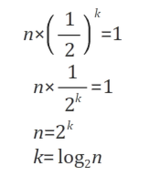큐는 여러개의 데이터를 넣을 수 있는 자료구조 입니다. 데이터가 넣고 뺄때는 First In First Out(FIFO) 구조를 가집니다.
우선순위 큐는 이러한 큐의 한종류로써 최대 우선순위 큐와 최소 우선순위 큐로 나뉩니다.
최대 우선순위 큐
최대 우선순위 큐는 다음의 두가지 연산을 지원하는 자료구조 입니다. (최소 우선순위 큐는 EXTRACT-MAX 대신 EXTRACT-MIN을 지원하는 자료구조입니다.)
INSERT(x) : 새로운 원소 x를 삽입
EXTRACT_MAX() : 최대값을 삭제하고 반환
MAX HEAP을 이용해서 최대 우선순위 큐를 구현할 수 있습니다.
INSERT
위의 그림은 MAX HEAP의 형태로 저장되어 있는 우선순위 큐 입니다. 현재 heap은
complete binary tree
max heap property 조건을 만족하기 때문에 이를 유지하면서 INSERT 연산을 하기 위해서는 고려할 사항들이 있습니다.
INSERT는 새로운 노드를 추가해야하는데 complete binary tree 를 만족하기 위해서는 가장 마지막 레벨의 leaf에 추가 될 수 밖에 없습니다. 그리고 새로운 노드가 추가된 후 max heap property를 만족하기 위해서는 max-heapify 연산이 필요합니다. INSERT의 의사 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9
MAX-HEAP-INSERT(A, key){ heap_size = heap_size + 1; A[heap_size] = key; i = heap_size; while(i > 1and A[PARENT(i)] < A[i]){ exchange A[i] and A[PARENT(i)]; i = PARENT(i); } }
위의 코드에서 A는 heap의 사이즈를 1증가 시키고, 그 자리에 새로운 key값을 넣습니다. i는 새로 추가된 노드의 인덱스입니다. 그 후 while 문에서 i > 1 (root 노드가 아니라는 의미) 이며, A[PARENT(i)] < A[i] (부모 노드에 저장된 값보다 크다는 의미) 라면 부모 노드와 값을 교환합니다.
즉, 루트 노드가 될 때까지 혹은 자신의 부모 노드보다 작을 때 까지 계속해서 교환연산을 진행합니다. 따라서 시간 복잡도는 트리의 높이에 비례하게 되고, heap은 complete binary tree이므로 O(nlogn)입니다.
EXTRACT_MAX
위의 그림은 EXTRACT_MAX 과정을 나타내고 있습니다. heap은 complete binary tree 성질을 유지하기 위해서 아무 노드나 삭제하는 것이 아니라 마지막 노드를 삭제하게 됩니다. 이때 루트 노드와 마지막 노드의 자리를 변경해 마지막 노드를 삭제 후 max-heapify를 통해 다시 max heap property를 만족하도록 만들 수 있습니다. HEAP-EXTRACT-MAX의 의사 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9
HEAP-EXTRACT-MAX(A){ if heap-size[A] < 1 then error "heap underflow" max <- A[1] A[1] <- A[heap-size[A]] heap-size[A] <- heap-size[A] - 1 MAX-HEAPIFY(A, 1) return max }
저번 포스팅에서는 힙(Heap)과 max-heapify에 대해 알아보았습니다. 이번 포스팅에서는 직접 1차원 배열을 heap 구조로 변경한 후 힙 정렬을 해보겠습니다.
1차원 배열을 힙(Heap) 으로 만들기
먼저 의사 코드는 다음과 같습니다.
1 2 3 4
BUILD-MAX-HEAP heap-size[A]<-length[A] for i <- |length[A]/2| downto 1 do MAX-HEAPIFY(A,i)
i가 A 배열의 길이 / 2 부터 시작하는 이유는 리프 노드에서는 max-heapify 과정이 필요 없기 때문입니다.
힙을 만드는데의 시간 복잡도는 다음과 같습니다. MAX-HEAPIFY 연산의 시간 복잡도는 log(n) 입니다. 그런데 for 문이 n/2 돌기 때문에 n/2*log(n)이며 빅 오로 표기하면 O(n*log(n))이 됩니다. 이는 루트 노드만 고려하여 상당히 러프하게 계산한 것이기 때문에, 정확하게 계산한다면 시간 복잡도는 **O(n)**이 됩니다.
힙 정렬(Heap sort) 하기
힙 정렬은 다음과 같은 순서로 실행됩니다.
