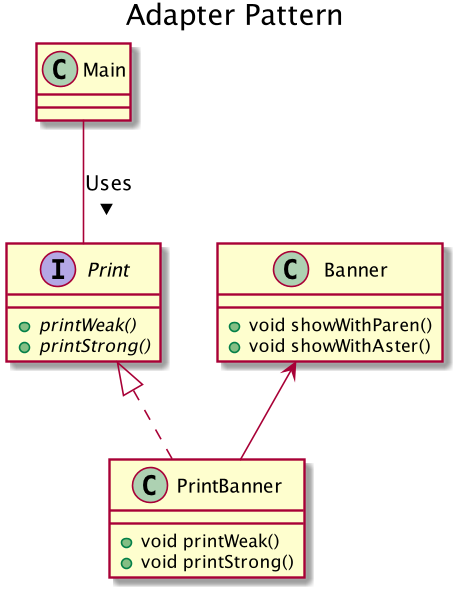
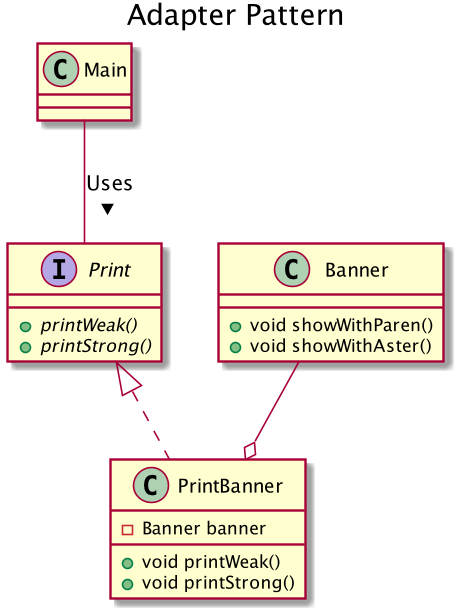
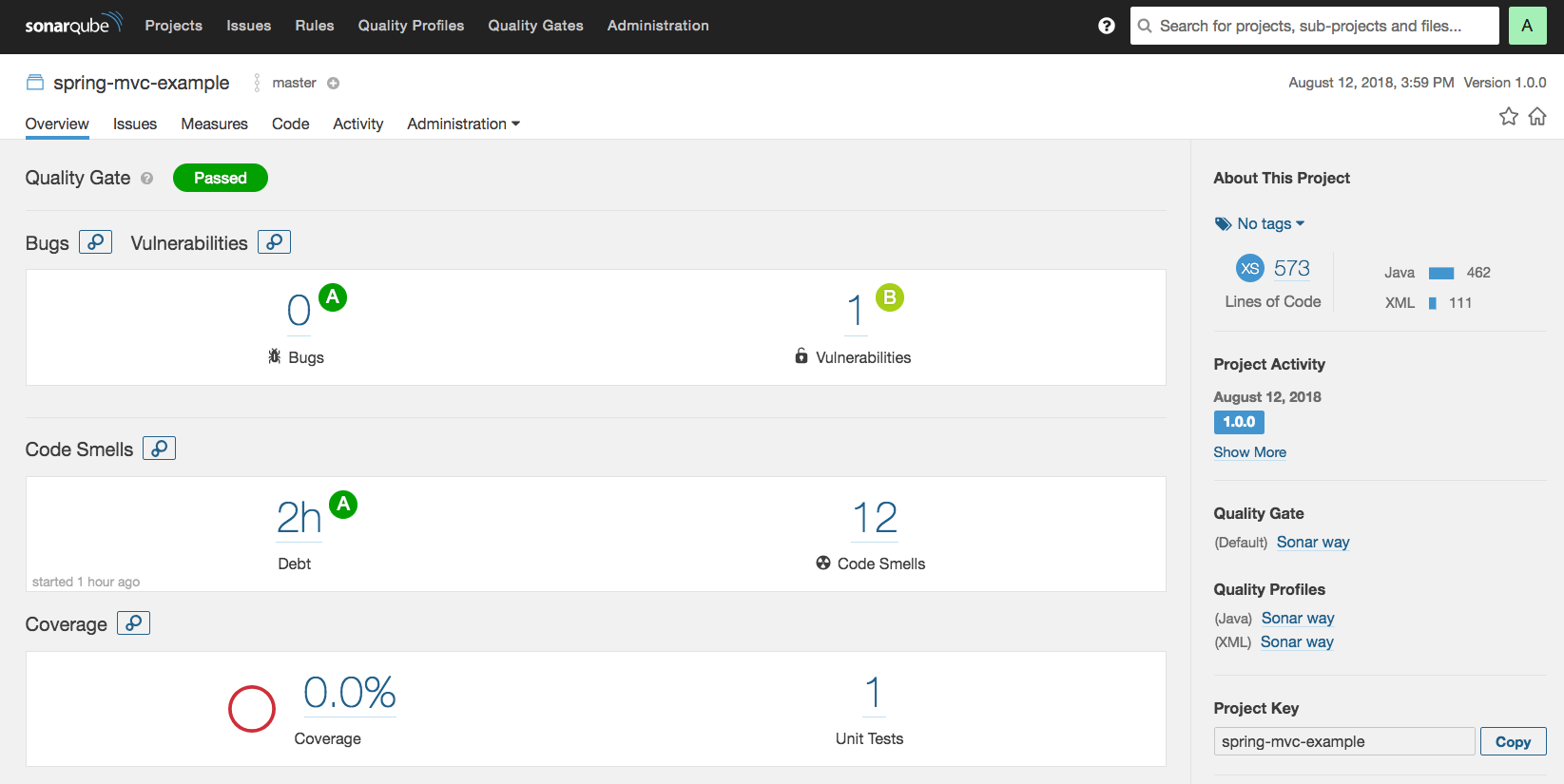
Target(대상)의 역할 지금 필요한 메소드를 결정합니다. 예제 프로그램에서 Print 인터페이스(상속의 경우)나 Print 클래스(위임의 경우)가 이 역할을 합니다.
Client(의뢰자)의 역할 Target 역할의 메소드를 사용해서 일을 합니다. 예제 프로그램에서 Main 클래스가 이 역할을 합니다.
Adaptee(개조되는 쪽)의 역할 Adaptee는 이미 준비되어 있는 메소드를 갖고 있는 역할입니다. Adaptee역의 메소드가 Target 역할의 메소드와 일치하면 다음 Adapter의 역할은 필요없습니다.
Adapter의 역할 Adapter 패턴의 주인공입니다. Adaptee 역할의 메소드를 사용해서 어떻게든 Target 역할을 만족시키기 위한 것이 Adapter 패턴의 목적이며, Adapter 역할의 임무입니다. 예제 프로그램에서는 PrintBanner 클래스가 Adapter의 역할을 합니다.
사고 넓히기
어떤 경우에 사용할까?
Adapter 패턴은 기존의 클래스를 개조해서 필요한 클래스를 만듭니다. 이 패턴으로 필요한 메소드를 빠르게 만들 수 있습니다.
이미 만들어진 클래스를 새로운 인터페이스(API)에 맞게 개조시킬 때 기존 클래스의 소스를 바꾸어서 ‘수정’하려고 합니다. 그러나 그렇게하면 테스트가 이미 끝난 기존의 클래스를 수정한 후에 다시 한 번 테스트 해야 합니다. Adapter 패턴은 기존의 클래스를 전혀 수정하지 않고 목적한 인터페이스(API)에 맞추려는 것입니다.
만약 버그가 발생해도 기존의 클래스(Adaptee의 역할)에는 버그가 없으므로 Adapter 역할의 클래스를 중점적으로 조사하면 되고, 프로그램 검사도 상당히 쉬워집니다.
