MySQL - Replication
Database Replication
여러 대의 DB 서버가 있을 때 각각의 DB 서버가 동일한 데이터를 유지하도록 하는 메커니즘 혹은 기법을 말한다.
Replication(리플리케이션)을 이용해서 백업과 부하분산같은 목적을 달성할 수 있다.
master 서버에 데이터가 기록(쓰기)되고, slave 서버들은 master에 기록된 데이터를 전파받으며 보통 읽기에 사용된다.
정리하면 한대의 master 서버는 쓰기, 여러대의 slave 서버들은 읽기에 사용되는 것이다.
백업과 부하분산
master DB의 데이터가 빠른 속도로 slave DB에 복제되기 때문에 master DB에 문제가 생겼을 때, slave DB를 master DB로 대체해 빠르게 장애를 복구할 수 있다.
그렇지만 Replication 자체가 완전한 백업을 의미하는 것은 아니다. master DB에 의도하지 않은 작업(데이터를 잘못해서 대량으로 삭제)을 수행했을 때 해당 작업이 slave DB에도 전파가 되기 때문에 이러한 것들은 복구가 불가능하다.
그러므로 실시간 성의 백업은 Replication이 담당하고, 시간차를 두고 백업이 필요한 것은 보통 스케쥴링을 통하여 시간 간격을 두고 백업을 하는것이 바람직하다.
읽기와 관련된 부하분산을 할 수 있다는 것이 Replication의 장점이다. 한계라고 하면 쓰기와 관련된 부분인데, 한 대의 master DB에 쓰기가 집중되기 때문에 쓰기 작업에 부하가 많다면 문제가 생길 수 있다.
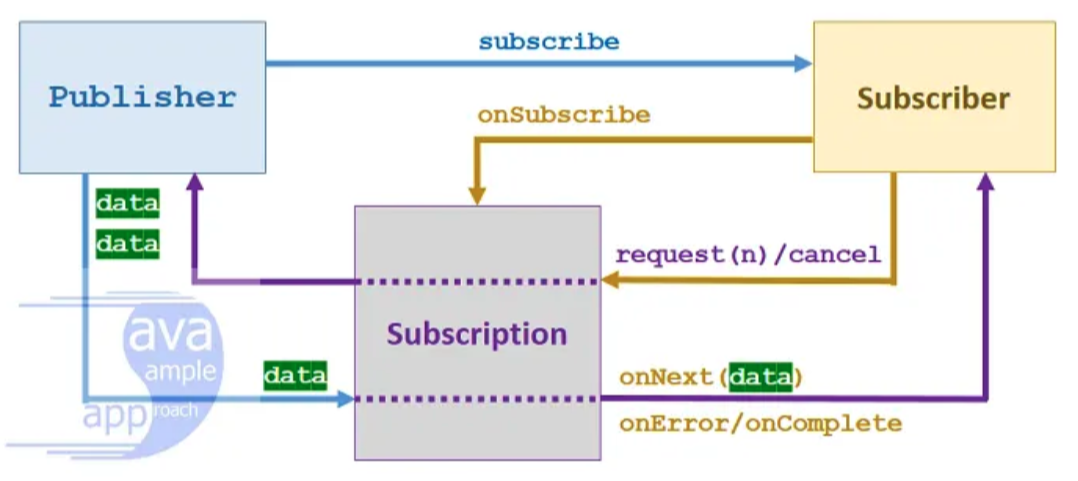
간략하게 Replication이 동작하는 방식을 확인해보자. 아래 그림은 master DB와 slave DB가 1대1로 연결되어 있는 구조이다.
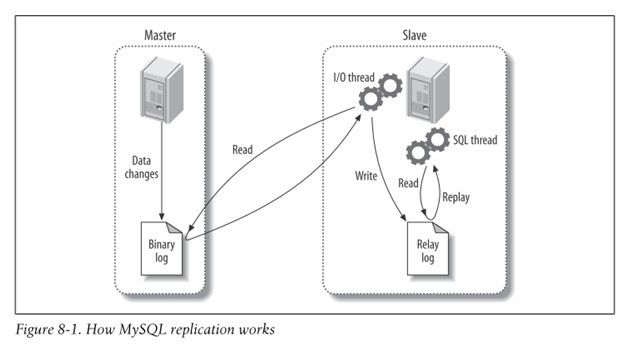
- master DB가 Data의 변경사항을
Binary log에 기록한다. - master DB가 Slave DB에게 변경이 있음을 통지한다.
- slave DB가
I/O thread이용해 Binary log를 가져온다. - slave DB의
Relay log에 변경사항을 기록한다. - slave DB의
SQL thread를 이용해 변경사항을 반영한다.
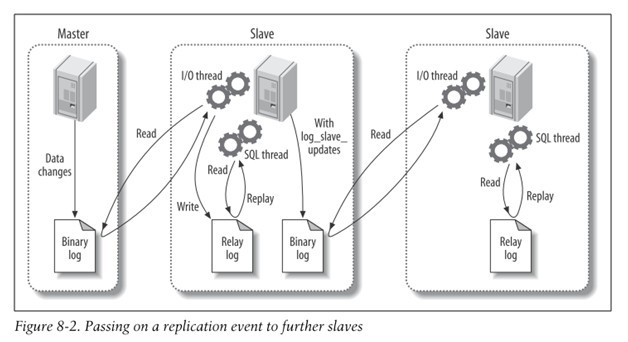
아래 그림은 또 다른 구조의 Replication이다. master DB와 slave DB가 존재하고 slave DB에 다시 slave DB가 존재하는 구조이다.
가운데의 slave DB가 master DB 처럼 Binary log를 생성해서 다른 slave에게 전달하는 것이다. 이 경우 가장 마지막에 있는 slave DB가 직접 master DB에 접근하는 것이 아니기 때문에 master DB의 부담을 줄일 수 있다.