주어진 데이터를 힙으로 만든다
힙에서 최대값(루트 노드)을 가장 마지막 값과 바꾼다.
힙의 크기가 1 줄어든 것으로 간주한다. 즉, 마지막 값은 힙의 일부가 아닌것으로 간주한다.
루트 노드에 대해서 HEAPIFY(1)한다.
2~4번을 반복한다.
데이터를 힙으로 만들면 인덱스 1의 값이 가장 최대값 이므로 마지막 값과 바꿉니다. 그리고 마지막값은 정렬된 값으로 간주하고 더 이상 신경쓰지 않아도 됩니다. 그렇게 줄여나간다면 결국 정렬된 상태의 배열이 완성됩니다.
힙 정렬의 의사 코드는 다음과 같습니다.
1 2 3 4 5 6
HEAPSORT(A) BUILD-MAX-HEAP(A) // O(n) for i <-heap-size downto 2do// n-1 times exchange A[1] <-> A[i] // O(1) heap_size <- heap_size -1// O(1) MAX-HEAPIFY(A,1) // O(log(n))
힙 정렬은 힙, 바이너리 힙, 이진 힙이라고 부르는 자료구조를 이용하는 정렬 알고리즘입니다.
힙 정렬의 특징은 다음과 같습니다. 1.최악의 경우에도 시간 복잡도가 nlogn이 되는 빠른 정렬이다. 2.힙 정렬은 알고리즘을 구현하는데 추가적인 배열이 필요하지 않다. 3.이진 힙(바이너리 힙) 자료구조를 사용한다.
먼저 힙 정렬을 구현하기 전에, 힙 이라는 자료구조에 대해 알아보겠습니다.
힙(Heap) 이란?
힙(Heap)은
complete binary tree(완전 이진 트리) 이면서
heap property를 만족해야 합니다.
위의 그림에서는 **full binary tree(포화 이진 트리)**와 **complete binary tree(완전 이진 트리)**에 대해 설명하고 있습니다.
binary tree(이진 트리)란 한 노드가 최대 2개의 자식 노드를 가지는 트리 입니다. 따라서, 위의 2개 트리는 모두 이진 트리입니다. 이진 트리는 이진 탐색 트리(BST)와 이진 힙(Binary Heap)의 구현에 흔히 사용됩니다.
full binary tree(포화 이진 트리)란 이진 트리중에 모든 레벨의 노드 들이 꽉 차있는 형태를 말합니다.
complete binary tee(완전 이진 트리)는 마지막 레벨을 제외하면 완전히 꽉 차있고, 마지막 레벨에는 가장 오른쪽 부터 연속된 몇개의 노드가 비어있을 수 있는 트리를 말합니다. 따라서 포화 이진 트리는 완전 이진 트리이기도 합니다.
위의 2번째 조건에서 heap property를 만족해야 한다고 했습니다. 이 heap property는 2개의 조건으로 나누어집니다.
max heap property - 부모 노드는 자식 노드보다 데이터가 크거나 같다.
min heap property - 부모 노드는 자식 노드보다 데이터가 크거나 작다.
max와 min 모두 대칭적 관계이므로 모든 알고리즘에 적용되나 상황에 따라서 간단하게 사용할 수 있는 것을 씁니다. 여기서는 max-heap property를 다루겠습니다.
(a)의 3개 트리는 모두 heap 입니다. (완전 이진 트리이면서 heap property를 만족합니다.) (b)의 3개 트리는 heap이 아닙니다. (완전 이진 트리이지만, (max)heap property를 만족하지 않습니다.) (c)의 2개 트리도 heap이 아닙니다. (완전 이진 트리를 만족하지 않습니다.)
위의 (a), (b), (c)는 모두 다 heap입니다. (a), (b), (c)는 동일한 데이터를 갖고 있는 서로 다른 heap입니다. 즉, 여러가지 모양의 heap이 존재할 수 있는 것입니다.
Heap은 1차원 배열을 사용해 표현할 수 있습니다. 같은 레벨에서 왼쪽부터 배열로 저장하면 1차원 배열이 됩니다. 일반적인 트리에서는 부모 자식간의 관계를 식을 통해 표현할 수 없지만 Heap은 complete binary tree이므로 배열의 인덱스만으로 부모와 자식의 관계를 표현할 수 있습니다. 루트 노드가 배열의 1번 인덱스부터 시작한다면 다음과 같은 표현식을 사용할 수 있습니다.
