[번역] Client-side rendering VS. Server-sde rendering
해당 포스팅은 Adam Zerner - Client-side rendering vs. server-side rendering의 글을 번역하였습니다.
초기에, 웹 프레임워크들은 서버(Server)에서 렌더링된 뷰를 갖고있었습니다. 현재는 클라이언트(Client)에서도 렌더링된 뷰를 가집니다. 지금부터 각각의 장점과 단점에 대해 알아보겠습니다.
성능(Performance)
**서버 측(Server-side)에서 렌더링**을 할 경우, 새로운 웹 페이지를 보고 싶을 때마다 다음과 같이 새로운 페이지 요청이 필요합니다.

이것은 먹고 싶은 것이 있을 때마다 슈퍼마켓에 가는것과 비슷합니다.
그러나 **클라이언트 측(Client-side) 렌더링**을 사용할 경우, 슈퍼마켓에 한 번 방문하고 좀 더 시간을 들여 꽤 오랜 기간동안 먹을 음식을 구매합니다. 그런 다음, 먹고 싶은 것이 있을 때마다 슈퍼마켓에 가지 않고 냉장고에서 찾게됩니다.
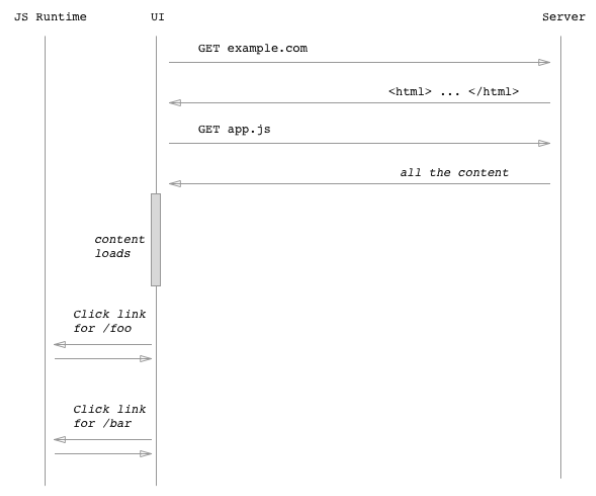
각 접근법에서는 성능면에서 장점과 단점이 있습니다.
- 클라이언트 측 렌더링을 사용하면 초기 페이지로드가 느려집니다. 네트워크를 통한 통신이 느리므로 사용자에게 콘텐츠를 표시하기 전에 서버를 두 번 왕복해야합니다. 그러나 그 후에는 이후의 모든 페이지로드가 엄청나게 빠릅니다.
- 서버 쪽 렌더링을 사용하면 초기 페이지로드가 크게 느려지지 않습니다. 그렇다고 크게 빠르지는 않을 것입니다. 그리고 이후의 다른 요청도 마찬가지입니다.
보다 구체적으로 말하자면, 클라이언트 측 렌더링을 사용하면 초기 페이지는 다음과 같이 보입니다.
1 | <html> |
app.js는 JavaScript의 모든 HTML 페이지를 다음과 같이 문자열로 유지합니다.
1 | var pages = { |
그런 다음 페이지가 로드되면 프레임워크는 URL 표시줄을 보고 [ ‘/‘] 페이지에서 문자열을 가져 와서 div class = "container"> </ div>에 삽입합니다. 또한 링크를 클릭하면 프레임워크가 이벤트를 가로 채고 컨테이너에 새 문자열 (예 : 페이지 [ ‘/ foo’])을 삽입하고 브라우저가 정상적으로하는 것처럼 HTTP 요청을 실행하지 못하게 합니다.
검색 엔진 최적화(SEO)
웹 크롤러가 reddit.com 을 요청하기 시작했다고 가정해봅시다.
1 | var request = require('request'); |
그러면 크롤러는 응답 본문에있는 <a href> 항목을 사용해서 새 요청을 생성합니다.
1 | var request = require('request'); |
그 후 크롤러는 espn.com 및 _news.ycombinator.com_의 링크를 사용하여 크롤링을 계속함으로써 프로세스를 계속 진행합니다.
결국 다음과 같은 재귀 코드처럼 동작합니다.
1 | var request = require('request'); |
그렇다면 만약 요청에 의한 응답이 다음과 같은경우는 어떻게 될까요?
1 | <html> |
위의 코드는 <a href> 태그가 없습니다. 또한 웹 페이지의 내용이 없기 때문에 검색 결과를 표시 할 때 우선순위를 지정하지 않을 것입니다.
크롤러는 거의 알지 못하지만, 클라이언트 측 프레임워크는 멋진 콘텐츠로 <div class = "container"> </div>"를 채우려합니다.
