비즈니스 로직을 담고 있지 않기 때문에 또 다른 비즈니스 로직을 담고 있는 UserService의 구현 클래스에 실제적인 로직 처리 작업은 위임하는 것이다.
먼저 기존의 UserService 클래스를 UserServiceImpl로 이름을 변경한다. 그리고 클라이언트가 사용할 로직을 담은 핵심 메소드만 UserService 인터페이스로 만든 후 UserServiceImpl이 구현하도록 만든다.
UserService 인터페이스의 구현 클래스인 UserServiceImpl은 기존 UserService 클래스의 내용을 대부분 그대로 유지하면 된다. 단, 트랜잭션 관련된 코드는 독립시키기로 했으니 모두 제거한다.
1 | public class UserServiceImpl implements userService { |
비즈니스 트랜잭션 처리를 담은 UserServiceTx를 만들어보자. UserServiceTx는 기본적으로 UserService를 구현하게 만든다. 그리고 같은 인터페이스를 구현한 다른 오브젝트에게 고스란히 작업을 위임하게 만들면 된다.
1 | public class UserServiceTx implements UserService { |
UserServiceTx는 UserService 인터페이스를 구현했으니, 클라이언트에 대해 UserService 타입 오브젝트의 하나로서 행세할 수 있다. UserServiceTx는 사용자 관리라는 비즈니스 로직을 전혀 갖지 않고 고스란히 다른 UserService 구현 오브젝트에 기능을 위임한다. 이렇게 준비된 UserServiceTx에 트랜잭션의 경계설정이라는 부가적인 작업을 부여해보자.
1 | public class UserServiceTx implements UserService { |
클라이언트가 UserService라는 인터페이스를 통해 사용자 관리 로직을 이용하려고 할 때 먼저 트랜잭션을 담당하는 오브젝트가 사용돼서 트랜잭션에 관련된 작업을 진행해주고, 실제 사용자 관리 로직을 담은 오브젝트가 이후에 호출돼서 비즈니스 로직에 관련된 작업을 수행하도록 만든다.
가장 편하고 좋은 테스트 방법은 가능한 한 작은 단위로 쪼개서 테스트하는 것이다.
하지만 현재 UserService는 UserDao, TransactionManager, MailSender라는 세 가지 의존관계를 갖고 있다. 따라서 그 세 가지 의존관계를 갖는 오브젝트들이 테스트가 진행되는 동안에 같이 실행된다. UserService라는 테스트 대상이 테스트 단위인 것처럼 보이지만 사실은 그 뒤에 의존관계를 따라 등장하는 오브젝트와 서비스, 환경 등이 모두 합쳐져 테스트 대상이 되는 것이다.
그래서 테스트의 대상이 환경이나, 외부 서버, 다른 클래스의 코드에 종속되고 영향을 받지 않도록 고립시킬 필요가 있다. 테스트를 의존 대상으로부터 분리해서 고립시키는 방법은 테스트를 위한 대역을 사용하는 것이다.
의존 오브젝트나 외부 서비스에 의존하지 않는 고립된 테스트 방식으로 만든 UserServiceImpl은 아무리 그 기능이 수행돼도 그 결과가 DB 등을 통해서 남지 않으니, 기존의 방법으로는 작업 결과를 검증하기 힘들다. upgradeLevels()처럼 결과가 리턴되지 않는 경우는 더더욱 그렇다.
그래서 이럴 땐 테스트 대상인 UserServiceImpl과 그 협력 오브젝트인 UserDao에게 어떤 요청을 했는지를 확인하는 작업이 필요하다. 테스트 중에 DB에 결과가 반영되지는 않았지만, UserDao의 update() 메소드를 호출하는 것을 확인할 수 있다면, 결국 DB에 그 결과가 반영될 것이라고 결론을 내릴 수 있기 때문이다. UserDao와 같은 역할을 하면서 UserServiceImpl과의 사이에서 주고받은 정보를 저장해뒀다가, 테스트의 검증에 사용할 수 있게 하는 목 오브젝트를 만들 필요가 있다.
단위 테스트의 단위는 정하기 나름이다. 사용자 관리 기능 전체를 하나의 단위로 볼 수도 있고 하나의 클래스나 하나의 메소드를 단위로 볼 수도 있다. 중요한 것은 하나의 단위에 초점을 맞춘 테스트라는 점이다.
‘테스트 대상 클래스를 목 오브젝트 등의 테스트 대역을 이용해 의존 오브젝트나 외부의 리소스를 사용하지 않도록 고립시켜서 테스트 하는 것’을 단위 테스트라고 부른다. 반면에 두 개 이상의, 성격이나 계층이 다른 오브젝트가 연동하도록 만들어 테스트하거나, 또는 외부의 DB나 파일, 서비스 등의 리소스가 참여하는 테스트는 통합 테스트라고 부른다. 통합 테스트란 두 개 이상의 단위가 결합해서 동작하면서 테스트가 수행되는 것이라고 보면 된다. 스프링의 테스트 컨텍스트 프레임워크를 이용해서 컨텍스트에서 생성되고 DI된 오브젝트를 테스트하는 것도 통합 테스트다.
아래는 단위 테스트와 통합 테스트 중에서 어떤 방법을 쓸지 어떻게 결장할 것인지에 대한 가이드 라인이다.
단위 테스트를 만들기 위해서는 스텁이나 목 오브젝트의 사용이 필수적이다. 의존관계가 없는 단순한 클래스나 세부 로직을 검증하기 위해 메소드 단위로 테스트할 때가 아니라면, 대부분 의존 오브젝트를 필요로 하는 코드를 테스트하게 되기 때문이다.
목 오브젝트를 만드는 일은 번거로울 수 있다. 그러나 이런 번거로운 목 오브젝트를 편리하게 작성하도록 도와주는 다양한 목 오브젝트 지원 프레임워크가 있다.
Mockito라는 프레임워크는 사용하기도 편리하고, 코드도 직관직이라 최근 많은 인기를 끌고 있다.
Mockito와 같은 목 프레임워크의 특징은 목 클래스를 일일이 준비해둘 필요가 없다는 것이다. 간단한 메소드 호출만으로 다이내믹하게 특정 인터페이스를 구현한 테스트용 목 오브젝트를 만들 수 있다.
USerDao 인터페이스를 구현한 테스트용 목 오브젝트는 다음과 같이 Mockito의 스태틱 메소드를 한 번 호출해주면 만들어진다.
1 | UserDao mockUserDao = mock(UserDao.class); |
이렇게 만들어진 목 오브젝트는 아직 아무런 기능이 없다. 여기에 먼저 getAll() 메소드가 불려올 때 사용자 목록을 리턴하도록 스텁 기능을 추가해줘야 한다.
1 | when(mockUserDao.getAll()).thenReturn(this.users); |
mockUserDao.getAll()이 호출됐을 때(when), users 리스트를 리턴해주라(thenReturn)는 선언이다.
Mocktio를 통해 만들어진 목 오브젝트는 메소드의 호출과 관련된 모든 내용을 자동으로 저장해두고, 이를 간단한 메소드로 검증할 수 있게 해준다.
테스트를 진행하는 동안 mockUserDao의 update() 메소드가 두 번 호출됐는지 확인하고 싶다면, 다음과 같이 검증 코드를 넣어주면 된다.
1 | verify(mockUserDao, times(2)).update(any(User.class)); |
User 타입의 오브젝트를 파라미터로 받으며 update() 메소드가 두 번 호출됐는지(times(2)) 확인하라(verify)는 것이다.
Mockito 목 오브젝트는 다음의 네 단계를 거쳐서 사용하면 된다. 두 번째와 네 번째는 각각 필요할 경우에만 사용할 수 있다.
ArgumentCaptor는 목 오브젝트에 전달된 파라미터를 가져와 내용을 검증하기 위해 사용한다. 파라미터를 직접 비교하기 보다는 파라미터의 내부 정보를 확인해야 하는 경우에 유용하다.