루트 노드 : A[1]
A[i]의 부모 노드 : A[i/2]
A[i]의 왼쪽 자식 노드 : A[2i]
A[i]의 오른쪽 자식 노드 : A[2i+1]
따라서 Heap은 1차원 배열을 통해 표현이 가능하기 때문에 불필요하게 트리 자료구조를 따로 만들어 사용해 구현할 필요가 없습니다.
Max-heapify 란?
지금부터는 어떤 1차원 배열의 데이터가 있을 때 이 1차원 배열을 Heap으로 변환하는 과정에 대해 알아보겠습니다. (이번 포스팅에서는 max heap만을 다루기로 했으므로 max heap을 만드는 방법에 대해 알아보겠습니다.) 일반 1차원 배열은 max-heapify라는 연산 과정을 통해 max heap으로 만들수 있습니다.
max-heapify 연산을 하기 위한 전제조건을 위의 그림에서 보여주고 있습니다.
트리의 전체 모양은 complete binary tree이다.
왼쪽 서브 트리(subtree)는 그 자체로 heap이다.
오른쪽 서브 트리(subtree)는 그 자체로 heap이다.
여기서 유일하게 루트 노드만이 heap property를 만족하지 않을때, max-heapify 연산을 통해 heap property를 만족하게 만들 수 있습니다.
위의 그림에서 루트 노드는 자신의 자식 노드중에 더 큰값과 자리를 교체 합니다. 그 후 교체된 노드에서 다시 max-heapify 연산을 통해 max-heap property를 만족할 때까지 반복합니다.
결국 max-heapify는 동일한 과정을 반복하고 있기 때문에 **recursion(재귀)**로 구현이 가능합니다.
1 2 3 4 5 6 7 8 9
MAX-HEAPIFY(A, i){ if there is no child of A[i] return; k <- index of the biggest child of i; if A[i]>=A[k] return; exchange A[i] and A[k]; MAX-HEAPIFY(A, k); }
첫번째 조건은 base case로서, 자식 노드가 없다면 가장 아래의 레벨에 위치한 리프노드이기 때문에 종료합니다. 만약 자식 노드가 있다면 큰 자식 노드의 인덱스를 k로 지정합니다. 그 후 부모 노드와 값을 비교해 부모 노드가 크다면 max-heapify 과정을 종료하고, 자식 노드의 값이 크다면 부모 노드와 값을 교환한 후 다시 max-heapify를 재귀 호출 합니다.
1 2 3 4 5 6 7 8 9
MAX-HEAPIFY(A, i){ while A[i] has a child do k<- index of the biggest child of i; if A[i]>= A[k]; return; exchange A[i] and A[k]; i=k; end }
같은 함수를 iterate하게 구현한 코드입니다. 주요 함수의 동작 원리는 같습니다.
max-heapify의 시간 복잡도는 루트 노드로부터 마지막 레벨까지 비교, 교환 연산을 하므로 트리의 높이보다 많은 시간이 필요하지 않습니다. 따라서 시간 복잡도는 높이에 의해서 결정되며, O(h)입니다. 일반적인 이진트리가 아닌 complete binary tree이므로 노드의 개수를 n이라 하면, **시간 복잡도는 O(logn)**이 됩니다.
퀵 정렬은 합병 정렬과 마찬가지로 분할정복법을 사용하지만 그 방법에 있어서 차이가 있습니다. 퀵 정렬에서는 정렬할 데이터가 주어지면 하나의 값을 기준값(pivot)으로 사용하여 정렬을 합니다. 어떤 값을 기준값으로 설정하는지가 퀵정렬의 성능을 좌우합니다.
분할정복법 3단계를 바탕으로 퀵정렬의 과정을 알아보겠습니다.
분할 : 하나의 값을 기준값(pivot)으로 설정 한 후 데이터들을 기준값보다 큰 값과 작은값으로 분류한다.
정복 : 분할한 양쪽을 각각 재귀로 퀵 정렬한다.
합병 : 이미 분할 과정에서 정렬이 완료되었기 때문에 따로 과정이 없다.
퀵 정렬 의사 코드
의사 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12
quickSort(A[], p, r) { if(p<r) then{ q = partition(A, p, r); // 분할 quickSort(A, p, q-1); // 왼쪽 부분배열 정렬 quickSort(A, q+1, r); // 오른쪽 부분배열 정렬 } }
partition(A[], p, r) { 배열 A[p...r]의 원소들을 A[r]을 기준으로 양쪽으로 재배치하고 A[r]이 자리한 위치를 return }
배열 A의 인덱스 p에서 r사이에 있는 데이터를 정렬합니다. 조건문으로 p가 r보다 작은 경우에만 알고리즘이 실행되도록 합니다. 다음으로 partion 함수는 기준값(pivot)을 기준으로 전체 데이터를 나눠주고 피봇 인덱스를 반환하는 역할을 합니다. 따라서, q는 피봇이 됩니다.