또한 가운데의 slave DB 역시 master DB 처럼 Binary log를 생성하고 있기 때문에 master DB에 문제가 생겼을 때, 빠르고 쉽게 master DB로 대체가 가능하다.
Replication 실습
그럼 이제 간단하게 MySQL Replication을 구축해보자. 여러 대의 서버에 MySQL을 설치하고 준비하는 것은 번거롭기 때문에 간편하게 도커를 이용해서 진행해보자.
MySQL master 컨테이너 실행하기
먼저 master DB 컨테이너를 생성하고 접속한다.
1 | docker run --name mysql-master -e MYSQL_ROOT_PASSWORD=asdf1234 -d mysql |
설치한 vim을 이용해 MySQL 설정 파일인 /etc/mysql/my.cnf 파일에 다음의 내용을 추가한다.
1 | [mysqld] |
- log-bin: 업데이트되는 모든 query들을 Binary log 파일에 기록한다는 의미이다.
기본적으로 Binary log 파일은 MySQL의 data directory인 /var/lib/mysql/ 에 호스트명-bin.000001, 호스트명-bin.000002 형태로 생성된다.
이때, log-bin 설정을 변경하면 Binary log 파일의 경로와 파일명의 접두어를 변경할 수 있다. log-bin=mysql 이라 설정하면 mysql-bin.000001, mysql-bin.000002 형태로 Binary log 파일이 생성된다.- server-id: Replication 설정에서 서버를 식별하기 위한 고유 ID값이다. master, slave 각각 다르게 설정해야 한다.
도커 컨테이너(MySQL)를 재시작해서 변경된 설정 파일을 반영한다.
1 | docker restart mysql-master |
변경한 설정이 잘 적용되었는지 확인해보자.
1 | docker exec -it mysql-master /bin/bash |
master DB에 User 생성하기
slave DB에서 접근할 수 있도록 master DB에 User 계정을 생성하고 REPLICATION SLAVE 권한을 부여한다.
1 | CREATE USER 'repl'@'%' IDENTIFIED BY 'replpw'; |
User가 생성되었는지 User 테이블을 확인한다.
1 | USE mysql; |
다음으로, Replication 테스트를 위한 DB와 테이블을 생성한다.
1 | CREATE DATABASE testdb; |
master DB dump
slave DB에서 master DB를 연결하기 전에 master DB의 현재 DB 상태(table과 data)를 slave DB에 그대로 반영하기 위해 dump한다.
1 | docker exec -it mysql-master /bin/bash |
dump된 파일을 slave DB 컨테이너에 옮기기 위해 먼저 로컬 PC로 복사한다.
1 | docker cp mysql-master:dump.sql . |
MySQL slave 컨테이너 실행하기
slave DB 컨테이너를 생성하고 접속한다.
1 | docker run --name mysql-slave --link mysql-master -e MYSQL_ROOT_PASSWORD=asdf1234 -d mysql |
설치한 vim을 이용해 MySQL 설정 파일인 /etc/mysql/my.cnf 파일에 다음의 내용을 추가한다.
slave 서버를 여러 대로 구축하고자 할 때에 각 slave 서버의 server-id는 각각 달라야 한다는 것에 주의하자. (2^32-1 까지 가능하다.)
1 | [mysqld] |
도커 컨테이너(MySQL)를 재시작해서 변경된 설정 파일을 반영한다.
1 | docker restart mysql-slave |
slave DB에 dump 파일 적용
로컬 PC로 복사한 master DB의 dump 파일을 slave DB로 옮긴 후 반영한다.
1 | docker cp dump.sql mysql-slave:. |
다시 mysql에 접속해 testdb DB에 testtable 테이블과 데이터가 생성되어 있다면 정상적으로 dump 파일이 적용된 것이다.
1 | USE testdb; |
slave DB에서 master DB 연동하기
이제 마지막으로 slave 서버에서 master 서버와 연동하는 작업만 하면 된다.
그 전에 master DB의 mysql에 한번 더 접속하여 Binary log 파일의 현재 상태를 읽어야 한다. 이 Binary log 파일을 통해 master와 slave의 DB가 동기화되므로 반드시 동일한 로그의 위치를 서로 참조하고 있어야 한다.
1 | docker exec -it mysql-master /bin/bash |
출력된 결과에서 File, Position 필드의 값을 기억하도록 한다.File 은 현재 바이너리 로그 파일명이고, Position 은 현재 로그의 위치를 나타낸다. 앞서 DB와 테이블을 생성한 query가 추가됐으므로 이전에 SHOW MASTER STATUS\G 를 실행했을 때보다 Position 값이 증가했음을 볼 수 있다.
이제 slave 서버의 mysql에 접속하여 master 서버와의 연결에 필요한 변수들을 적절히 설정해주어야 한다.
1 | docker exec -it mysql-slave /bin/bash |
- MASTER_HOST : master 서버의 호스트명
- MASTER_USER : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 이름
- MASTER_PASSWORD : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 비밀번호
- MASTER_LOG_FILE : master 서버의 바이너리 로그 파일명
- MASTER_LOG_POS : master 서버의 현재 로그의 위치
아래의 명령어를 실행해 slave의 상태를 확인해보자.
1 | SHOW SLAVE STATUS\G |
Replication 테스트
문제 없이 Replication 설정이 완료되었다면 마지막으로 실제 잘 동작하는지 확인해보자.
master DB에서 데이터를 생성하고, slave DB에 복제되어 데이터가 조회되는지 확인한다.
master DB에서 데이터를 생성한다.
1 | docker exec -it mysql-master /bin/bash |
slave DB에서 데이터를 조회한다.
1 | docker exec -it mysql-slave /bin/bash |