부가기능 외의 나머지 모든 기능은 원래 핵심기능을 가진 클래스로 위임해줘야 한다. 핵심 기능은 부가기능을 가진 클래스의 존재 자체를 모른다. 따라서 부가기능이 핵심기능을 사용하는 구조가 되는 것이다
문제는 이렇게 구성했더라도 클라이언트가 핵심기능을 가진 클래스를 직접 사용해 버리면 부가기능이 적용될 기회가 없다는 점이다. 그래서 부가기능은 마치 자신이 핵심 기능을 가진 클래스인 것처럼 꾸며서, 클라이언트가 자신을 거쳐서 핵심기능을 사용하도록 만들어야 한다. 그러기 위해서는 클라이언트는 인터페이스를 통해서만 핵심기능을 사용하게 하고, 부가기능 자신도 같은 인터페이스를 구현한 뒤에 자신이 그 사이에 끼어들어야 한다.
이렇게 마치 자신이 클라이언트가 사용하려고 하는 실제 대상인 것처럼 위장해서 클라이언트의 요처을 받아주는 것을 대리자, 대리인과 같은 역할을 한다고 해서 **프록시(proxy)**라고 부른다. 그리고 프록시를 통해 최종적으로 요처을 위임받아 처리하는 실제 오브젝트를 타깃(target) 또는 실체(real subject)라고 부른다.
프록시의 특징은 타깃과 같은 인터페이스를 구현했다는 것과 프록시가 타깃을 제어할 수 있는 위치에 있다는 것이다.
프록시는 사용 목적에 따라 두 가지로 구분할 수 있다. 첫째는 클라이언트가 타깃에 접근하는 방법을 제어하기 위해서다. 두 번째는 타깃에 부가적인 기능을 부여해주기 위해서다. 두 가지 모두 대리 오브젝트라는 개념의 프록시를 두고 사용한다는 점은 동일하지만, 목적에 따라서 디자인 패턴에서느 다른 패턴으로 구분한다.
데코레이터 패턴은 타깃에 부가적인 기능을 런타임 시에 다이내믹하게 부여해주기 위해 프록시를 사용하는 패턴을 말한다. 다이내믹하게 기능을 부여한다는 의미는 컴파일 시점, 즉 코드상에서는 어떤 방법과 순서로 프록시와 타깃이 연결되어 사용되는지 정해져 있지 않다는 뜻이다. 데코레이터 패턴에서는 프록시가 꼭 한 개로 제한되지 않는다. 데코레이터 패턴에서는 같은 인터페이스를 구현한 타겟과 여러 개의 프록시를 사용할 수 있다.
프록시로서 동작하는 각 데코레이터는 위임하는 대상에도 인터페이스로 접근하기 때문에 자신이 최종 타깃으로 위임하는지, 아니면 다음 단계의 데코레이터 프록시로 위임하는지 알지 못한다. 그래서 데코레이터의 다음 위임 대상은 인터페이스로 선언하고 생성자나 수정자 메소드를 통해 위임 대상을 외부에서 런타임 시에 주입받을 수 있도록 만들어야 한다.
인터페이스를 통한 데코레이터 정의와 런타임 시의 다이내믹한 구성 방법은 스프링의 DI를 이요하면 아주 편리하다. 데코레이터 빈의 프로퍼티로 같은 인터페이스를 구현한 다른 데코레이터 또는 타깃 빈을 설정하면 된다.
데코레이터 패턴은 타깃의 코드를 손대지 않고, 클라이언트가 호출하는 방법도 변경하지 않은 채로 새로운 기능을 추가할 때 유용한 방법이다.
일반적으로 사용하는 프록시라는 용어와 디자인 패턴에서 말하는 프록시 패턴은 구분할 필요가 있다. 전자는 클라이언트와 사용 대상 사이에 대리 역할을 맡은 오브젝트를 두는 방법을 말한다면, 후자는 프록시를 사용하는 방법 중에서 타깃에 대한 접근 방법을 제어하려는 목적을 가진 경우를 가리킨다.
프록시 패턴의 프록시는 타깃의 기능을 확장하거나 추가하지 않는다. 대신 클라이언트가 타깃에 접근하는 방식을 변경해준다.
프록시 패턴은 타깃의 기능 자체에는 관여하지 않으면서 접근하는 방법을 제어해주는 프록시를 이용하는 것이다. 구조적으로 보자면 프록시와 데코레이터는 유사하다. 다만 프록시는 코드에서 자신이 만들거나 접근할 타깃 클래스 정보를 알고 있는 경우가 많다. 생성을 지연하는 프록시라면 구체적인 생성 방법을 알아야 하기 때문에 타깃 클래스에 대한 직접적인 정보를 알아야 한다. 물론 프록시 팽턴이라고 하더라도 인터페이스를 통해 위임하도록 만들 수도 있다. 인터페이스를 토앻 다음 호출 대상으로 접근하게 되면 그 사이에 다른 프록시나 데코레이터가 계속 추가될 수 있기 때문이다.
앞으로는 타깃과 동일한 인터페이스를 구현하고 클라이언트와 타깃 사이에 존재하면서 기능의 부가 또는 접근 제어를 담당하는 오브젝트를 모두 프록시라고 부르겠다. 하지만 그때마다 사용의 목적이 기능의 부가인지, 접근 제어인지를 구분해보면 각각 어떤 목적으로 프록시가 사용됐는지, 그에 따라 어떤 패턴이 적용됐는지 알 수 있을 것이다.
목 오브젝트를 만드는 불편함을 목 프레임워크를 사용해 편리하게 바꿨던 것처럼 프록시도 일일이 모든 인터페이스를 구현해서 클래스를 새로 정의하지 않고도 편리하게 만들어서 사용할 방법이 있다.
자바에는 java.lang.reflect 패키지 안에 프록시를 손쉽게 만들 수 있도록 지원해주는 클래스들이 있다. 일일이 프록시 클래스를 정의하지 않고도 몇 가지 API를 이용해 프록시처럼 동작하는 오브젝트를 다이내믹하게 생성하는 것이다.
프록시는 다음의 두 가지 기능으로 구성된다.
프록시를 만들기가 번거로운 이유는 두 가지가 있다.
첫 번째 문제인 인터페이스 메소드의 구현과 위임 기능 문제는 간단해 보이지 않는다. 바로 이런 문제를 해결하는 데 유용한 것이 바로 JDK의 다이내믹 프록시다.
다이내믹 프록시는 리플렉션 기능을 이용해서 프록시를 만들어준다. 리플렉션은 자바의 코드 자체를 추상화해서 접근하도록 만든 것이다.
자바의 모든 클래스는 그 클래스 자체의 구성정보를 담은 Class 타입의 오브젝트를 하나씩 갖고 있다. ‘클래스이름.class’라고 하거나 오브젝트의 getClass() 메소드를 호출하면 클래스 정보를 담은 Class 타입의 오브젝트를 가져올 수 있다. 클래스 오브젝트를 이용하면 크래스 코드에 대한 메타정보를 가져오거나 오브젝트를 조작할 수 있다.
1 | package springbook.learningtest.jdk; |
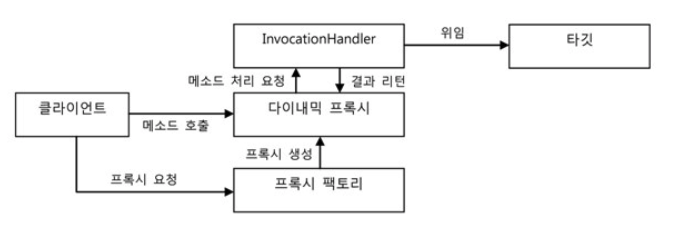
다이내믹 프록시는 프록시 팩토리에 의해 런타임 시 다이내믹하게 만들어지는 오브젝트다. 다이내믹 프록시 오브젝트는 타깃의 인터페이스와 같은 타입으로 만들어진다. 클라이언트는 다이내믹 프록시 오브젝트를 타깃 인터페이스를 통해 사용할 수 있다. 이 덕분에 프록시를 만들 때 인터페이스를 모두 구현해가면서 클래스를 정의하는 수고를 덜 수 있다. 프록시 팩토리에게 인터페이스 정보만 제공해주면 해당 인터페이스를 구현한 클래스의 오브젝트를 자동으로 만들어주기 때문이다.
다이내믹 프록시가 인터페이스 구현 클래스의 오브젝트는 만들어주지만, 프록시로서 필요한 부가기능 제공 코드는 직접 생성해야 한다. 부가기능은 프록시 오브젝트와 독립적으로 InvocationHandler를 구현한 오브젝트에 담는다. InvocationHandler 인터페이스는 다음과 같은 메소드 한 개만 가진 간단한 인터페이스다.