[p, q-1] 은 배열의 왼쪽 부분, 작은 값이고 [q+1, r] 까지는 배열의 오른쪽 부분, 큰 값입니다. 재귀적으로 quickSort 함수를 호출해 정렬합니다.
위의 그림에서 기준값(pivot)으로 인덱스의 마지막 값을 사용하고 있습니다. 위의 그림 기준에서 현재 인덱스 j의 값이 기준값보다 크다면 j를 증가시켜 다음값으로 넘어갑니다. 그러나 인덱스 j의 값이 기준값보다 작다면 앞쪽으로 보내야하는데, 이때 i값을 1 증가 시킨 후 그 값과 교환합니다.
위의 과정은 기준값을 마지막 인덱스의 값인 15로 설정하고 i와 j를 증가시키면서 정렬하는 과정을 보여줍니다. 모든 정렬이 완료되면 인덱스 i+1의 값과 기준값의 위치를 변경합니다.
1 2 3 4 5 6 7 8 9 10
Partition(A, p, r){ x<-A[r]; i<-p-1; for j<-p to r-1 if A[j] <= x then i<-i+1; exchange A[i] and A[j]; exchange A[i+1] and A[r]; return i+1; }
Partition 함수를 더 자세한 의사 코드로 나타냈습니다. 앞서 설명한 위치 변환과 인덱스 증가로 정렬을 완료하고 마지막으로 기준값(pivot)의 인덱스를 리턴합니다.
퀵 정렬 c++ 코드
이제 의사 코드를 바탕으로 c++ 코드를 작성하면 다음과 갖습니다. (의사 코드와는 완전히 일치하지는 않습니다.)
퀵 정렬에서의 시간 복잡도는 파티션(분할) 하는데 모든 데이터를 한번씩 비교하면 되므로 n이 됩니다. 정확하게 말하자면 데이터의 개수가 n개일때, n-1 번의 비교가 이루어집니다.
합병 정렬보다는 시간 복잡도를 구하는게 조금 더 복잡한데, 합병 정렬은 항상 2개로 나뉘는것과 달리 퀵 정렬은 항상 양쪽이 고르게 나누어지지 않기 때문입니다.
먼저 최악의 경우부터 생각해보면 모든 배열이 정렬되어있을 때, 기준값이 최대/최소 값일 때, 최악의 시간 복잡도가 발생합니다. 분할은 0개와 나머지 전체로 나누어지므로 결국 데이터는 아무변화가 없고 똑같은 루틴이 반복되기 때문에 시간 복잡도는 **O(n^2)**가 됩니다.
반대로 최선의 경우는 항상 절반으로 분할되는 경우로, 이 때는 합병 정렬과 동일한 시간인 **O(nlogn)**의 시간을 같습니다.
퀵 정렬은 다른 정렬 알고리즘보다 대체로 빠르기 때문에 퀵 정렬 이라는 이름이 붙었습니다. 그렇지만 최악의 경우에는 O(n^2)의 느린 속도를 보여줬는데 왜 퀵 정렬이 다른 알고리즘 보다 빠른 걸가요?
최선의 경우와 최악의 경우는 극단적인 케이스라서 실제적으로 일어나기 어려운 상황입니다.
현식적으로 가정했을 때, n개의 데이터가 항상 9:1로 분할 된다고 하면 한 단계 당 분할되는 시간을 구하면 항상 n이므로 전체 비교 연산은 트리의 깊이 * n 입니다. 트리는 대칭적이지 않으므로 가장 깊은 오른쪽 경로(최악의 경우)를 예로 들면 (9/10)^k * n = 1이 됩니다. 따라서 시간 복잡도 k = log9/10(n)이 됩니다.
이 예가 의미하는 것은 퀵 정렬의 성능은 파티션이 얼마나 밸런스있게 나뉘냐에 결정된다는 것입니다. 극단적인 경우만 아니라면 퀵 정렬의 시간 복잡도는 nlogn 이 되므로 실제로 상당히 빠른 정렬 방법이 됩니다.
합병 정렬은 앞서 알아본 선택, 삽입, 버블 정렬과는 다르게 분할정복법이라는 개념을 사용합니다.