스프링을 이용해 개발하고 있지만 스프링이 구동되는 서블릿 컨테이너에 대한 이해가 부족해 읽게 되었다. (어떻게 돌아가고 있는지 궁금했다…)
책의 구성은 서블릿 컨테이너를 학습해야 하는 이유를 시작으로 HTTP 프로토콜에 대한 이해 그리고 서블릿의 이해로 이어진다. 그 후에는 실제 서블릿 컨테이너에서 HTTP 프로토콜을 어떻게 분석해 서블릿에 전달해주는지, 스레드 풀을 이용해 동시에 들어오는 request 들을 어떻게 처리하는지에 대한 내용을 다루고 있다.
도입 부분(서블릿 컨테이너를 학습해야 하는 이유)에 다음과 같은 이야기가 있다.
특히 성능과 관련된 문제가 발생했을 때, 웹 기반 시스템의 하위 레벨 영역인 웹 애플리케이션 서버가 담당하는 부분을 모르고서는 근본적인 원인 규명 자체가 불가능합니다. 웹 애플리케이션 서버의 내부구조와 동작 원리를 이해하지 못하는지가 웹 프로그램의 고성능, 고가용성에 대한 요구를 충족시킬 수 있는지 결정한다고 할 수 있습니다.
위의 말에 전적으로 동의한다. 스프링을 이용해 웹 애플리케이션을 만들기 위해 스프링을 공부하고 이해하듯, 스프링이 실행되는 서블릿 컨테이너에 대한 공부와 이해도 필요하다. 아마 나와 같이 서블릿을 이용한 개발 경험 없이, 스프링을 시작했다면 이 책을 읽어보기를 더욱 추천하고 싶다.
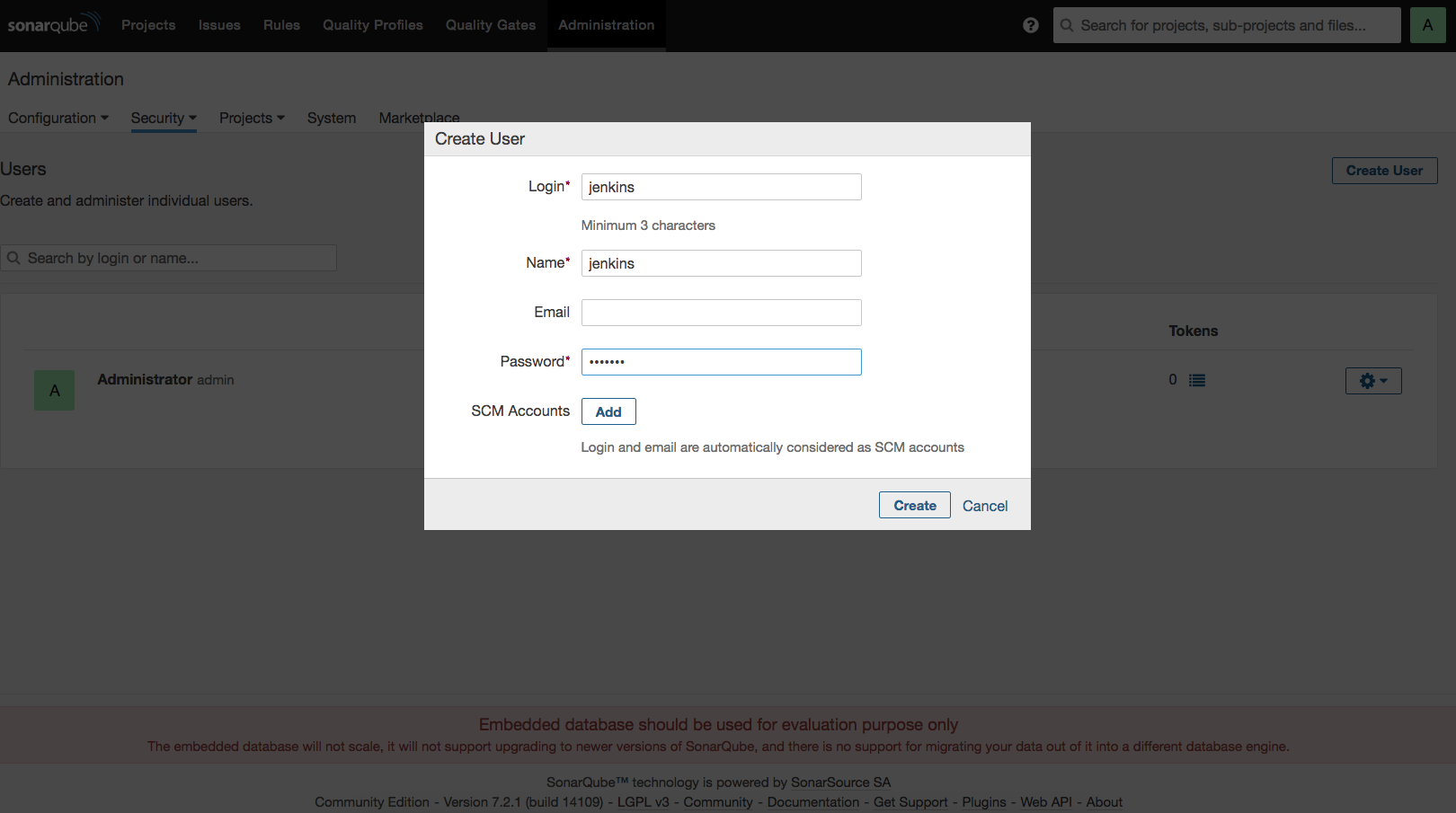
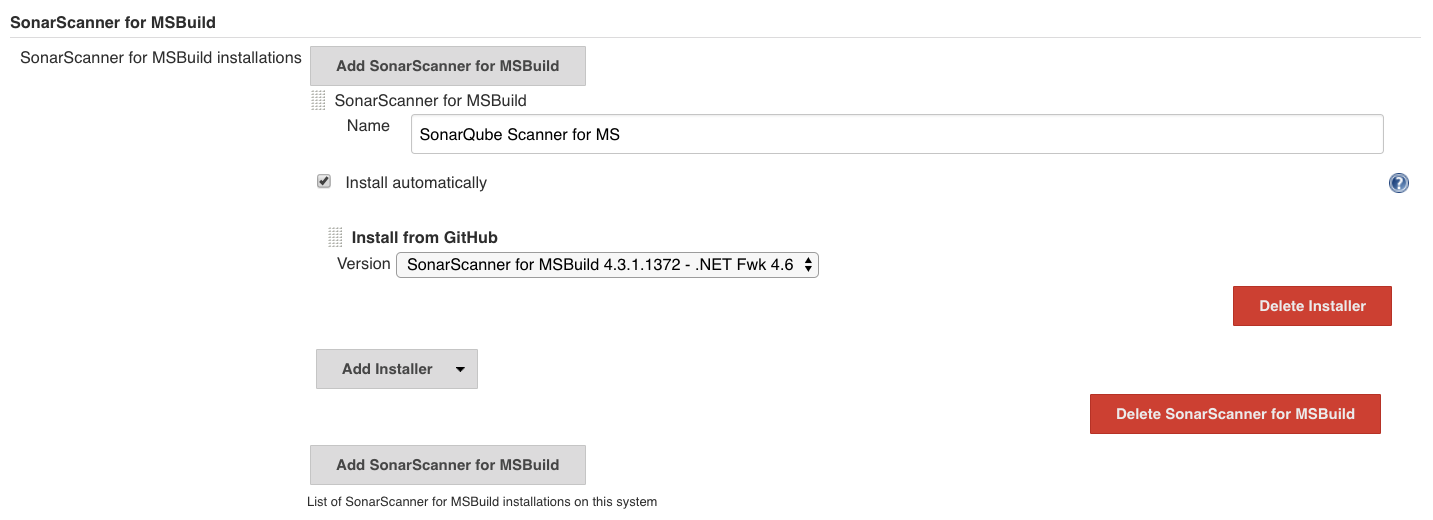
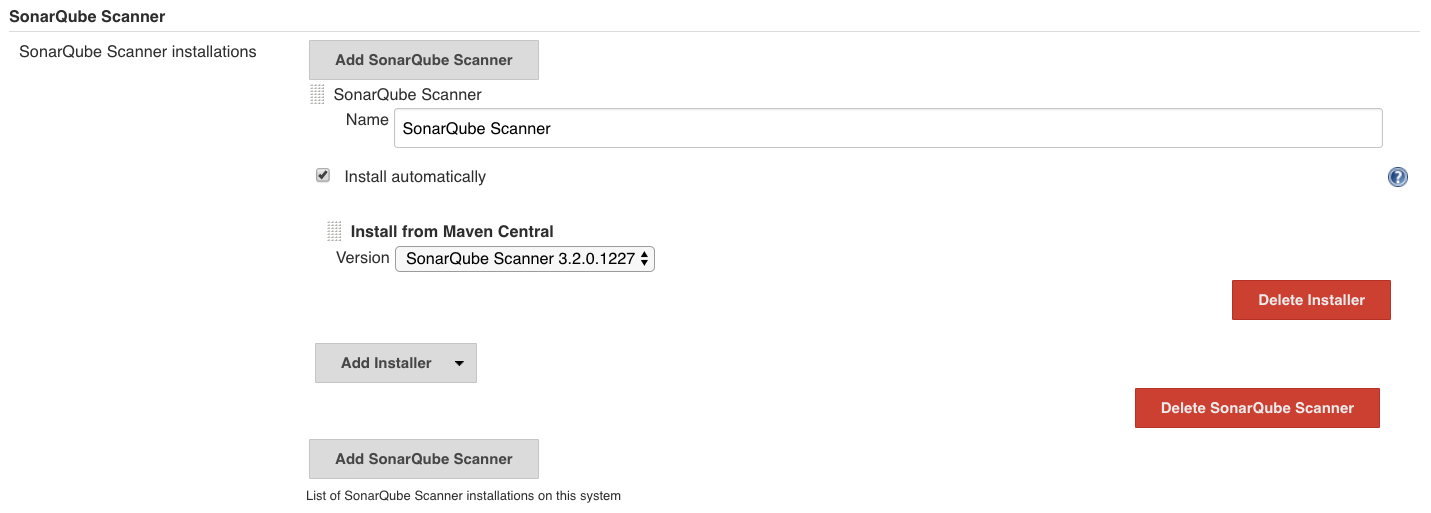
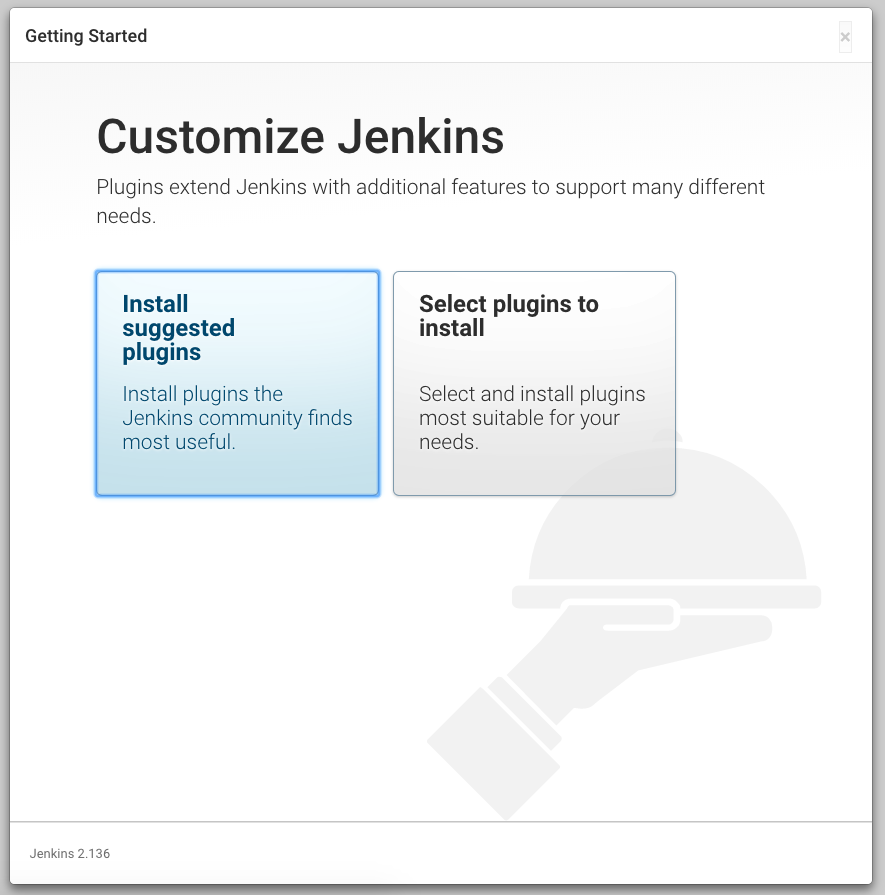
젠킨스를 어떻게 설치할지 결정할 수 있다. ‘Install suggested plugins’를 선택하면 젠킨스에서 추천하는 플러그인들이 같이 설치되고, ‘Select plugins to install’을 선택하면 필요한 플러그인을 선택하여 설치할 수 있다.
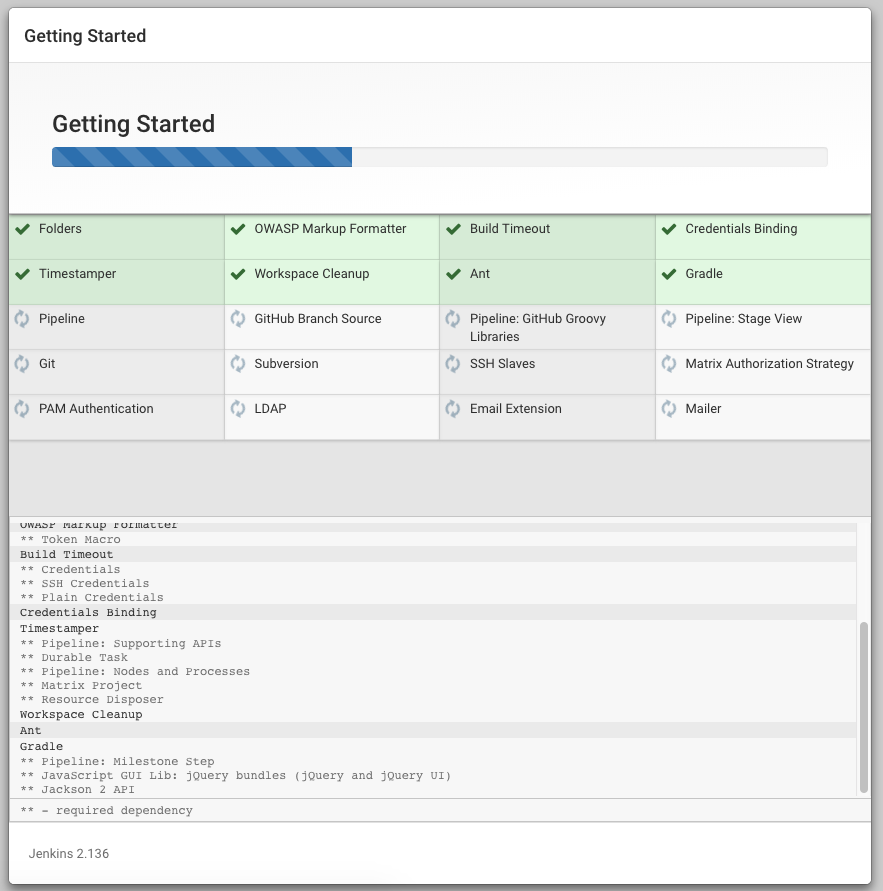
필요한 플러그인들을 자동으로 설치하기 시작한다.