1 | public Object invoke(Object proxy, Method method, Object[] args) |
invoke() 메소드는 리플렉션의 MEthod 인터페이스를 파라미터로 받는다. 메소드를 호출할 때 전달되는 파라미터도 args로 받는다. 다이내믹 프록시 오브젝트는 클라이언트의 모든 요청을 리플렉션 정보로 변환해서 InvocationHandler 구현 오브젝트의 invoke() 메소드로 넘기는 것이다. 타깃 인터페이스의 모든 메소드 요청이 하나의 메소드로 집중되기 때문에 중복되는 기능을 효과적으로 제공할 수 있다.
InvocationHandler 구현 오브젝트가 타깃 오브젝트 레퍼런스를 갖고 있다면 리플렉션을 이용해 간단히 위임 코드를 만들어 낼 수 있다.
InvocationHandler 인터페이스를 구현한 오브젝트를 제공해주면 다이내믹 프록시가 받는 모든 요청을 InvocationHandler의 invoke() 메소드로 보내준다.
다이내믹 프록시로부터 요청을 전달받으려면 InvocationHandler를 구현해야 한다. 메소드는 invoke() 하나뿐이다. 다이내믹 프록시가 클라이언트로부터 받는 모든 요청은 incoke() 메소드로 전달된다. 다이내믹 프록시를 통해 요청이 전달되면 리플렉션 API를 이용해 타깃 오브젝트의 메소드를 호출한다. 타깃 오브젝트는 생성자를 통해 미리 전달받아 둔다.
다이내믹 프록시의 생성은 Proxy 클래스의 newProxyInstance() 스태틱 팩토리 메소드를 이용하면 된다.
1 | // 생성된 다이내믹 프록시 오브젝트는 Hello 인터페이스를 구현하고 있으므로 Hello 타입으로 캐스팅해도 안전하다. |
1 | public class UppercaseHandler implements InvocationHandler { |
1 | public class TransactionHandler implements InvocationHandler { |
1 |
|
이제 TransactionHandler와 다이내믹 프록시를 스프링의 DI를 통해 사용할 수 있도록 만들어야 할 차례다.
스프링의 빈은 기본적으로 클래스 이름과 프로퍼티로 정의된다. 스프링은 지정된 클래스 이름을 가지고 리플렉션을 이용해서 해당 클래스의 오브젝트를 만든다. 클래스의 이름을 갖고 있다면 다음과 같은 방법으로 새로운 오브젝트를 생성할 수 있다. Class의 newInstance() 메소드는 해당 클래스의 파라미터가 없는 생성자를 호출하고, 그 결과 생성되는 오브젝트를 돌려주는 리플렉션 API다.
1 | Date now = (Date) Class.forName("java.util.Date").newInstance(); |
스프링은 내부적으로 리플렉션 API를 이용해서 빈 정의에 나오는 클래스 이름을 가지고 빈 오브젝트를 생성한다. 문제는 다이내믹 프록시 오브젝트는 이런 식으로 프록시 오브젝트가 생성되지 않는다는 점이다. 사실 다이내믹 프록시 오브젝트의 클래스가 어떤 것인지 알 수도 없다. 클래스 자체도 내부적으로 다이내믹하게 새로 정의해서 사용하기 때문이다. 따라서 사전에 프록시 오브젝트의 클래스 정보를 미리 알아내서 스프링의 빈에 정의할 방법이 없다. 다이내믹 프록시는 Proxy 클래스의 newProxyInstance()라는 스태틱 팩토리 메소드를 통해서만 만들 수 있다.
스프링은 클래스 정보를 가지고 디폴트 생성자를 통해 오브젝트를 만드는 방법 외에도 빈을 만들 수 있는 여러 가지 방법을 제공한다. 대표적으로 팩토리 빈을 이용한 빈 생성 방법을 들 수 있다. 팩토리 빈이란 스프링을 대신해서 오브젝트의 생성로직을 담당하도록 만들어진 특별한 빈을 말한다.
팩토리 빈을 만드는 방법에는 여러 가지가 있는데, 가장 간단한 방법은 스프링의 FactoryBean이라는 인터페이스를 구현하는 것이다.
사실 스프링은 private 생성자를 가진 클래스도 빈으로 등록해주면 리플렉션을 이용해 오브젝트를 만들어준다.
1 | package org.springframework.beans.factory; |
Proxy의 newPRoxyInstance() 메소드를 통해서만 생성이 가능한 다이내믹 프록시 오브젝트는 일반적인 방법으로는 스프링의 빈을 등록할 수 없다. 대신 팩토리 빈을 사용하면 다이내믹 프록시 오브젝트를 스프링의 빈으로 만들어줄 수가 있다. 팩토리 빈의 getObject() 메소드에 다이내믹 프록시 오브젝트를 만들어주는 코드를 넣으면 되게 때문이다.
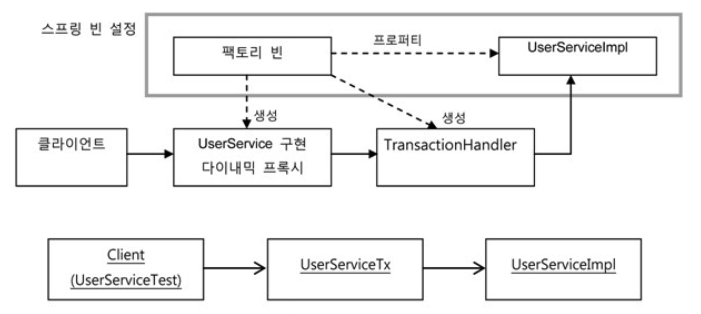
스프링 빈에는 팩토리 빈과 UserServiceImpl만 빈으로 등록한다. 팩토리 빈은 다이내믹 프록시가 위임할 타깃 오브젝트인 UserServiceImpl에 대한 레퍼런스를 프로퍼티를 통해 DI 받아둬야 한다. 다이내믹 프록시와 함께 생성할 TransactionHandler에게 타깃 오브젝트를 전달해줘야 하기 때문이다. 그 외에도 다이내믹 프록시나 TransactionHandler를 만들 때 필요한 정보는 팩토리 빈의 프로퍼티로 설정해뒀다가 다이내믹 프록시를 만들면서 전달해줘야 한다.
다이내믹 프록시를 생성해주는 팩토리 빈을 사용하는 방법은 여러 가지 장점이 있다. 한번 부가기능을 가진 프록시를 생성하는 팩토리 빈을 만들어두면 타깃의 타입에 상관없이 재사용할 수 있기 때문이다.
다이내믹 프록시를 이용하면 타깃 인터페이스를 구현하는클래스를 일일이 만드는 번거로움을 제거할 수 있다. 하나의 핸들러 메소드를 구현하는 것만으로도 수많은 메소드에 부가기능을 부여해줄 수 있으니 부가기능 코드의 중복 문제도 사라진다. 다이내믹 프록시에 팩토리 빈을 이용한 DI까지 더해주면 번거로운 다이내믹 프록시 생성 코드도 제거할 수 있다. DI 설정만으로 다양한 타깃 오브젝트에 적용도 가능하다.
프록시를 통해 타깃에 부가기능을 제공하는 것은 메소드 단위로 일어나는 일이다. 하나의 크래스 안에 존재하는 여러 개의 메소드에 부가기능을 한 번에 제공하는 건 어렵지 않게 가능했다. 하지만 한 번에 여러 개의 크래스에 공통적인 부가기능을 제공하는 일은 지금까지 살펴본 방법으로는 불가능하다.
하나의 타깃에 여러 개의 부가기능을 적용하려고 할 때도 문제다. 프록시 팩토리 빈 설정이 부가기능의 개수만큼 따라 붙어야 한다.
자바에는 JDK에서 제공하는 다이내믹 프록시 외에도 편리하게 프록시를 만들 수 있도록 지원해주는 다양한 기술이 존재한다. 따라서 스프링은 일관된 방법으로 프록시를 만들 수 있게 도와주는 추상 레이어를 제공한다. 생성된 프록시는 스프링의 빈으로 등록돼야 한다. 스프링은 프록시 오브젝트를 생성해주는 기술을 추상화한 팩토리 빈을 제공해준다.
스프링의 ProxyFactoryBean은 프록시를 생성해서 빈 오브젝트로 등록하게 해주는 팩토리 빈이다. ProxyFactoryBean은 순수하게 프록시를 생성하는 작업만을 담당하고 프록시를 통해 제공해줄 부가기능은 별도의 빈에 둘 수 있다.