**분할정복법(Divide-And-Conquer)**이라는 것은 주어진 문제를 다음과 같은 3단계의 절차를 통해 해결하는 방법입니다.
분할 : 해결하고자 하는 문제를 작은 크기의 동일한 문제들로 분할한다.
정복 : 각각의 작은 문제를 순환적으로 해결한다.
합병 : 작은 문제의 해를 합하여(merge) 원래 문제에 대한 해를 구한다.
그럼 이를 토대로 합병 정렬의 과정을 살펴보겠습니다.
합병 정렬은 여러 개의 데이터를 한 번에 정렬하는 것이 아닌 이를 계속해서 반으로 나눈 후 다시 합병하는 과정에서 정렬이 이루어집니다.
분할을 반복하다보면 마지막은 길이가 1인 구간으로 나뉘어집니다. 더이상 분할이 불가능할때 다시 합병하면서 정렬을 하는것입니다. 그렇기 때문에 합병 정렬에서 가장 중요한 부분은 실제 정렬을 수행하는 **합병(merge)**하는 과정입니다.
그럼 합병과정에서 정렬은 어떻게 이루어질까요? 다음 그림을 통해서 실제 정렬이 이루어지는 합병 과정을 좀 더 자세히 알아보겠습니다.
먼저 위 그림은 합병이 이루어 지기 위한 이미 정렬된 2개의 블록이 존재하는 모습입니다. 현재 두개의 블록은 이미 길이가 1인 구간으로 나눠진 배열부터 시작해 각각 합병 과정을 거쳐 정렬된 상태로 만들어진 배열입니다. 이 두개의 블록을 정렬된 상태를 유지하며 합치기 위해서는 i 인덱스에 있는 값과, j 인덱스에 있는 값을 하나씩 비교한 후 추가배열에 저장하면 됩니다.
위 그림처럼 하나의 블록이 모두 합쳐 졌을 경우 나머지 블록은 순서대로 배열에 저장하면 됩니다.
voidprint_arr(int a[], int size){ for (int i = 0; i < size; i++) { cout << a[i] << ' '; } cout << '\n'; }
voidmerge(int a[], int left, int mid, int right){ int i, j, k;
i = left; j = mid + 1; k = left;
int tmp_arr[ITEM_SIZE];
// left 부터 mid 까지의 블록과 mid + 1 부터 right 까지의 블록을 서로 비교 while (i <= mid && j <= right) { if (a[i] <= a[j]) { tmp_arr[k] = a[i]; i++; } else { tmp_arr[k] = a[j]; j++; } k++; }
// left 블록의 값이 다 처리되었지만, right 블록의 index가 남아 있는 경우 // right 블록의 남은 부분을 순차적으로 tmp_arr에 복사 if (i > mid) { for (int m = j; m <= right; m++) { tmp_arr[k] = a[m]; k++; } } // left 블록의 남은 부분을 순차적으로 tmp_arr에 복사 else { for (int m = i; m <= mid; m++) { tmp_arr[k] = a[m]; k++; } }
// 임시 배열인 tmp_arr의 값을 원본 배열에 복사한다. for (int m = left; m <= right; m++) { a[m] = tmp_arr[m]; } }
voidmerge_sort(int a[], int left, int right){ int mid;
if (left < right) { // 절반으로 나누기 위해 중간 위치 찾기 mid = (left + right) / 2;
// 분할 merge_sort(a, left, mid); merge_sort(a, mid + 1, right);
이제 마지막으로 합병 정렬의 시간 복잡도를 알아보겠습니다. 데이터가 n개 일때 합병 정렬로 계산하는 시간을 T(n)이라고 하겠습니다. 정렬을 위해서 반으로 분할한 후 n/2개의 블럭에 재귀함수를 호출하면, 반으로 분할된 블럭 2개에 대한 정렬을 수행해야하므로 **T(n/2) + T(n/2)**의 시간이 걸립니다. 두개의 정렬된 블럭을 merge할 때 두 블럭을 한번씩 비교하므로 merge 시간은 n입니다. 따라서, merge sort의 시간 복잡도는 T(n) = T(n/2) + T(n/2) + n이 됩니다.
결국 분할을 반복하면 위와 같은 그림의 식을 도출할 수 있고, 이 식을 수학적으로 풀어보면 **O(nlogn)**이 됩니다.
합병 정렬과 퀵 정렬 비교
아직 퀵 정렬에 대해 다루지 않았지만 합병 정렬과 퀵 정렬 모두 시간 복잡도로 **O(nlogn)**을 갖습니다. 그러나 퀵 정렬과 합병 정렬에는 서로 다른 특징이 있습니다.