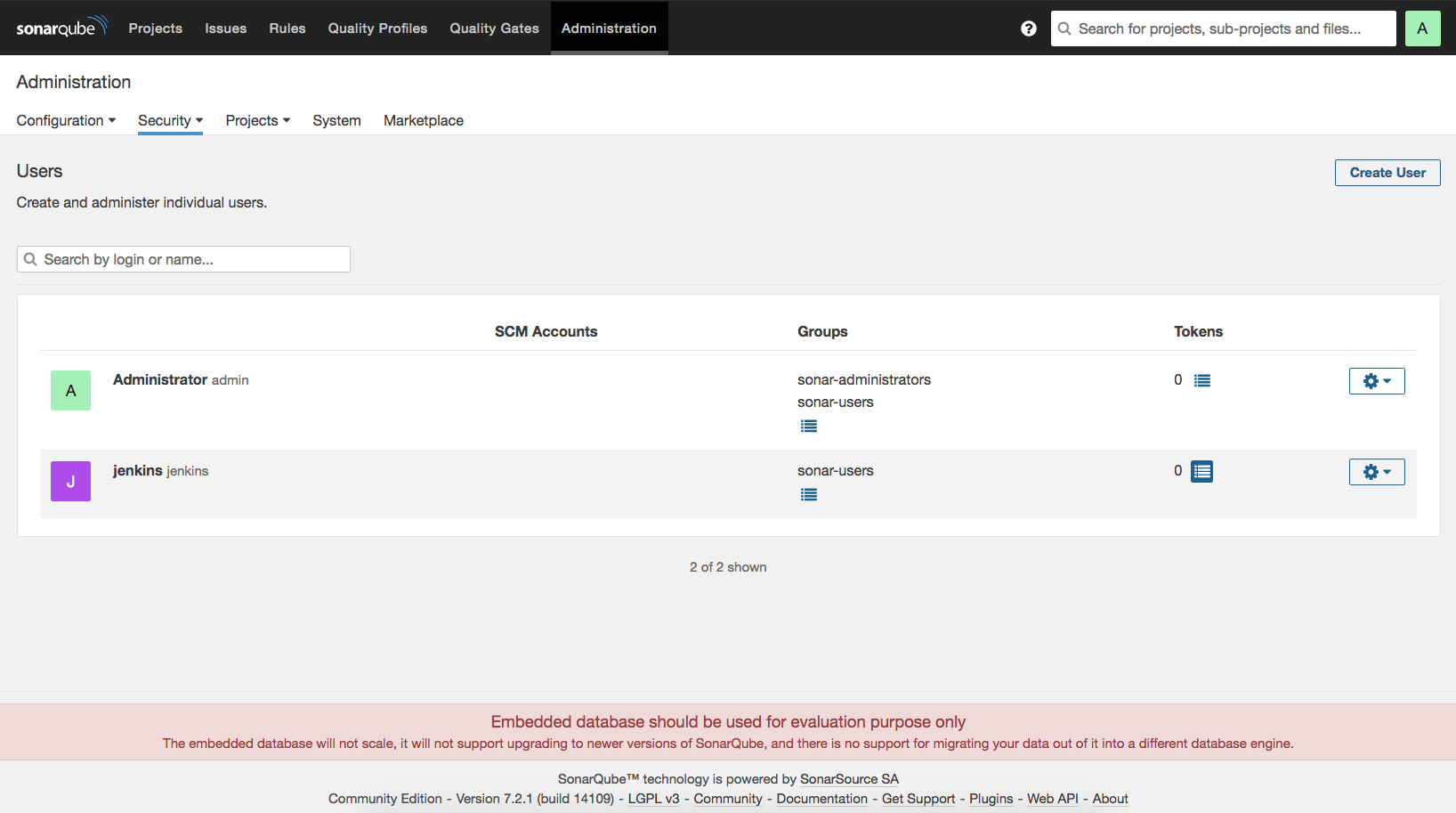
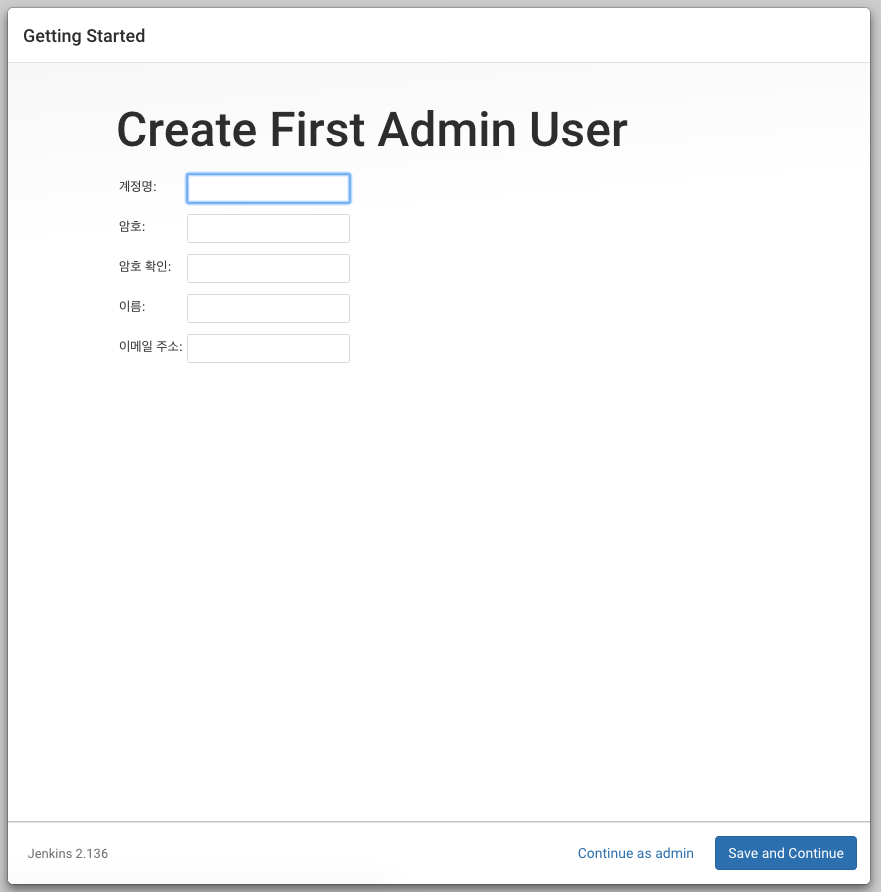
설치가 끝나면 관리자 정보 입력 화면이 나온다. 정보를 입력한 후 ‘Save and Finish’ 버튼을 클릭한다.