ProxyFactoryBean이 생성하는 프록시에서 사용할 부가기능은 MethodInterceptor 인터페이스를 구현해서 만든다. MethodInterceptor는 InvocationHandler와 비슷하지만 한 가지 다른 점이 있다. InvocationHandler의 invoke() 메소드는 타깃 오브젝트에 대한 정보를 제공하지 않는다. 따라서 타깃은 InvocationHandler를 구현한 크래스가 직접 알고 있어야 한다. 반면에 MethodInterceptor의 invoke() 메소드는 ProxyFactoryBean으로부터 타깃 오브젝트에 대한 정보까지도 함께 제공받는다. 그 차이 덕분에 MethodInterceptor는 타깃 오브젝트에 상관없이 독립적으로 만들어질 수 있다. 따라서 MethodInterceptor 오브젝트는 타깃이 다른 여러 프록시에서 함께 사용할 수 있고, 싱글톤 빈으로 등록 가능하다.
MethodInvocation은 일종의 콜백 오브젝트로, proceed() 메소드를 실행하면 타깃 오브젝트의 메소드를 내부적으로 실행해주는 기능이 있다. ProxyFactoryBean은 작은 단위의 템플릿/콜백 구조를 응용해서 적용했기 때문에 템플릿 역할을 하는 MethodInvocation을 싱글톤으로 두고 공유할 수 있다.
MethodInterceptor처럼 타깃 오브젝트에 적용하는 부가기능을 담은 오브젝트를 스프링에서는 어드바이스(advice)라고 부른다.
ProxyFactoryBean은 기본적으로 JDK가 제공하는 다이내믹 프록시를 만들어준다. 경우에 따라서는 CGLib이라고 하는 오픈소스 바이트코드 생성 프레임워크를 이용해 프록시를 만들기도 한다.
어드바이스는 타깃 오브젝트에 종속되지 않는 순수한 부가기능을 담은 오브젝트라는 사실을 잘 기억해두자.
MethodInterceptor 오브젝트는 여러 프록시가 공유해서 사용할 수 있다. 그러기 위해서 MethodInterceptor 오브젝트는 타깃 정보를 갖고 있지 않도록 만들었다. 그 덕분에 MethodInterceptor를 스프링의 싱글톤 빈으로 등록할 수 있었다. 그런데 여기에다 트랜잭션 적용 대상 메소드 이름 패턴을 넣어주는 것은 곤란하다. 트랜잭션 적용 메소드 패턴은 프록시마다 다를 수 있기 때문에 여러 프록시가 공유하는 MethodInterceptor에 특정 프록시에만 적용되는 패턴을 넣으면 문제가 된다.
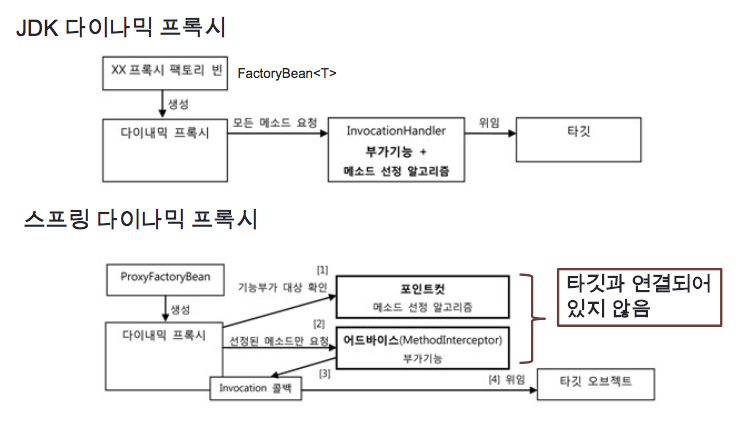
InvocationHandler는 타깃과 메소드 선정 알고리즘 코드에 의존하고 있지만, 스프링의 ProxyFactoryBean 방식은 두 가지 확장 기능인 부가기능(Advice)과 메소드 선정 알고리즘(Pointcut)을 활용하는 유연한 구조를 제공한다.
스프링은 부가기능을 제공하는 오브젝트를 어드바이스라고 부르고, 메소드 선정 알고리즘을 담은 오브젝트를 포인트컷이라고 부른다. 어드바이스와 포인트컷은 모두 프록시에 DI로 주입돼서 사용된다. 두 가지 모두 여러 프록시에서 공유가 가능하도록 만들어지기 때문에 스프링의 싱글톤 빈으로 등록이 가능하다.
프록시는 클라이언트로부터 요청을 받으면 먼저 포인트컷에게 부가기능을 부여할 메소드인지를 확인해달라고 요청한다. 포인트컷은 Pointcut 인터페이스를 구현해서 만들면 된다. 프록시는 포인트컷으로부터 부가기능을 적용할 대상 메소드인지 확인받으면, MethodInterceptor 타입의 어드바이스를 호출한다. 어드바이스는 JDK의 다이내믹 프록시의 InvocationHandler와 달리 직접 타깃을 호출하지 않는다.
어드바이스가 일종의 템플릿이 되고 타깃을 호출하는 기능을 갖고 있는 MethodInvocation 오브젝트가 콜백이 되는 것이다. 템플릿은 한 번 만들면 재사용이 가능하고 여러 빈이 공유해서 사용할 수 있듯이, 어드바이스도 독립적인 싱글톤 빈으로 등록하고 DI를 주입해서 여러 프록시가 사용하도록 만들 수 있다.
프록시로부터 어드바이스와 포인트컷을 독립시키고 DI를 사용하게 한 것은 전형적인 전략 패턴 구조다.
1 |
|
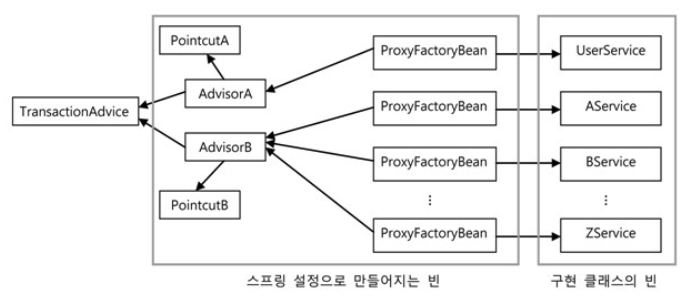
ProxyFactoryBean에는 여러 개의 어드바이스와 포인트컷이 추가될 수 있다. 포인트컷과 어드바이스를 따로 등록하면 어떤 어드바이스(부가 기능)에 대해 어떤 포인트컷(메소드 선정)을 적용할지 애매해지기 때문이다. 그래서 이 둘을 Advisor 타입의 오브젝트에 담아서 조합을 만들어 등록하는 것이다. 여러 개의 어드바이스가 등록되더라도 각각 다른 포인트컷과 조합될 수 있기 때문에 각기 다른 메소드 선정 방식을 적용할 수 있다. 이렇게 어드바이스와 포인트 컷을 묶은 오브젝트를 인터페이스 이름을 따서 어드바이저라고 부른다.
어드바이저 = 포인트컷(메소드 선정 알고리즘) + 어드바이스(부가기능)
ProxyFactoryBean은 스프링의 DI와 템플릿/콜백 패턴, 서비스 추상화 등의 기법이 모두 적용된 것이다. 그 덕분에 독립적이며, 여러 프록시가 공유할 수 있는 어드바이스와 포인트컷으로 확장 기능을 분리할 수 있었다.
JDK의 다이내믹 프록시는 특정 인터페이스를 구현한 오브젝트에 대해서 프록시 역할을 해주는 클래스를 런타임 시 내부적으로 만들어준다. 런타임 시에 만들어져 사용되기 때문에 클래스 소스가 따로 남지 않을 뿐이지 타깃 인터페이스의 모든 메소드를 구현하는 클래스가 분명히 만들어진다.
변하지 않는 타깃으로의 위임과 부가기능 적용 여부 판단이라는 부분은 코드 생성기법을 이용하는 다이내믹 프록시 기술에 맡기고, 변하는 부가기능 코드는 별도로 만들어서 다이내믹 프록시 생성 팩토리에 DI로 제공하는 방법을 사용한 것이다. 좀 독특하긴 하지만 변하는 로직과 변하지 않는 기계적인 코드를 잘 분리해낸 것이다.