합병 정렬은 합병 과정에서 임시적인 저장공간으로 데이터를 담고 있는 배열과 같은 크기인 추가 배열을 사용하기 때문에 **추가적인 메모리가 필요**합니다. 그러나 퀵 정렬은 추가 메모리를 사용하지 않고 내부 교환만으로 수행되는 차이가 있습니다.
또한 합병 정렬은 어떤 상황이라도 항상 **O(nlogn)**의 시간 복잡도를 갖지만 퀵 정렬의 경우 아이러니하게도 정렬하기 위해 정렬이 되어 있는 데이터를 사용할 경우 **O(n^2)**의 시간복잡도를 갖게 됩니다. (이 경우는 다음에 퀵 정렬에 대해 포스팅하며 알아보겠습니다.) 그러나 최악의 경우가 아닐 경우 일반적으로 퀵 정렬이 합병 정렬에 비해 빠른 성능을 보입니다.
합병 정렬은 퀵 정렬보다 성능이 전반적으로 떨어지고, 데이터 크기만한 메모리가 더 필요하지만 최대의 장점은 **stable sort**라는 점입니다. 퀵 정렬의 경우 만약 배열 A[25] = 100, A[33] = 100 인 정수형 배열을 정렬한다고 할 때, 33번째에 있던 100이 25번째에 있던 100보다 앞으로 오는 경우가 생길 수 있습니다. 그에 반해서 합병 정렬은 이전의 순서를 유지하면서 정렬된 상태를 만들 수 있습니다.
선택 정렬은 해당 순서에 원소를 넣을 위치는 이미 정해져 있고, 어떤 원소를 넣을지 선택한다라고 생각하면 이해하기 쉽습니다.
현재 위의 예시에서는 각 순서마다 정렬되지 않은 범위에서 가장 큰 원소를 찾아 맨 마지막 값의 자리와 변경합니다. 가장 큰값을 찾아 맨 오른쪽 원소와 변경해 오름차순으로 정렬했지만, 매 순서마다 가장 작은 값을 찾아 맨 왼쪽의 원소와 변경해주어도 오름차순 정렬을 구현할 수 있습니다.
순서를 간략히 정리하면 다음과 같습니다 각 루프마다 1.최대 원소를 찾는다. 2.최대 원소와 맨 오른쪽 원소를 교환한다. 3.맨 오른쪽 원소를 제외한다. 하나의 원소만 남을 때까지 위의 루프를 반복
의사 코드는 다음과 같습니다.
1 2 3 4 5 6
selectionSort(A[], n) { for last <- downto 2 { A[1...last] 중 가장 큰 수 A[k]를 찾는다 A[K] <-> A[last]; A[k]와 A[last]값을 교환 } }
시간 복잡도를 계산한다면 1)for 루프는 n-1번 반복 되고 2)가장 큰 수를 찾기 위한 비교 횟수는 n-1, n-2, … , 2, 1 3)교환은 상수 시간 작업이므로
이제 마지막으로 c++ 코드로 작성하면 다음과 같습니다. (위의 예시에서는 매 순서마다 가장 값이 큰 원소를 가장 오른쪽 원소와 변경함으로써 오름차순 정렬을 구현했지만, 아래의 코드에서는 매 순서마다 가장 값이 작은 원소를 가장 왼쪽의 원소와 변경함으로써 오름차순 정렬을 구현했습니다.)
삽입 정렬은 매 순서마다 해당 원소를 삽입할 수 있는 위치를 찾아 해당 위치에 넣는다고 이해하면 쉽습니다. (선택 정렬은 위치가 정해져있고 이 위치에 어떤 원소를 넣을지 선택하는 것이었다면, 삽입 정렬은 원소는 정해져있고 이 원소를 어디에 넣을지 선택하는 것이라고 이해하면 될 것 같습니다.)
위의 그림은 삽입 정렬의 전체적인 과정을 보여주는 것이고, 아래 사진은 삽입 정렬의 전체과정 중 한 과정을 상세하게 보여주고 있습니다.
이번에 선택된 원소는 4이고, 이 원소를 어떤 자리에 삽입할지 탐색하는 과정을 보여줍니다.
삽입 정렬의 의사 코드는 다음과 같습니다.