이러한 이유가 클라이언트 측 렌더링이 SEO에 좋지 않은 이유입니다.
사전 렌더링(Prerendering)
2009년에 Google은 이 문제를 해결할 수 있는 방법을 소개했습니다.
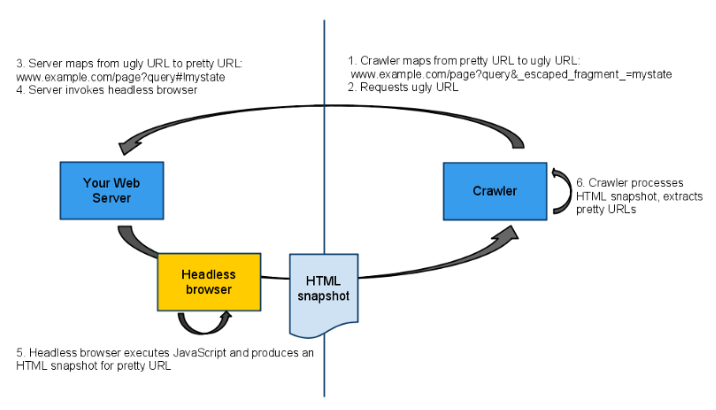
크롤러가 www.example.com/page?query#!mystate 를 방문하면 www.example.com/page?query&_escaped_fragment_=mystate 로 변환됩니다. 이렇게하면 서버가 _escaped_fragment_를 사용하여 요청을 받으면 사람이 아닌 크롤러에서 요청을 받는다는 것을 알 수 있습니다.
그렇기때문에 요청이 크롤러에서 온 경우 <div class = "container"> ... </ div>를 제공할 수 있습니다.
일반적인 요청 인 경우 <div class = "container"> </ div>를 제공하고 JavaScript가 내용을 내부에 삽입하도록 할 수 있습니다.
그러나 문제가 있습니다. 서버가 <div class = "container"> </ div>안에 무엇이 들어가는지 알지 못하기 때문입니다. 내부에 무엇이 들어가는지 파악하려면 JavaScript를 실행하고 DOM을 만들고 DOM을 조작해야합니다. 전통적인 웹 서버는 이를 수행하는 방법을 모르기 때문에 Headless Browser로 알려진 서비스를 사용합니다.

더 똑똑해진 크롤러
6년 후, Google은 크롤러가 한층 더 똑똑해 졌다고 발표했습니다. Crawler 2.0에서 <script> 태그를 볼 때 웹 브라우저처럼 실제로 요청을하고 코드를 실행하고 DOM을 조작한다는 것입니다.
그래서 다음과 같은 코드가
1 | <div class="container"></div> |
이제는 이렇게 보이는 것입니다.
1 | <div class="container"> |
Fetch as Google를 사용하여 Google 크롤러가 특정 URL을 방문했을 때 어떤 내용을 볼지 결정할 수 있습니다.
관련된 발표문의 내용 일부를 첨부합니다.
당시 우리 시스템은 자바 스크립트를 사용하여 사용자에게 콘텐츠를 제공하는 페이지를 렌더링하고 이해할 수 없었습니다. 크롤러는 동적으로 생성 된 콘텐츠를 볼 수 없었기 때문에 웹 마스터가 AJAX 기반 애플리케이션을 검색 엔진으로 인덱싱 할 수 있도록 일련의 방법을 제안했습니다.
시대가 바뀌 었습니다. 현재 Googlebot이 자바 스크립트 또는 CSS 파일을 크롤링하는 것을 차단하지 않는 한 일반적으로 최신 브라우저와 같이 웹 페이지를 렌더링하고 이해할 수 있습니다.
덜 똑똑한 크롤러
불행히도 Google 만이 유일한 검색 엔진이 아닙니다. Bing, Yahho, Duck Duck Go, Baidu 등도 있으며 실제로 사람들은 이러한 검색 엔진도 빈번하게 사용합니다.
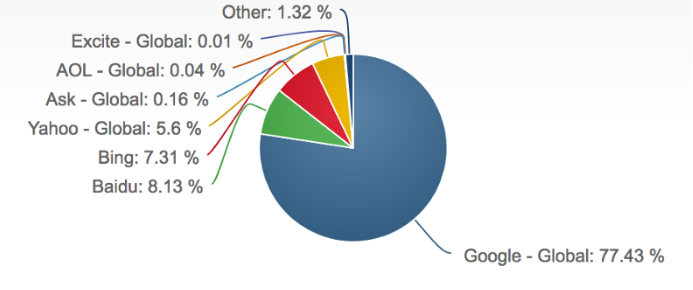
다른 검색 엔진은 JavaScript를 잘 처리하지 못합니다. 다음 글을 참고해보세요. SEO vs. React: Web Crawlers are Smarter Than You Think
두 세계의 장점
두 세계(서버 측 렌더링, 클라이언트 측 렌더링)의 장점을 최대한 활용하려면 다음의 방법이 있습니다.