반복적인 프록시의 메소드 구현은 코드 자동생성 기법을 이용해 해결했다면 반복적인 ProxyFactoryBean 설정 문제는 설정 자동등록 기법으로 해결할 수 없을까?
하지만 지금까지 살펴본 방법에서는 한 번에 여러 개의 빈에 프록시를 적용할 만한 방법은 없었다.
스프링은 컨테이너로서 제공하는 기능 중에서 변하지 않는 핵심적인 부분외에는 대부분 확장할 수 있도록 확장 포인트를 제공해준다.
그 중에서 관심을 가질 만한 확장 포인트는 BeanPostProcessor 인터페이스를 구현해서 만든 빈 후처리기다. 빈 후처리기는 이름 그대로 스프링 빈 오브젝트로 만들어지고 난 후에, 빈 오브젝트를 다시 가공할 수 있게 해준다.
스프링은 빈 후처리기 중의 하나로 DefaultAdvisorAutoProxyCreator를 제공한다. DefaultAdvisorAutoProxyCreator는 어드바이저를 이용한 자동 프록시 생성기다. 빈 후처리기를 스프링에 적용하는 방법은 간단하다. 빈 후처리기 자체를 빈으로 등록하는 것이다. 스프링은 빈 후처리기가 빈으로 등록되어 있으면 빈 오브젝트가 생성될 때마다 빈 후처리기에 보내서 후처리 작업을 요청한다. 빈 후처리기는 빈 오브젝트의 프로퍼티를 강제로 수정할 수도 있고 별도의 초기화 작업을 수행할 수도 있다. 심지어는 만들어진 빈오브젝트 자체를 바꿔치기할 수도 있다. 따라서 스프링이 설정을 참고해서 만든 오브젝트가 아닌 다른 오브젝트를 빈으로 등록시키는 것이 가능하다.
이를 잘 활용하면 스프링이 생성하는 빈 오브젝트의 일부를 프록시로 포장하고, 프록시를 빈으로 대신 등록할 수도 있다.
DefaultAdvisorAutoProxyCreator 빈 후처리기가 등록되어 있으면 스프링은 빈 오브젝트를 만들 때마다 후처리기에게 빈을 보낸다. DefaultAdvisorAutoProxyCreator는 빈으로 등록된 모든 어드바이저 내의 포인트컷을 이용해 전달받은 빈이 프록시 적용 대상인지 확인한다. 프록시 적용 대상이면 그때는 내장된 프록시 생성기에게 현재 빈에 대한 프록시를 만들게 하고, 만들어진 프록시에 어드바이저를 연결해준다. 빈 후처리기는 프록시가 생성되면 원래 컨테이너가 전달해준 빈 오브젝트 대신 프록시 오브젝트를 컨테이너에게 돌려준다. 컨테이너는 최종적으로 빈 후처리기가 돌려준 오브젝트를 빈으로 등록하고 사용한다.
적용할 빈을 선정하는 로직이 추가된 포인트컷이 담긴 어드바이저를 등록하고 빈 후처리기를 사용하면 일일이 ProxyFactoryBean 빈을 등록하지 않아도 타깃 오브젝트에 자동으로 프록시가 적용되게 할 수 있다.
포인트컷은 클래스 필터와 메소드 매처 두 가지를 돌려주는 메소드를 갖고 있다. 실제 포인트컷의 선별 로직은 이 두가지 타입의 오브젝트에 담겨 있다.
1 | public interface Pointcut { |
만약 Pointcut 선정 기능을 모두 적용한다면 먼저 프록시를 적용할 클래스인지 판단하고 나서, 적용 대상 클래스인 경우에는 어드바이스를 적용할 메소드인지 확인하는 식으로 동작한다. 결국 이 두 가지 조건이 모두 충족되는 타깃의 메소드에 어드바이스가 적용되는 것이다.
모든 빈에 대해 프록시 자동 적용 대상을 선별해야 하는 빈 후처리기인 DefaultAdvisorAutoProxyCreator는 클래스와 메소드 선정 알고리즘을 모두 갖고 있는 포인트컷이 필요하다. 정확히는 그런 포인트컷과 어드바이스가 결합되어 있는 어드바이저가 등록되어 있어야 한다.
메소드 이름만 비교하던 포인트컷인 NameMatchMethodPointcut을 상속해서 프로퍼티로 주어진 이름 패턴을 가지고 클래스 이름을 비교하는 ClassFilter를 추가하도록 만든다.
1 | package springbook.learningtest.jdk.proxy; |
자동 프록시 생성기인 DefaultAdvisorAutoProxyCreator는 등록된 빈 중에서 Advisor 인터페이스를 구현한 것을 모두 찾는다. 그리고 생성되는 모든 빈에 대해 어드바이저의 포인트컷을 적용해보면서 프록시 적용 대상을 선정한다. 빈 클래스가 프록시 선정 대상이라면 프록시를 만들어서 원래 빈 오브젝트와 바꿔치기한다. 원래 빈 오브젝트는 프록시 뒤에 연결돼서 프록시를 통해서만 접근 가능하게 바뀌며, 타깃 빈에 의존한다고 정의한 다른 빈들은 등록시 프록시 오브젝트를 대신 DI 받게 된다. DefaultAdvisorAutoProxyCreator 등록은 다음 한 줄과 같다.
1 | <bean class="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator" /> |
다른 빈에서 참조되거나 코드에서 빈 이름으로 조회될 필요가 없는 빈이라면 아이디를 등록하지 않아도 무방하다.
스프링은 아주 간단하고 효과적인 방법으로 포인트컷의 클래스와 메소드를 선정하는 알고리즘을 작성할 수 있는 방법을 제공한다. 정규식이나 JSP의 EL과 비슷한 일종의 표현식 언어를 사용해서 포인트컷을 작성할 수 있도록 하는 방법이다. 그래서 이것을 포인트컷 표현식이라고 부른다.
포인트컷 표현식을 지원하는 포인트컷을 적용하려면 AspectJExpressionPointcut 클래스를 사용하면 된다. Pointcut 인터페이스를 구현해야 하는 스프링의 포인트컷은 클래스 선정을 위한 클래스 필터와 메소드 선정을 위한 메소드 매처 두 가지를 각각 제공해야 한다.
하지만 AspectJExpressionPointcut은 클래스와 메소드의 선정 알고리즘을 포인트컷 표현식을 이용해 한 번에 지정할 수 있게 해준다. 포인트컷 표현식은 자바의 RegEx 클래스가 지원하는 정규식처럼 간단한 문자열로 복잡한 선정조건을 쉽게 만들어낼 수 있는 강력한 표현식을 지원한다. 사실 스프링이 사용하는 포인트컷 표현식은 AspectJ라는 유명한 프로엠워크에서 제공하는 것을 가져와 일부 문법을 확장해서 사용하는 것이다.
포인트컷 표현식은 메소드의 시그니처를 비교하는 방식인 execution() 외에도 몇 가지 표현식 스타일을 갖고 있다. 대표적으로 스프링에서 사용될 때 빈의 이름으로 비교하는 bean()이 있다.
또 특정 애노테이션이 타입, 메소드, 파라미터에 적용되어 있는 것을 보고 메소드를 선정하게 하는 포인트컷도 만들 수 있다. 애노테이션만 부여해놓고, 포인트컷을 통해 자동으로 선정해서, 부가기능을 제공하게 해주는 방식은 스프링 내에서도 애용되는 편리한 방법이다.
클래스 이름은 ServiceImpl로 끝나고 메소드 일므은 upgrade로 시작하는 모든 클래스에 적용되도록 하는 표현식을 만들고 이를 적용한 빈 설정은 다음과 같다.
1 | <bean id="transactionPointcut" class="org.springframework.aop.aspectj.AspectJExpressionPointcut"> |
부가기능 모듈화 작업은 기존의 객체지향 설계 패러다임과는 구분되는 새로운 특성이 있다고 생각했다. 그래서 이런 부가기능 모듈을 객체지향 기술에서는 주로 사용하는 오브젝트와는 다르게 특별한 이름으로 부르기 시작했다. 그것이 바로 애스펙트(aspect)다. 애스펙트란 그 자체로 애플리케이션의 핵심기능을 담고 있지는 않지만, 애플리케이션을 구성하는 중요한 한 가지 요소이고, 핵심기능에 부가되어 의미를 갖는 특별한 모듈을 가리킨다.