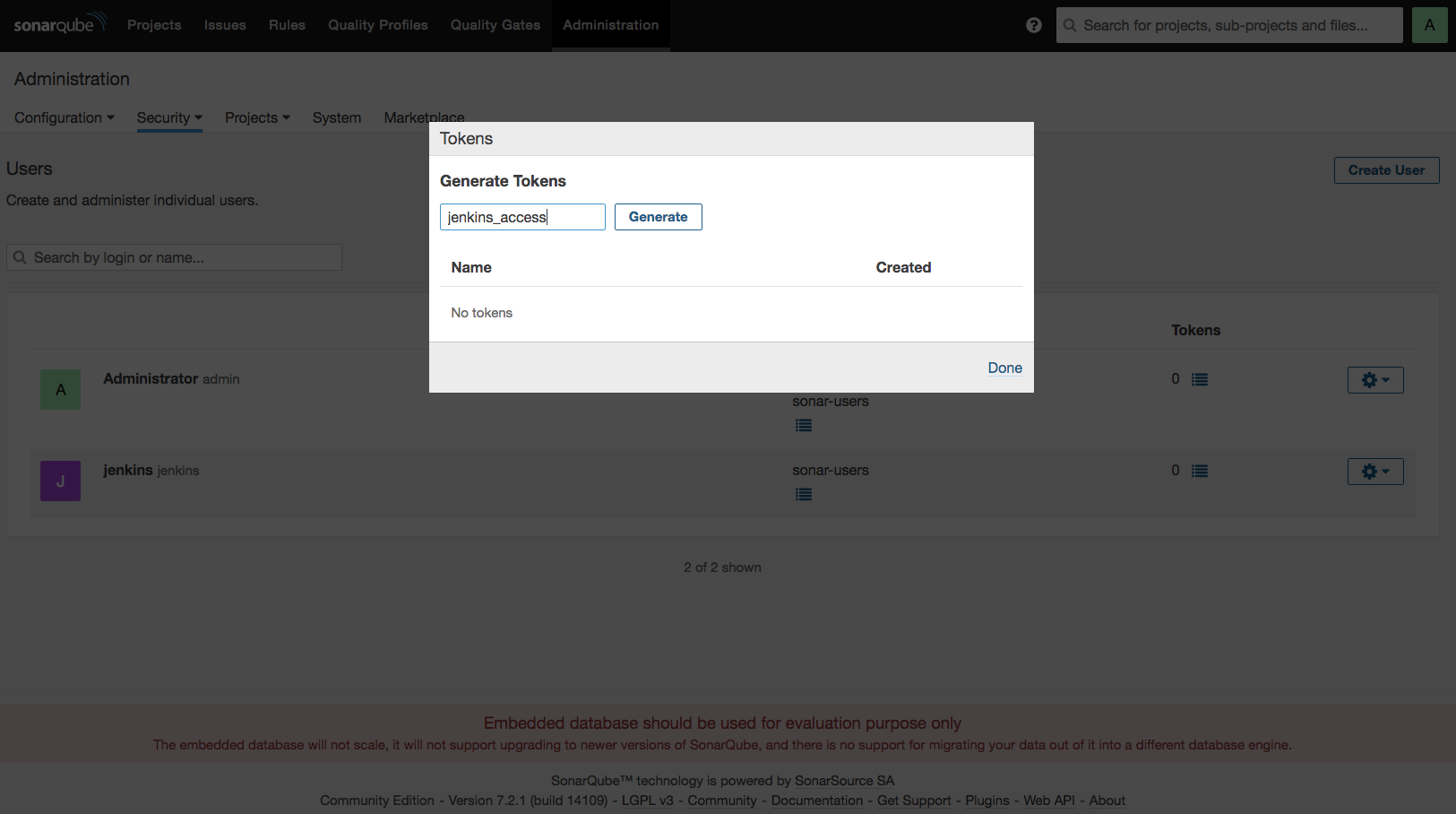
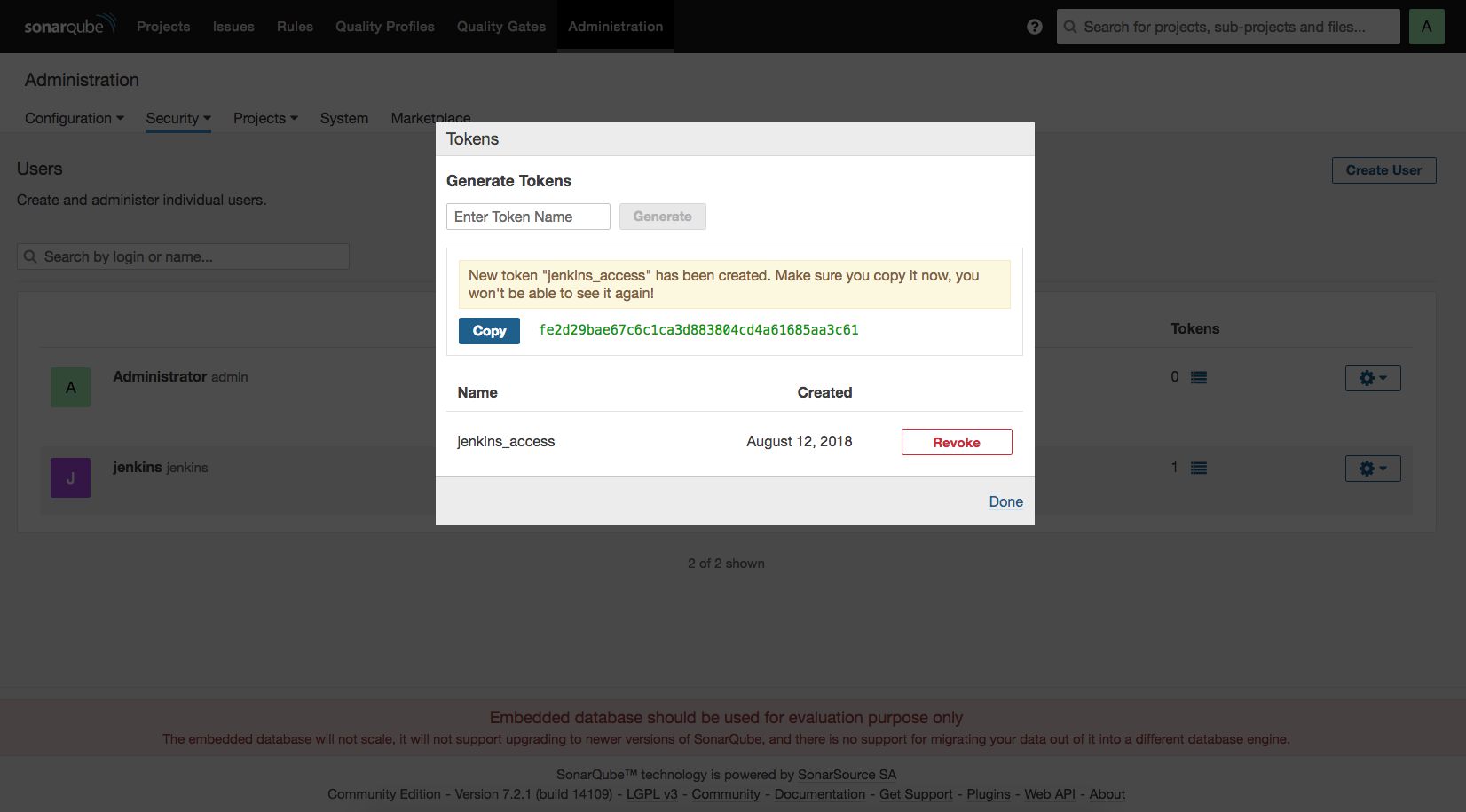
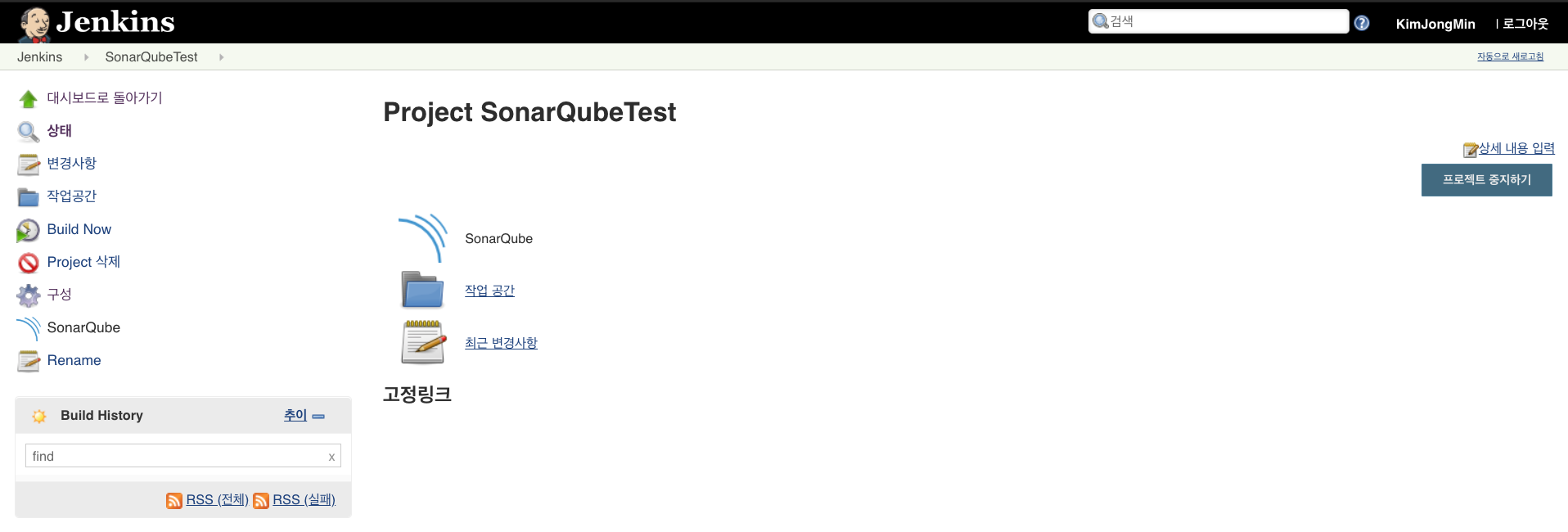
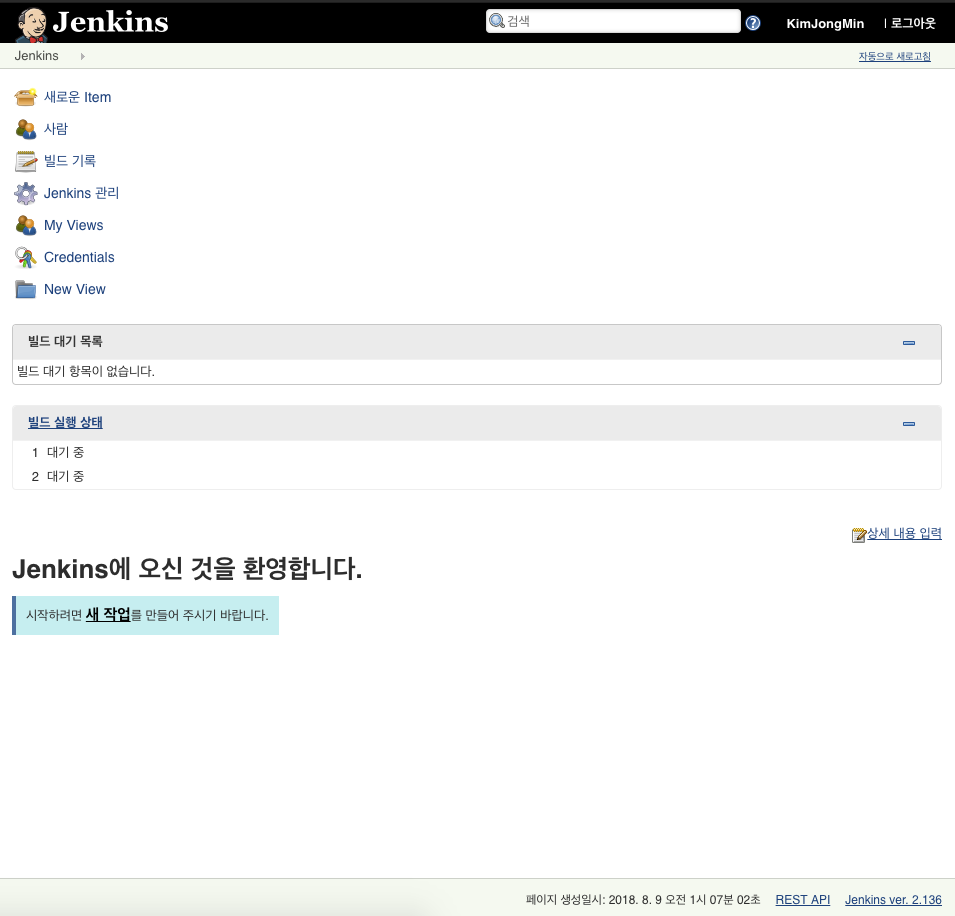
빌드 잡(job) 생성하기