1 2 3 4 5
insertionSort(A[], n){ for i<- 2 to n{ A[1...i]의 적당한 자리에 A[i]를 삽입한다. } }
시간 복잡도를 계산한다면 1)for 루프는 n-1번 반복 되고 2)최악의 경우 데이터 삽입을 위한 비교는 i-1번 비교
따라서 최악의 경우 T(n) = (n-1) + (n-2) + … + 2 + 1 = n(n-1)/2 = O(n^2)
버블 정렬은 선택 정렬과 기본 개념이 비슷합니다. 버블 정렬에서도 선택 정렬과 같이 이미 해당 순서에 원소를 넣을 위치는 정해져 있고, 어떤 원소를 넣을지 선택한다라고 생각하면 됩니다. 다만 선택 정렬과는 다르게 최대값을 찾고, 그 최대값을 맨 마지막 원소와 교환하는 과정에서 차이가 있습니다.
버블 정렬의 의사 코드는 다음과 같습니다.
1 2 3 4 5 6
bubbleSort(A[], n){ for last <- downto 2{ for i <- 1 to last - 1 if(A[i]>A[i+1]) then A[i] <-> A[i+1] // 교환 } }
시간 복잡도를 계산한다면 1)바깥 for 루프는 n-1번 반복 되고 2)안쪽 for 루프는 n-1, n-2, …, 2, 1번 반복 3)원소 교환은 상수시간 작업
에라토스테네스의 체는 매우 간단한 아이디어입니다. 위에서 모든 자연수는 소수들의 곱으로 표현이 된다고 했습니다. 제일 작은 소수 2부터 시작합니다. 2부터 N-1까지의 수 중에서 2의 배수를 모두 체로 거르고 남은 숫자들 중에서 3의 배수로 거르고를 반복해서 제곱근N 까지 나눠서 걸러지지 않고 남은 수들이 모두 소수가 됩니다.
주어진 배열에서 특정한 요소(target) 을 찾아내는 상황을 가정해 봅시다. 가장 쉬운 방법은 각각의 배열 요소와 target 값을 같은지 순차적으로 모두 비교하는 것입니다. 만약 배열의 크기가 n이라고 했을때, 이 알고리즘의 시간복잡도를 Big-O notation을 이용해 나타낸다면 **O(n)**이 될 것 입니다. 그러나 더 효율적이고 빠르게 target 을 찾아내는 방법이 있습니다. 이 방법은 매 탐색마다 target을 찾기위한 배열의 크기를 절반으로 줄여가면서 탐색을 하는 것입니다. 정확히는 기존의 배열은 유지하지만 탐색해야하는 범위를 계속 절반으로 줄이는 것입니다. 이런식으로 탐색하는 방법이 바로 이진 탐색(Binary Search) 알고리즘입니다. 다만 이진 탐색 알고리즘은 순차 탐색과는 달리 배열의 데이터들이 정렬된 상태에서만 적용할 수 있다는 특징이 있습니다. 정렬이 되지 않은 데이터는 이진 탐색을 적용할 수 없습니다. 쉽게 생각해보면 만약 배열의 요소들이 정렬되지 않은 상태라면, 매 탐색마다 target을 찾기 위해 검사해야하는 배열의 범위를 줄이지 못할 것입니다. (정렬되어 있다 라는 기준이 없기 때문에 탐색해야 하는 배열의 시작과 끝 범위를 정할 수 있는 근거가 없기 때문입니다.)
이진 탐색 절차
크기가 n인 리스트 data에서 target 이라는 특정 요소를 찾아낸다고 가정했을 때, 이진 탐색의 절차는 다음과 같습니다. (리스트는 오름차순으로 정렬되어 있습니다.)
begin = 0, end = n − 1 로 초기화 합니다.
mid 는 (begin + end) 를 2 로 나눈 몫으로 결정합니다.
data[mid] 와 target 이 서로 같으면 목적을 달성했으므로 탐색을 종료합니다.
만약 target < data[mid] 이면 end = mid-1 로 업데이트 한 후, 2번으로 돌아갑니다. 만약 target > data[mid] 라면 begin = mid+1 로 업데이트 한 후, 2번으로 돌아갑니다.
위 과정에서 begin, end, mid는 리스트의 index를 의미합니다. 또한 target과 data[mid]의 대소관계에 따라 다음 탐색 방향을 선택하게 됩니다. 이 과정은 리스트의 요소가 오름차순인지 내림차순인지에 따라 다르게 구현됩니다.
먼저 코드를 작성하기 전에 그림과 함께 과정을 살펴보겠습니다.
위의 리스트에서 15라는 데이터를 탐색하겠습니다. 먼저 첫번째 과정으로 데이터 집합의 중앙 요소를 선택합니다.