애스펙트는 부가될 기능을 정의한 코드인 어드바이스와, 어드바이스를 어디에 적용할지를 결정하는 포인트컷을 함께 갖고 있다.
독립된 측면에 존재하는 애스팩트로 분리한 덕에 핵심기능은 순수하게 그 기능을 담은 코드로만 존재하고 독립적으로 살펴볼 수 있도록 구분된 면에 존재하게 된 것이다.
이렇게 애플리케이션의 핵심적인 기능에서 부가적인 기능을 분리해서 애스펙트라는 독특한 모듈로 만들어서 설계하고 개발하는 방법을 애스펙트 지향 프로그래밍(Aspect Oriented Programming) 또는 약자로 AOP라고 부른다.
AOP는 OOP를 돕는 보조적인 기술이지 OOP를 완전히 대체하는 새로운 개념은 아니다. AOP는 애스펙트를 분리함으로써 핵심기능을 설계하고 구현할 때 객체지향적인 가치를 지킬 수 있도록 도와주는 것이라고 보면 된다. AOP를 관점 지향 프로그래밍이라고도 한다.
프록시 방식이 아닌 AOP도 있다. AOP 기술의 원조이자, 가장 강력한 AOP 프레임워크로 꼽히는 AspectJ는 프록시를 사용하지 않는 대표적인 AOP 기술이다. AspectJ는 스프링처럼 다이내믹 프록시 방식을 사용하지 않는다.
AspectJ는 프록시처럼 간접적인 방법이 아니라, 타깃 오브젝트를 뜯어고쳐서 부가기능을 직접 넣어주는 직접적인 방법을 사용한다. 컴파일된 타깃의 클래스 파일 자체를 수정하거나 클래스가 JVM에 로딩되는 시점을 가로채서 바이트코드를 조작하는 복잡한 방법을 사용한다.
AspectJ가 프록시 같은 방법이 있지만 컴파일된 클래스 파일 수정이나 바이트코드 조작과 같은 복잡한 방법을 사용하는 것에는 두 가지 이유가 있다.
트랜잭션이라고 모두 같은 방식으로 동작하는 것이 아니다. DefaultTransactionDefinition이 구현하고 있는 TransactionDefinition 인터페이스는 트랜잭션 동작방식에 영향을 줄 수 있는 4가지 속성을 정의하고 있다.
이건 전략이라기보다는 주의사항이다. 프록시 방식의 AOP에서는 프록시를 통한 부가 기능의 적용은 클라이언트로부터 호출이 일어날 때만 가능하다. 여기서 클라이언트는 인터페이스를 통해 타깃 오브젝트를 사용하는 다른 모든 오브젝트를 말한다. 반대로 타깃 오브젝트가 자기 자신의 메소드를 호출할 떄는 프록시를 통한 부가기능의 적용이 일어나지 않는다. 따라서 같은 오브젝트 안에서의 호출은 새로운 트랜잭션 속성을 부여하지 못한다는 사실을 의식하고 개발할 필요가 있다.
타깃 안에서의 호출에는 프록시가 적용되지 않는 문제를 해결할 수 있는 방법은 두 가지가 있다.
트랜잭션 경계설정의 부가기능을 여러 계층에서 중구난방으로 적용하는 건 좋지 않다. 일바적으로 특정 계층의 경계를 트랜잭션 경계와 일치시키는 것이 바람직하다. 비즈니스 로직을 담고 있는 서비스 계층 오브젝트의 메소드가 트랜잭션 경계를 부여하기에 가장 적절한 대상이다.
AOP를 이용해 코드 외부에서 트랜잭션의 기능을 부여해주고 속성을 지정 할 수 있게 하는 방법을 선언적 트랜잭션이라고 한다. 반대로 TransactionTemplate이나 개별 데이터 기술의 트랜잭션 API를 사용해 직접 코드 안에서 사용하는 방법은 프로그램에 의한 트랜잭션이라고 한다. 스프링은 이 두 가지 방법을 모두 지원하고 있다. 물론 특별한 경우가 아니라면 선언적 방식의 트랜잭션을 사용하는 것이 바람직하다.
트랜잭션 추상화 기술의 핵심은 트랜잭션 매니저와 트랜잭션 동기화다. PlatformTransactionManager 인터페이스를 구현한 트랜잭션 매니저를 통해 구체적인 트랜잭션 기술의 종류에 상관없이 일관된 트랜잭션 제어가 가능했다. 또한 트랜잭션 동기화 기술이 있었기에 시작된 트랜잭션 정보를 저장소에 보관해뒀다가 DAO에서 공유할 수 있었다.
트랜잭션 동기화 기술은 트랜잭션 전파를 위해서도 중요한 역할을 한다. 진행 중인 트랜잭션이 있는지 확인하고, 트랜잭션 전파 속성에 따라서 이에 참여할 수 있도록 만들어주는 것도 트랜잭션 동기화 기술 덕분이다.
JdbcTemplate과 같이 스프링이 제공하는 데이터 액세스 추상화를 적용한 DAO에도 동일한 영향을 미친다. JdbcTemplate은 트랜잭션이 시작된 것이 있으면 그 트랜잭션에 자동으로 참여하고, 없으면 트랜잭션 없이 자동커밋 모드로 JDBC 작업을 수행한다. 개념은 조금 다르지만 JdbcTemplate의 메소드 단위로 마치 트랜잭션 전파 속성이 REQUIRED인 것처럼 동작한다고 볼 수 있다.
트랜잭션이란 더 이상 나눌 수 없는 단위 작업을 말한다. 작업을 쪼개서 작은 단위로 만들 수 없다는 것은 트랜잭션의 핵심 속성인 원자성을 의미한다.
DB는 그 자체로 완벽한 트랜잭션을 지원한다. SQL을 이용해 다중 로우의 수정이나 삭제를 위한 요청을 했을 때 일부 로우만 삭제되고 안 된다거나, 일부 필드는 수정했는데 나머지 필드는 수정이 안 되고 실패로 끝나는 경우는 없다. 하나의 SQL 명령을 처리하는 경우는 DB가 트랜잭션을 보장해준다고 믿을 수 있다.
하지만 여러 개의 SQL이 사용되는 작업을 하나의 트랜잭션으로 취급해야 하는 경우도 있다. 이때 여러 가지 작업이 하나의 트랜잭션이 되려면, 두 번째 이후의 SQL이 성공적으로 DB에서 수행되기 전에 문제가 발생할 경우 앞에서 처리한 SQL 작업도 취소시켜야 한다. 이런 취소 작업을 트랜잭션 롤백(transaction roolback)이라고 한다. 반대로 여러 개의 SQL을 하나의 트랜잭션으로 처리하는 경우에 모든 SQL 수행 작업이 다 성공적으로 마무리됐다고 DB에 알려줘서 작업을 확정시켜야 한다. 이것을 트랜잭션 커밋(transaction commit)이라고 한다.
모든 트랜잭션은 시작하는 지점과 끝나는 지점이 있다. 시작하는 방법은 한 가지이지만 끝나는 방법은 두 가지다. 모든 작업을 무효화하는 롤백과 모든 작업을 다 확장하는 커밋이다.
JDBC의 트랜잭션은 하나의 Connection을 가져와 사용하다가 닫는 사이에 일어난다. 트랜잭션의 시작과 종료는 Coonection 오브젝트를 통해 이루어지기 때문이다. JDBC의 기본 설정은 DB 작업을 수행한 직후에 자동으로 커밋이 되도록 되어 있다.
트랜잭션이 한 번 시작되면 commit() 또는 rollback() 메소드가 호출될 때까지의 작업이 하나의 트랜잭션으로 묶인다. commit() 또는 rollback()이 호출되면 그에 따라 작업 결과가 DB에 반영되거나 취소되고 트랜잭션이 종료된다.
setAutoCommit(false)로 트랜잭션의 시작을 선언하고 commit() 또는 rollback()으로 트랜잭션을 종료하는 작업을 트랜잭션의 경계설정(transaction demarcation)이라고 한다. 트랜잭션의 경계는 하나의 Connection이 만들어지고 닫히는 범위 안에 존재한다는 점도 기억하자. 이렇게 하나의 DB 커넥션 안에서 만들어지는 트랜잭션을 로컬 트랜잭션(local transaction)이라고도 한다.