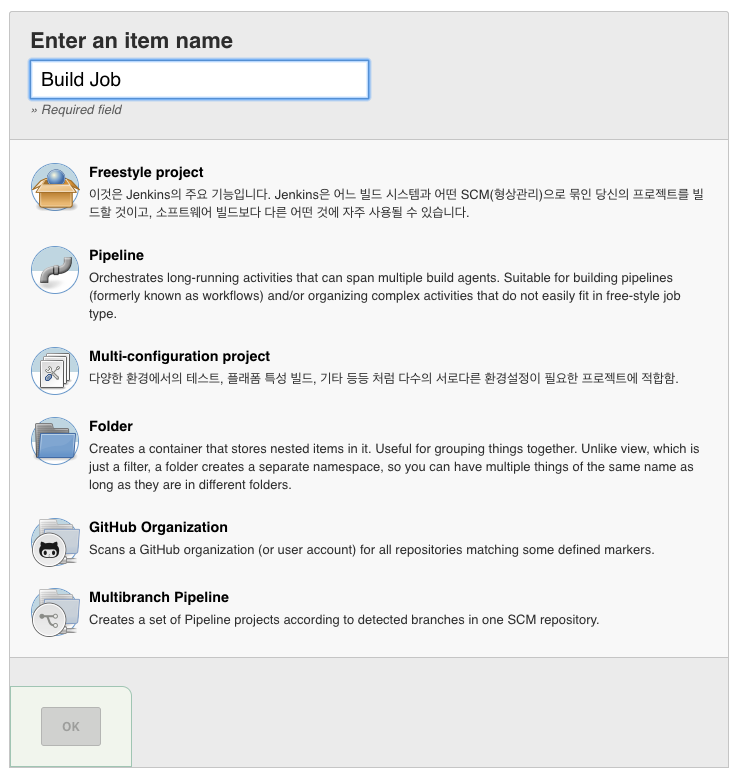
좌측 메뉴 상단에 있는 ‘새로운 Item’을 클릭한다. ‘Enter an item name’에 적당한 이름을 넣고 아래의 템플릿 중 ‘Freestyle project’를 선택한 후 ‘OK’ 버튼을 클릭한다. (Freestyle project는 거의 모든 젠킨스의 설정을 자유롭게 설정할 수 있다.)