두번째 과정으로는 중앙 요소의 값과 찾으려는 값을 서로 비교하게 되는데, 만약 찾으려는 값이 중앙 요소의 값보다 작다면 중앙 요소의 왼편에서 중앙 요소를 다시 선택하고, 반대로 찾으려는 값이 중앙 요소의 값보다 크다면 오른편에서 중앙 요소를 다시 선택합니다. 그리고 다시 이 과정을 반복하는 것입니다. 위의 경우에는 찾으려는 값인 15가 중앙값 9보다 크기 때문에 중앙값 왼편은 탐색할 필요가 없습니다. 따라서 중앙 요소의 오른편에서 다시 중앙값을 선택합니다.
이제는 중앙값이 17입니다. 중앙값이 찾고자 하는 값인 15보다 크기 때문에 중앙값 왼편에서 다시 테이터를 탐색합니다.
왼편에서 중앙값을 택합니다. 이제 중앙값과 찾고자 하는 데이터가 같기 때문에 탐색을 종료합니다.
이진 탐색 성능
이진 탐색은 한번 비교를 할때마다, 탐색의 범위가 반으로 줄어듭니다. 데이터 리스트의 크기를 n이라 하고, 반복 횟수를 k라고 한다면 다음과 같은 수식이 만들어 집니다. 위는 데이터 리스트의 크기인 n을 2로 몇번을 나누어야 1이 되는지 말해주는 식으로, 위 수식을 정리하면 k=log2(n)이 되는 것입니다. 위 수식을 통해 데이터 리스트의 크기가 500만개라면 최대 22회, 1000만개라면 최대 23회의 탐색으로 데이터를 찾아낼 수 있다는 것입니다.
의사 코드 (수도 코드)
먼저 의사 코드를 살펴보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12
BinarySearch(A[0...N-1], target, begin, end) { if (begin > end) return -1 // not found mid = (begin + end) / 2 if (A[mid] < target) return BinarySearch(A, target, mid+1, end) else if (A[mid] > target) return BinarySearch(A, target, begin, mid-1) else return mid // found }
째로탈출2처럼 코드가 깁니다… 째로탈출2와 마찬가지로 2차원 배열을 조작하는 부분에서 코드가 많이 길어지게 되는데 더 간결하게 만들 수 있도록 연습을 해야할 것 같습니다. 구현은 combine_map함수를 통해서 방향에 맞게 같은 숫자를 합쳐주고 move_map함수를 통해 빈공간을 제거하는것을 반복하도록 구현했습니다. Easy의 경우 5회 반복이기 때문에 대부분 시간초과 경우는 없을 것 입니다. (테스트 케이스가 문제에 1개 밖에 없다보니 힘들었습니다… 테스트 케이스가 부족하신 분들은 문제 게시판에 가시면 더 찾아보실 수 있습니다.)
처음 풀이 방향을 잘못 잡고, 풀이시 여러 예외 사향을 잘못 생각하는 바람에 시간이 오래 걸렸습니다. 코드가 조금 긴 편입니다… 저는 dfs를 활용해서 풀었습니다. 주의해야 할 사항이 몇가지 있었는데, 1. 이미 기울였던 방향과 그 반대방향으로 다시 기울여서는 안된다. (이미 기울였던 방향으로 다시 기울이게 된다면 결과는 같을 것 입니다. 또한 방금 기울였던 방향의 반대로 기울인다면 이전과 같은 상태로 돌아가게 됩니다.) 2. 기울인 후 파란공과 빨간공의 위치가 겹친다면 기울이기 전의 (1) 기울인 방향, (2) 파란공 위치, (3) 빨간공 위치 를 고려하여 다시 위치를 변경해주어야 한다.
intmove_x(int x, int y, int dir){ int nx = x; char type;
if (dir == 0) { for (int i = x - 1; i > 0; i--) { type = map[i][y]; if (type == '#') { break; } elseif (type == 'O') { nx = i; break; } else { nx = i; } } } else { for (int i = x + 1; i < N - 1; i++) { type = map[i][y]; if (type == '#') { break; } elseif (type == 'O') { nx = i; break; } else { nx = i; } } }
return nx; }
intmove_y(int x, int y, int dir){ int ny = y; char type;
if (dir == 2) { for (int i = y - 1; i > 0; i--) { type = map[x][i]; if (type == '#') { break; } elseif (type == 'O') { ny = i; break; } else { ny = i; } } } else { for (int i = y + 1; i < M - 1; i++) { type = map[x][i]; if (type == '#') { break; } elseif (type == 'O') { ny = i; break; } else { ny = i; } } }