Retrofit2 + OkHttp3 사용하기
신입사원 프로젝트로 간만에 안드로이드 개발을 하게됐습니다. 서버와 통신하기위해 Square에서 만든 Retrofit 라이브러리를 사용했는데, 기존에 사용하던 버전(1.x)과 변경된 부분이 많아 새롭게 사용법을 알아보고자 합니다.
Retrofit 테스트는 API 테스트 사이트를 통해서 Fake data를 가져오는 실습을 해보겠습니다. 해당 글의 대부분은 Retrofit 2.0 Example을 참고했습니다.
Retrofit2
Retrofit 의외에 다른 라이브러리도 있지만, Retrofit을 사용하기로 한 이유는 성능과 간단한 구현방법 때문입니다. 아래 보시는것과 같이 응답속도가 매우 빠른것으로 나와있습니다. 더 자세한 비교는 Android Async HTTP Clients: Volley vs Retrofit에서 볼 수 있습니다.
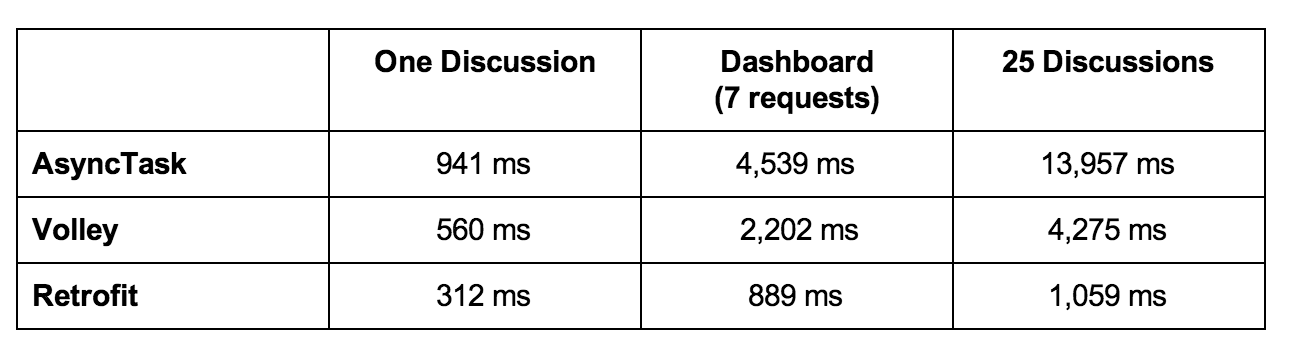
Retrofit2는 기본적으로 OkHttp를 네트워킹 계층으로 활용하며 그 위에 구축됩니다.
Retrofit은 자동적으로 JSON 응답을 사전에 정의된 POJO를 통해 직렬화 할 수 있습니다. JSON을 직렬화 하기 위해서는 먼저 Gson converter가 필요합니다. **build.gradle**에 다음의 dependencies를 추가합니다.
1 | compile 'com.squareup.retrofit2:retrofit:2.3.0' |
OkHttp는 이미 Retrofit2 모듈의 종속성에 포함되어 있어, 별도의 OkHttp 설정이 필요하다면 다음과 같이 Retrofit2에서 OkHttp 종속성을 제외해야 합니다.
1 | compile('com.squareup.retrofit2:retrofit:2.3.0') { |
네트워크 사용을 위해서 **AndroidManifest.xml**에서 Internet Permission을 추가합니다.
1 | <manifest xmlns:android="http://schemas.android.com/apk/res/android"> |
OkHttp Interceptors
**Interceptor**는 OkHttp에 있는 강력한 메커니즘으로 호출을 모니터, 재 작성 및 재 시도를 할 수 있습니다. Interceptor는 크게 두 가지 카테고리로 분류할 수 있습니다.
- Application Interceptors : Application Interceptor를 등록하려면
OkHttpClient.Builder에서addInterceptor()를 호출해야 합니다. - Network Interceptors : Network Interceptor를 등록하려면
addInterceptor()대신addNetworkInterceptor()를 추가해야 합니다.