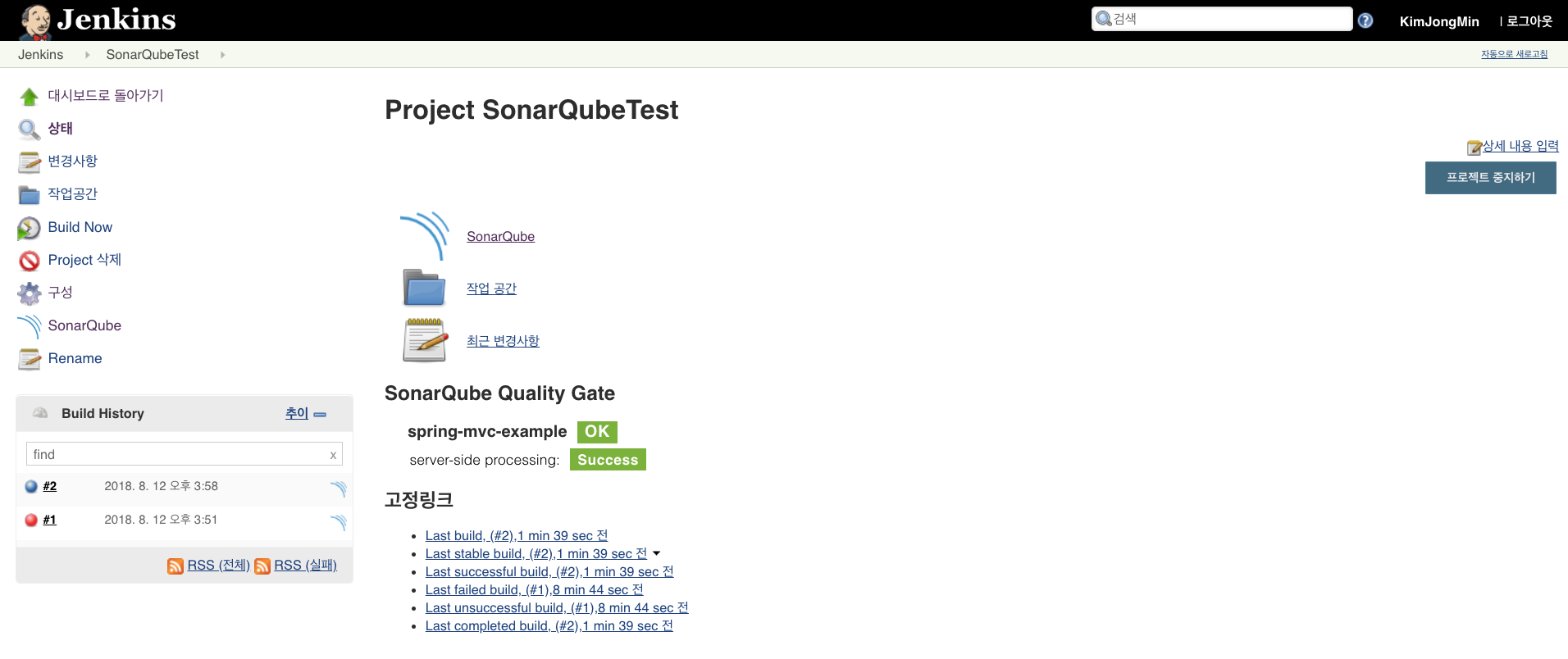
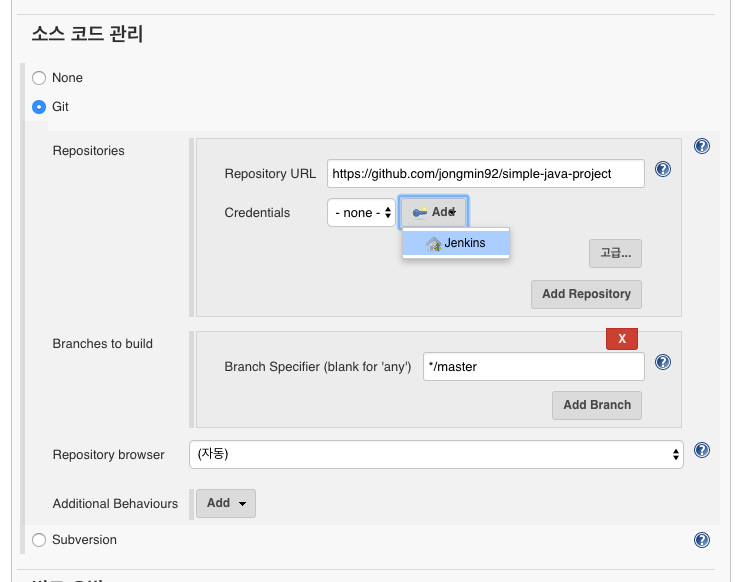
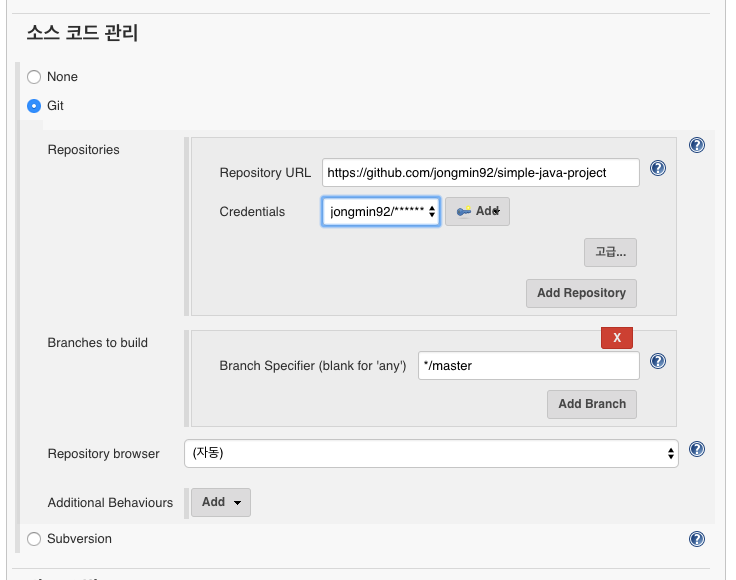
Github에 테스트를 위해 간단하게 만들어 놓은 프로젝트를 가져와 빌드를 테스트 한다.
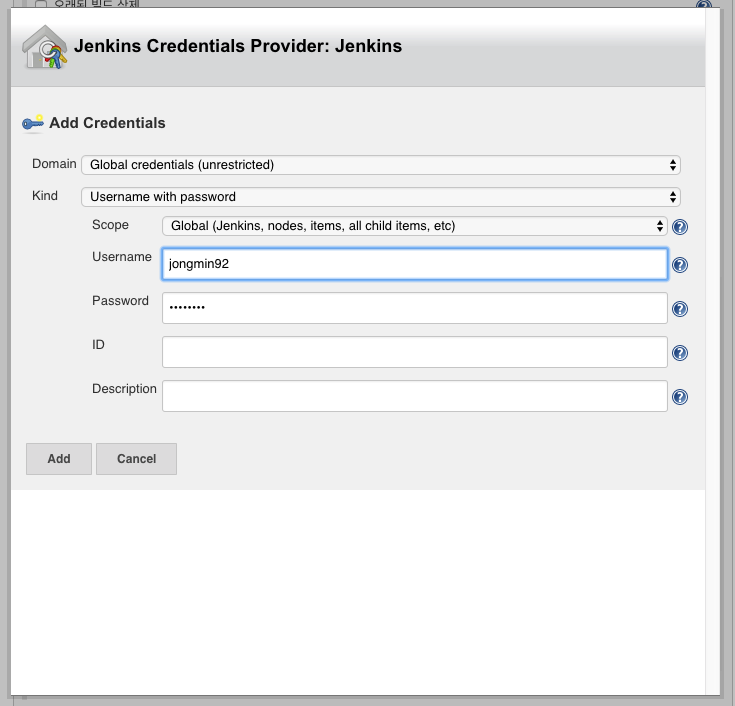
Github에서 프로젝트를 가져오기 위해서는 자격 증명을 추가해야 한다. ssh-key를 등록하거나 Github의 계정을 입력해야 한다.