UserService와 UserDao를 그대로 둔 채로 트랜잭션을 적용하려면 결국 트랜잭션의 경계설정 작업을 UserService 쪽으로 가져와야 한다. UserDao가 가진 SQL이나 JDBC API를 이용한 데이터 엑세스 코드는 최대한 그대로 남겨둔 채로, UserService에는 트랜잭션 시작과 종료를 담당하는 최소한의 코드만 가져오게 만들면 어느 정도 책임이 다른 코드를 분리해 둔 채로 트랜잭션 문제를 해결할 수 있다.
위의 방법을 사용하면 다음과 같은 문제점이 발생한다.
첫째는 DB 커넥션을 비롯한 리소스의 깔끔한 처리를 가능하게 했던 JdbcTemplate을 더 이상 활용할 수 없다는 점이다. Try/catch/finally 블록은 이제 UserService 내에 존재하고, UserService의 코드는 JDBC 작업 코드의 전형적인 문제점을 그대로 가질 수 밖에 없다.
두 번째 문제점은 DAO의 메소드와 비즈니스 로직을 담고 있는 UserService의 메소드에 Connection 파라미터가 추가돼야 한다는 점이다.
세 번째 문제는 Connection 파라미터가 UserDao 인터페이스 메소드에 추가되면 UserDao는 더 이상 데이터 액세스 기술에 독립적일 수가 없다는 점이다.
스프링은 위의 문제를 해결할 수 있는 멋진 방법을 제공해준다.
Connection 오브젝트를 한번 생성 후 계속 메소드의 파라미터로 전달하다가 DAO를 호출할 때 사용하는 건 피하고 싶다. 이를 위해 스프링이 제안하는 방법은 트랜잭션 동기화(transaction synchronization) 방식이다. 트랜잭션 동기화란 UserService에서 트랜잭션을 시작하기 위해 만든 Connection 오브젝트를 특별한 저장소에 보관해두고, 이후에 호출되는 DAO의 메소드에서는 저장된 Coonection을 가져다가 사용하게 하는 것이다.
트랜잭션 동기화 저장소는 작업 스레드마다 독립적으로 Connection 오브젝트를 저장하고 관리하기 때문에 다중 사용자를 처리하는 서버의 멀티스레드 환경에서도 충돌이 날 염려는 없다.
이렇게 트랜잭션 동기화 기법을 사용하면 파라미터를 통해 일일이 Connection 오브젝트를 전달할 필요가 없어진다. 트래잭션의 경계설정이 필요한 Service에서만 Connection을 다루게 하고, 여기에 생성된 Connection과 트랜잭션을 DAO의 JdbcTemplate이 사용할 수 있도록 별도의 저장소에 동기화하는 방법을 적용하기만 하면 된다. 더 이상 로직을 담은 메소드에 Connection 타입의 파라미터가 전달될 필요도 없고, UserDao의 인터페이스에도 일일이 JDBC 인터페이스인 Connection을 사용한다고 노출할 필요가 없다.
스프링은 JdbcTemplate과 더불어 이런 트랜잭션 동기화 기능을 지원하는 간단한 유틸리티 메소드를 제공하고 있다.
1 | private DeataSource dataSource; |
스프링이 제공하는 트랜잭션 동기화 관리 클래스는 TransactionSynchronizationManager다. 이 클래스를 이용해 먼저 트랜잭션 동기화 작업을 초기화하도록 요청한다. 그리고 DataSourceUtils에서 제공하는 getConnection() 메소드를 통해 DB 커넥션을 생성한다. DataSource에서 Connection을 직접 가져오지 않고, 스프링이 제공하는 유틸리티 메소드를 쓰는 이유는 이 DataSourceUtils의 getConnection() 메소드는 Connection 오브젝트를 생성해줄 뿐만 아니라 트랜잭션 동기화에 사용하도록 저장소에 바인딩해주기 때문이다.
트랜잭션 동기화가 되어 있는 채로 JdbcTemplate을 사용하면 JdbcTemplate의 작업에서 동기화시킨 DB 커넥션을 사용하게 된다.
JdbcTemplate은 영리하게 동작하도록 설계되어 있다. 만약 미리 생성돼서 트랜잭션 동기화 저장소에 등록된 DB 커넥션이나 트랜잭션이 없는 경우에는 JdbcTemplate이 직접 DB 커넥션을 만들고 트랜잭션을 시작해서 JDBC 작업을 진행한다. 반면에 upgradeLevels() 메소드에서처럼 트랜잭션 동기화를 시작해놓았다면 그때부터 실행되는 JdbcTemplate의 메소드에서는 직접 DB 커넥션을 만드는 대신 트랜잭션 동기화 저장소에 들어 있는 DB 커넥션을 가져와서 사용한다. 이를 통해 이미 시작된 트랜잭션에 참여하는 것이다.
한 개 이상의 DB로의 작업을 하나의 트랜잭션으로 만드는 건 JDBC의 Connection을 이용한 트랜잭션 방식인 로컬 트랜재션으로는 불가능하다. 왜냐하면 로컬 트랜잭션은 하나의 DB Connection에 종속되기 때문이다. 따라서 각 DB와 독립적으로 만들어지는 Connection을 통해서가 아니라, 별도의 트랜잭션 고나리자를 통해 트랜잭션을 관리하는 글로벌 트랜잭션(global transaction)방식을 사용해야 한다. 글로벌 트랜잭션을 적용해야 트랜잭션 매니저를 통해 여러 개의 DB가 참여하는 작업을 하나의 트랜잭션으로 만들 수 있다.
자바는 JDBC 외에 이런 글로벌 트랜잭션을 지원하는 트랜잭션 메니저를 지원하기 위한 API은 JTA(Java Transaction API)를 제공하고 있다.
트랜잭션 매니저는 DB와 메시징 서버를 제어하고 관리하는 각각의 리소스 매니저와 XA 프로토콜을 통해 연결된다. 이를 통해 트랜잭션 매니저가 실제 DB와 메시징 서버의 트랜잭션을 종합적으로 제어할 수 있게 되는 것이다. 이렇게 JTA를 이용해 트랜잭션 매니저를 활용하면 여러 개의 DB나 메시징 서버에 대한 작업을 하나의 트랜잭션으로 통합하는 분산 트랜잭션 또는 글로벌 트랜잭션이 가능해진다.
UserDao가 DAO 패턴을 사용해 구현 데이터 액세스 기술을 유연하게 바꿔서 사용할 수 있게 했지만 UserService에서 트랜잭션의 경계 설정을 해야 할 필요가 생기면서 다시 특정 데이터 액세스 기술에 종속되는 구조가 되고 말았다.
UserService의 코드가 특정 트랜잭션 방법에 의존적이지 않고 독립적일 수 있게 만들려면 어떻게 해야 할까? UserService의 메소드 안에서 트랜잭션 경계설정 코드를 제거할 수는 없다. 하지만 특정 기술에 의존적인 Connection, UserTransaction, Session/Transaction API 등에 종속되지 않게 할 수 있는 방법은 있다.
추상화란 하위 시스템의 공통점을 뽑아내서 분리시키는 것을 말한다. 그렇게 하면 하위 시스템이 어떤 것인지 알지 못해도, 또는 하위 시스템이 바뀌더라도 일관된 방법으로 접할 수가 있다.
스프링은 트랜잭션 기술의 공통점을 담은 트랜잭션 추상화 기술을 제공하고 있다.
1 | public void upgradeLevels() { |
스프링이 제공하는 트랜잭션 경계설정을 위한 추상 인터페이스는 PlatformTransactionManager다. JDBC의 로컬 트랜잭션을 이용한다면 PlatformTransactionManager를 구현한 DataSourceTransactionManager를 사용하면 된다. 사용할 DB의 DataSource를 생성자 파라미터로 넣으면서 DataSourceTransactionManager의 오브젝트를 만든다.
JDBC를 이용하는 경우에는 먼저 Connection을 생성하고 나서 트랜잭션을 시작했다. 하지만 PlatformTransactionManager에서는 트랜잭션을 가져오는 요청인 getTransation() 메소드를 호출하기만 하면 된다. 필요에 따라 트랜잭션 매니저가 DB 커넥션을 가져오는 작업도 같이 수행해주기 때문이다. 여기서 트랜잭션을 가져온다는 것은 일단 트랜잭션을 시작한다는 의미라고 생각하자. 파라미터로 넘기는 DefaultTransactionDefinition 오브젝트는 트랜잭션에 대한 속성을 담고 있다.