- 첫 번째 페이지 로드에는 서버 측 렌더링을 사용.
- 그 후 모든 후속 페이지 로드에는 클라이언트 측 렌더링을 사용.

이것이 의미하는 바를 생각해보세요.
- 첫 번째 페이지 로드의 경우 사용자가 콘텐츠를 보기 전에 두 번 왕복하지 않습니다.
- 후속 페이지 로드가 빨라집니다.
- 크롤러는 간단한 HTML을 얻습니다. 옛날처럼 JavaScript를 실행하거나 _escaped_fragment_를 처리할 필요가 없습니다.
그러나 이를 위한 설정을 하기위해서는 서버에서 약간의 작업이 필요합니다. Angular, React 및 Ember 모두 이 접근 방식으로 변경했습니다.
토론
먼저 고려해야 할 몇 가지 사항은 다음과 같습니다.
- 약 2%의 사용자가 JavaScript를 사용할 수 없게 설정되어 있는 경우 클라이언트 측 렌더링이 전혀 작동하지 않습니다.
- 웹 검색의 약 1/4은 Google 이외의 엔진으로 수행됩니다.
- 모두가 빠른 인터넷 연결을 사용하는 것은 아닙니다.
- 휴대 전화 사용자는 대개 빠른 인터넷 연결이 필요하지 않습니다.
- 너무 빠른 UI는 혼란 스러울 수 있습니다. 사용자가 링크를 클릭한다고 가정 해보세요. 앱에서 새로운 뷰로 이동합니다. 그러나 새로운 뷰는 이전의 뷰와 미묘하게 다릅니다. 그리고 변경 사항은 즉시 발생했습니다 (클라이언트 측 렌더링의 장점). 새로운 뷰가 실제로 로드 된 것을 사용자가 알지 못할 수도 있습니다. 또는 사용자가 주의를 기울 였지만 상대적으로 미묘하기 때문에 사용자는 전환이 실제로 발생했는지 여부를 감지하기 위해 약간의 노력을 기울여야합니다. 때로는 약간의 로딩 스피너와 전체 페이지 재 렌더링을 하는 것이 좋습니다.
- 캐싱이 중요합니다. 따라서 서버 측 렌더링을 사용하면 실제로 사용자가 실제로 모든 것을 서버로 가져갈 필요가 없습니다. 때로는 바다 건너편의 “공식”서버가 아닌 근처의 서버에 가면됩니다.
- 실제로 성과와 관련하여 때로는 중요하지 않습니다. 때로는 속도가 좋고 속도가 약간 올라가더라도 삶이 더 좋아지지는 않습니다.
대부분의 사용자는 인터넷 연결 상태가 좋으며 충분히 빠릅니다. 특히 Macbook Pro로 yuppies를 타겟팅하는 경우. 초기로드 시간이 너무 길어서 사용자를 잃을 염려가 없습니다. 사용자가 링크를 클릭 할 때 실제로 새 페이지가 로드된다는 사실을 사용자가 알지 못하는 사용성 문제에 대해 걱정할 필요가 없습니다.
그러나 초기 페이지 로드시 서버 측 렌더링을 사용하는 클라이언트 측 렌더링을위한 사용 사례는 확실합니다. 큰 회사의 경우 #perfMatters, 인터넷 연결 속도가 느린 사용자가 있고 최적화에 충분한 시간을 할애 할 수있는 충분한 엔지니어링 팀이있는 경우가 종종 있습니다.
앞으로 이 같은 형태의 웹 프레임 워크 (초기 페이지 로드시 서버 쪽 렌더링을 사용하고 후에는 클라이언트 측 렌더링을 수행)가 보다 안정되고 사용하기 쉬워지기를 기대합니다. 이 시점에서 추가 된 복잡성은 최소화 될 것입니다. 그러나 오늘날,이 모든 것은 매우 새롭고, 많은 추상화가있을 것으로 기대합니다. 앞으로 더 나아가 클라이언트 측 렌더링이 필요하지 않은 곳에 인터넷 연결이 충분해지기 때문에 추세가 다시 서버 측 렌더링으로 되돌아 갈 것으로 예상됩니다.
[번역] Client-side rendering VS. Server-sde rendering
https://jongmin92.github.io/2017/06/06/JavaScript/client-side-rendering-vs-server-side-rendering/