Retrofit Interface 설정
APIClient.java
1 | package com.journaldev.retrofitintro; |
getClient() 메서드는 Retrofit 인터페이스를 설정할 때마다 호출됩니다. Retrofit은 **@GET, @POST, @PUT, @DELETE, @PATCH or @HEAD**와 같은 annotation을 통해 HTTP method를 이용합니다.
APIInterface.java
1 | package com.journaldev.retrofitintro; |
위의 클래스에서 Annotation을 통해 테스트 HTTP request를 작성했습니다. 해당 API로 이곳을 통해 테스트 할 것입니다.
@GET("api/unknown")은 doGetListResources()를 호출합니다.doGetListResources()은 메서드 이름입니다. MultipleResource.java는 응답 객체의 Model POJO 클래스로서 Response parameter를 각각의 변수에 매핑하는 데 사용됩니다. 이러한 POJO 클래스는 메소드 리턴 유형으로 동작합니다.
MultipleResources.java
1 | package com.journaldev.retrofitintro.pojo; |
@SerializedName 어노테이션은 JSON 응답에서 각각의 필드를 구분하기 위해 사용합니다.
# Tip) jsonschema2pojo 에서 json 응답의 구조를 바탕으로 해당 응답에 대한 POJO 클래스를 쉽게 만들 수 있습니다.
POJO 클래스는 Retrofit Call 클래스로 래핑됩니다. (JSONArray는 POJO 클래스의 객체 목록으로 직렬화됩니다.)
Method Parameters : 메서드 내에서 전달할 수 있는 다양한 매개 변수 옵션이 있습니다.
- @Body - request body로 Java 객체를 전달합니다.
- @Url - 동적인 URL이 필요할때 사용합니다.
- @Query - 쿼리를 추가할 수 있으며, 쿼리를 URL 인코딩하려면 다음과 같이 작성합니다.
@Query(value = “auth_token”,encoded = true) String auth_token - @Field - POST에서만 동작하며 form-urlencoded로 데이터를 전송합니다. 이 메소드에는 @FormUrlEncoded 어노테이션이 추가되어야 합니다.
Android Retrofit 예제 프로젝트 구조
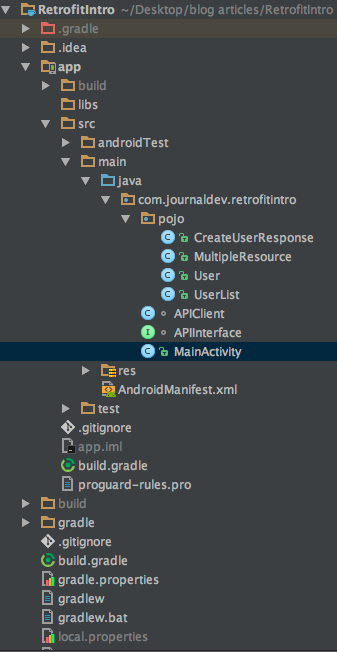
pojo 패키지는 APIInterface.java 클래스에 정의된 각각의 API 요청 응답에 대한 4가지 모델 클래스를 정의하고 있습니다.
User.java
1 | package com.journaldev.retrofitintro.pojo; |
위 클래스는 createUser() 메서드에 대한 응답을 위해 사용합니다.
UserList.java
1 | package com.journaldev.retrofitintro.pojo; |
CreateUserResponse.java
1 | package com.journaldev.retrofitintro.pojo; |
MainActivity.java
**MainActivity.java**는 Interface 클래스에 정의된 각각의 API를 호출하고 그 결과를 Toast와 TextView를 통해 표시하고 있습니다.
1 | package com.journaldev.retrofitintro; |
apiInterface = APIClient.getClient().create(APIInterface.class);는 APIClient를 인스턴스화 하기위해 사용됩니다.
API 응답에 Model 클래스를 매핑하기 위해서는 다음과 같이 사용합니다.MultipleResource resource = response.body();
이제 앱을 실행하면 각 API를 호출하고 이에 따라 토스트 메시지를 표시합니다.