이렇게 시작된 트랜잭션은 TransactionStatus 타입의 변수에 저장된다. TransactionStatus는 트랜잭션에 대한 조작이 필요할 때 PlatformTransactionManager 메소드의 파라미터로 전달해주면 된다.
트랜잭션이 시작됐으니 이제 JdbcTemplate을 사용하는 DAO를 이용하는 작업을 진행한다. 스프링의 트랜잭션 추상화 기술은 앞에서 적용해봤던 트랜잭션 동기화를 사용한다. PlatformTransactionManager로 시작한 트랜잭션 동기화 저장소에 저장된다. PlatformTransactionManager를 구현한 DataSourceTransactionManager 오브젝트는 JdbcTemplate에서 사용될 수 있는 방식으로 트랜잭션을 관리해준다. 따라서 PlatformTransactionManager를 통해 시작한 트랜잭션은 UserDao의 JdbcTemplate 안에서 사용된다.
JTATransactionManager는 주요 자바 서버에서 제공하는 JTA 정보를 JNDI를 통해 자동으로 인식하는 기능을 갖고 있다. 따라서 별다른 설정 없이 JTATransactionManager를 사용하기만 해도 서버의 트랜잭션 매니저/서비스와 연동해서 동작한다.
어떤 트랜잭션 매니저 구현 클래스를 사용할지 UserService 코드가 알고 있는 것은 DI 원칙에 위배된다. 자신이 사용할 구체적인 클래스를 스스로 결정하고 생성하지 말고 컨테이너를 통해 외부에서 제공받게 하는 스프링 DI의 방식으로 바꾸자.
기술과 서비스에 대한 추상화 기법을 이용하면 특정 기술환경에 종속되지 않는 포터블한 코드를 만들 수 있다.
애플리케이션 로직의 종류에 따른 수평적인 구분이든, 로직과 기술이라는 수직적인 구분이든 모두 결합도가 낮으며, 서로 영향을 주지 않고 자유롭게 확장될 수 있는 구조를 만들 수 있는 데는 스프링의 DI가 중요한 역할을 하고 있다. DI의 가치는 이렇게 관심, 책임, 성격이 다른 코드를 깔끔하게 분리하는 데 있다.
이런 적절한 분리가 가져오는 특징은 객체지향 설계의 원칙 중의 하나인 단일 책임 원칙(Single Responsibility Principle)으로 설명할 수 있다. 단일 책임 원칙은 하나의 모듈은 한 가지 책임을 가져야 한다는 의미다. 하나의 모듈이 바뀌는 이유는 한 가지여야 한다고 설명할 수도 있다.
단일 책임 원칙을 잘 지키고 있다면, 어떤 변경이 필요할 때 수정대상이 명확해진다. 기술이 바뀌면 기술 계층과의 연동을 담당하는 기술 추상화 계층의 설정만 바꿔주면 된다. 데이터를 가져오는 테이블의 이름이 바뀌었다면 데이터 액세스 로직을 담고 있는 UserDao를 변경하면 된다. 비즈니스 로직도 마찬가지다.
적절하게 책임과 관심이 다른 코드를 분리하고, 서로 영향을 주지 않도록 다양한 추상화 기법을 도입하고, 애플리케이션 로직과 기술/환경을 분리하는 등의 작업은 갈수록 복잡해지는 엔터프라이즈 애플리케이션에는 반드시 필요하다. 이를 위한 핵심적인 도구가 바로 스프링이 제공하는 DI다.
이렇게 스프링의 의존관계 주입 기술인 DI는 모든 스프링 기술의 기반이 되는 핵심엔진이자 원리이며, 스프링이 지지하고 지원하는, 좋은 설계와 코드를 만드는 모든 과정에서 사용되는 가장 중요한 도구다. 스프링을 DI 프레임워크라고 부르는 이유는 외부 설정정보를 통한 런타임 오브젝트 DI라는 단순한 기능을 제공하기 때문이 아니다. 오히려 스프링이 DI에 담긴 원칙과 이를 응용하는 프로그래밍 모델을 자바 엔터프라이즈 기술의 많은 문제를 해결하는 데 적극적으로 활용하고 있기 때문이다.
일반적으로 서비스 추상화라고 하면 트랜잭션과 같은 기능은 유사하거나 사용 방법이 다른 로우레벨의 다양한 기술에 대해 추상 인터페이스와 일관성 있는 잡근 방법을 제공해주는 것을 말한다.
이를 적용하면 어떤 경우에도 UserService와 같은 애플리케이션 계층의 코드는 아래 계층에서는 어떤 일이 일어나는지 상관없이 메일 발송을 요청한다는 기본 기능에 충실하게 작성하면 된다.
서비스 추상화란 이렇게 원활한 테스트만을 위해서도 충분한 가치가 있다. 기술이나 환경이 바뀔 가능성이 있음에도, JavaMail처럼 확장이 불가능하게 설계해놓은 API를 사용해야 하는 경우라면 추상화 계층의 도입을 적극 고려해볼 필요가 있다.
테스트 환경을 만들어주기 위해, 테스트 대상이 되는 오브젝트의 기능에만 충실하게 수행하면서 빠르게, 자주 테스트를 실행할 수 있도록 사용하는 이런 오브젝트를 통틀어서 테스트 대역(test double)이라고 부른다.
대표적인 테스트 대역은 테스트 스텁(test stub)이다. 테스트 스텁은 테스트 대상 오브젝트의 의존객체로서 존재하면서 테스트 동안에 코드가 정상적으로 수행할 수 있도록 돕는 것을 말한다.
많은 경우 테스트 스텁이 결과를 돌려줘야 할 때도 있다. MailSender처럼 호출만 하면 그만인 것도 있지만, 리턴 값이 있는 메소드를 이용하는 경우에는 결과가 필요하다. 이럴 땐 스텁에 미리 테스트 중에 필요한 정보를 리턴해주도록 만들 수 있다.
테스트는 보통 어떤 시스템에 입력을 주었을 때 기대하는 출력이 나오는지를 검증한다.
목 오브젝트는 스텁처럼 테스트 오브젝트가 정상적으로 실행되도록 도와주면서, 테스트 오브젝트와 자신의 사이에서 일어나는 커뮤니케이션 내용을 저장해뒀다가 테스트 결과를 검증하는 데 활용할 수 있게 해준다.
테스트는 테스트의 대상이 되는 오브젝트에 직접 입력 값을 제공하고, 테스트 오브젝트가 돌려주는 출력 값, 즉 리턴 값을 가지고 결과를 확인한다. 테스트 대상이 받게 될 이볅 값을 제어하면서 그 결과가 어떻게 달라지는지 확인하기도 한다. 문제는 테스트 대상 오브젝트는 테스트로부터만 입력을 받는 것이 아니라는 점이다. 테스트가 수행되는 동안 실행되는 코드는 테스트 대상이 의존하고 있는 다른 의존 오브젝트와도 커뮤니케이션하기도 한다.
때론 테스트 대상 오브젝트가 의존 오브젝트에게 출력한 값에 관심이 있을 겨웅가 있다. 또는 의존 오브젝트를 얼마나 사용했는가 하는 커뮤니케이션 행위 자체에 관심이 있을 수가 있다. 문제는 이 정보는 테스트에서는 직접 알 수가 없다는 것이다. 이때는 테스트 대상과 의존 오브젝트 사이에 주고받는 정보를 보존해두는 기능을 가진 테스트용 의존 오브젝트인 목 오브젝트를 만들어서 사용해야 한다. 테스트 대상 오브젝트의 메소드 호출이 끝나고 나면 테스트는 목 오브젝트에게 테스트 대상과 목 오브젝트 사이에서 일어났던 일에 대해 확인을 요청해서, 그것을 테스트 검증 자료로 삼을 수 있다.
목 오브젝트를 이용한 테스트라는 게, 작성하기는 간단하면서도 기능은 상당히 막강하다는 사실을 알 수 있을 것이다. 보통의 테스트 방법으로는 검증하기가 매우 까다로운 테스트 대상 오브젝트의 내부에서 일어나는 일이나 다른 오브젝트 사이에서 부고받은 정보까지 검증하는 일이 손쉽기 때문이다.