Credentials 선택 박스에서 조금 전 추가한 계정을 선택한 후 ‘저장’ 버튼을 클릭한다.
그루비 는 자바 가상머신에서 동작하는 오픈 소스 스크립트 언어이다. 그루비는 자바 문법을 더욱 쉽게 쓰기 위해 스크립트 언어와 비슷한 문법으로 되어 있어서, 대부분의 자바 프로그래머는 자바 코드를 작성하는 느낌으로 그루비를 작성할 수 있다. 동적 언어이며 자바와 달리 작성한 스크립트를 컴파일할 필요 없이 직접 실행할 수도 있다.
또한, 일부 자바 프레임워크에서는 그루비를 지원한다. 대표적인 스프링 프레임워크에서도 그루비를 이용할 수 있다.
이처럼 자바와 거의 같고, 스크립트 언어처럼 부담 없이 작성해서 바로 실행할 수 있는 특징을 고려하면, 그루비를 사용해서 자바 빌드 도구를 만들려는 생각은 자연스럽다.
그루비의 이러한 이점을 최대한 활용해서 개발한 빌드 도구가 그레이들 이다.
그레이들이란
그레이들은 그루비를 사용한 빌드 도구이다. 메이븐은 XML을 이용하여 빌드 정보를 기술했는데, 그레이들은 그루비를 이용해 빌드 정보를 기술하기 한다. 때문에 자바 프로그래머가 좀 더 쉽게 다룰 수 있다.
그레이들의 특징은 다음과 같다.
유연한 언어로 기술 그루비라는 프로그래밍 언어를 사용해서 기술하기 때문에 유연하게 각종 처리를 수행할 수 있다. 또한 기술하는 내용을 분할하거나 구조화하는 것도 간단하다.
태스크로 처리 그레이들은 ‘태스크’라는 개념을 이용해 프로그램을 작성한다. 다양한 용도별로 태스크를 만들어서 그 안에 처리를 기술한다.
자바/그루비/스칼라 기본 지원 + 알파 그레이들은 자바 가상 머신에서 동작하는 언어를 중심으로 지원한다. (별도의 네이티브 코드 플러그인을 사용하면 C/C++ 등, 다른 언어에도 대응할 수 있다.)
각종 도구와 통합 여러 도구들(앤트, 아파치 아이비 등)과 통합되어 처리를 실행할 수 있다. 또한, 메이븐의 pom.xml을 그레이들용으로 변환하는 도구도 있다.
메이븐 중앙 저장소 대응 그레이들에서는 메이븐 중앙 저장소를 지원하기 때문에, 중앙 저장소에 있는 라이브러리 모두 그대로 이용 가능하다.
그레이들 사용하기
그레이들 소프트웨어에는 그루비가 포함되어 있기 때문에, 단지 그레이들을 사용하는 용도라면 그루비를 설치할 필요는 없다. (그레이들을 설치하는 것만으로는 그루비 언어를 이용해서 프로그래밍할 수는 없다.)
그레이들 프로젝트 생성
그레이들 명령어를 사용해 프로젝트를 생성할 수 있다.
1 2 3
mkdir gradle-app cd gradle-app gradle init --type java-library
gradle init
그레이들 명령어는 gradle OO 형태로 실행한다. 위에서 프로젝트를 생성하며 사용한 init은 그레이들에서 '태스크' 라고 부른다. 이 init은 프로젝트의 기본적은 파일과 폴더를 생성한다.
–type은 생성할 프로젝트의 타입을 지정하는 옵션인데, java-library는 자바 프로젝트임을 나타낸다. 지정한 언어의 샘플 코드를 생성한다. 이 옵션을 생략하면 그레이들 프로젝트의 기본적인 파일들만 생성된다.
그레이들 실행과 태스크
그레이들에서는 다양한 처리를 위해 ‘태스크’를 이용한다. 태스크란, 실행할 처리를 모아놓은 단위로 그레이들에서 처음부터 포함된 것도 있고, 프로그래머가 작성할 수도 있다. 이 태스크를 실행하는 것이 그레이들에서 빌드를 관리하는 기본적인 방법이다. 프로젝트를 컴파일하거나, 실행하는 모든 처리에 태스크를 이용한다.
생성된 gradle-app 폴더 내부의 구조를 살펴보자.
.gradle 폴더 : 태스크로 생성된 파일 등을 보존한다.
gradle 폴더 : 기본값으로는 그레이들 환경을 모아놓은 wrapper 파일이라고 하는 파일들이 들어 있다.
src 폴더 : 소스 코드 관련 파일을 이곳에 작성한다.
build.gradle : 그레이들 빌드 파일, 이곳에 프로젝트의 빌드 내용을 기술한다.
settings.gradle : 빌드 설정 정보를 기술한 파일. 빌드를 실행하기 전에 읽히기 때문에, 필요한 라이브러리를 읽는 등의 기술을 할 수 있다.
이번에는 생성된 파일의 코드를 확인해보자.
build.gradle
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 자바 프로그램을 빌드할 경우에는 java 플러그인을 로드한다. apply plugin:'java'
// 저장소 정보를 관리하는 프로퍼티이다. 이곳에서 저장소를 설정할 수 있다. (로컬 환경이나 원격 저장소 기술) // jcenter는 그레이들에서 중앙 저장소로 이용되는 저장소이다. // 메이븐 중앙 저장소는 mavenCentral 메서드를 이용해서 사용할 수 있다. repositories { jcenter() }
// 의존성에 관한 설정을 관리하는 프로퍼티이다. 필요한 라이브러리등의 정보를 기술한다. dependencies { compile 'org.slf4j:slf4j-api:1.7.21' testCompile 'junit:junit:4.12' }
settings.gradle
1 2
// 루트 프로젝트의 이름을 설정한다. 루트 프로젝트는 다수의 프로젝트를 관리할 때 기본이 되는 프로젝트를 가리킨다. 여기에서는 '이 빌드 파일로 빌드할 프로젝트의 이름'이라고 생각하면 된다. rootProject.name = 'gradle-app'
인텔리제이에서 사용하기
인텔리제이는 표준으로 그레이들을 지원한다. 인텔리제이에서 그레이들용 프로젝트를 생성할 경우, gradle init –type java-library 명령어를 사용하는 경우와 결과가 조금 다르다.
실행하면 의존성을 지정해서 실행할 때와 같은 결과를 얻지만, “Deprecated Gradle features were used in this build, making it incompatible with Gradle 5.0.” 라는 메시지가 출력된다. 그레이들 버전 5.0 부터는 execute 메서드를 직접 호출하는 것이 호환되지 않기 때문이다.
application 플러그인
java 플러그인에는 프로그램을 실행하는 태스크가 없어 application 플러그인을 사용해 애플리케이션을 실행해야 한다.
1
apply plugin:'application"
build.gradle에 이처럼 작성하고 그 다음에 mainClassName 프로퍼티에 메인 클래스(실행할 클래스)를 설정한다.
1
mainClassName = "com.jongmin.gradle.App"
application 플러그인에는 run 태스크가 포함되어 있다. 이것을 실행하면 mainClassName에 지정된 클래스가 실행된다.