자바를 처음 공부할 때는 이클립스 혹은 인텔리제이 같은 IDE만으로 프로그램을 뚝딱 만들 수 있다. 그러나 현업에 투입되면 무언가 복잡한 환경을 만나게 된다.
하지만 실제 자바 입문시절에 배운 과정과 현업에서 사용하는 과정에 차이는 없다. 다만 다양한 도구를 사용하여 더 전문화하여 현업 도구에 활용할 뿐이다.
명령행에서 컴파일하기 아주 간단한 프로그램이라면 명령행에서 javac를 이용하는 것만으로도 충분하다. 하지만 라이브러리 등을 이용하면, classpath에 다수의 라이브러리 경로를 기술한 뒤에 컴파일 해야 한다. 또한 생성된 클래스 파일을 모아 JAR 파일을 생성하려면 이 역시 모두 명령어로 실행해야 한다. 소스 코드의 컴파일에서 JAR 파일의 생성까지 긴 과정을 수행하려면 방대한 명령어가 필요한데, 이를 매번 수작업으로 작성하면 큰 수고가 든다.
프로젝트 및 라이브러리 설치 최근에는 개발할 때 모든 프로그램을 처음부터 만드는 경우가 거의 없다. 프로그램에 필요한 기능은 라이브러리를 이용하거나, 프레임워크를 이용하여 애플리케이션을 개발한다. 이런 경우, 필요한 소프트웨어를 갖추고 정해진 대로 파일을 구성해야 한다.
테스트 자동화 단순한 프로그램이라면 컴파일 후 실행 및 동작만 확인하는 것으로 충분하지만, 어느 정도 규모 있는 프로그램은 프로그램 생성과 함께 테스트를 실행하는 것이 일반적이다.
프로그램 배포 웹 애플리케이션은 구현한 프로그램을 서버에 배포하게 된다. 이런 작업을 수작업으로 시행하기가 번거롭다.
빌드 도구의 역할
‘빌드 도구’는 단순히 프로그램을 컴파일하여 애플리케이션을 생성하는 작업 그 이상으로 다양한 기능을 제공한다.
프로그램 빌드 프로그램을 컴파일하고, 지정된 디렉터리에 필요한 리소스를 모아서 프로그램을 완성한다. 그때 라이브러리등 필요한 파일을 설치하도록 지정할 수 있다.
프로그램 테스트와 실행 빌드된 프로그램의 실행뿐 아니라 테스트 기능도 제공한다. 빌드를 실행 할 때, 빌드가 완료되면 곧바로 테스트를 실행하는 도구도 있다.
라이브러리 관리 프로그램에서 필요한 라이브러리들을 관리한다. 빌드 실행 시 자동으로 라이브러리를 다운로드하고 설치하는 등의 작업을 한다.
배포 작업 빌드한 프로그램을 배포하는 기능을 제공한다.
개발 도구와 빌드 도구
개발 도구에 있어 빌드 도구를 다루는 방식은 크게 두 가지이다.
빌드 도구를 이용하는 기능이 포함된 경우 이클립스는 메이븐, 인텔리제이는 메이븐과 그레이들을 지원한다.
개발 도구에서 명령어로 실행하는 경우
메이븐 기초
메이븐은 아파치 소프트웨어 재단이 개발하는 오픈 소스 빌드 도구이다. ‘아파치 앤트(Ant)’의 후속으로 개발되었고, 자바 프로그램 개발을 대상으로 한 오픈 소스 빌드 도구이다.
메이븐 특징
빌드 파일은 XML로 작성
단위 작업 ‘골’ 골은 메이븐에서 실행하는 작업의 목적을 지정한다. 메이븐 명령어를 실행할 때 골을 지정하면, 어떤 작업을 수행하여 무엇을 작성할지 지정할 수 있다.
라이브러리 관리와 중앙 저장소 빌드를 실행하는 사이에, 빌드 파일에 기술된 정보를 바탕으로 필요한 라이브러리를 자동으로 다운로드하여 포함시킨다. 이를 가능하게 하는 것이 중앙 저장소이다. 중앙 저장소는 메이븐에서 이용 가능한 라이브러리를 모아서 관리하는 웹 서비스이다.
테스트와 문서 생성 엔트의 표준에는 포함되지 않았던 JUnit 테스트 및 Javadoc 문서 생성 등의 기능을 갖추고 있다.
플러그인을 이용한 확장 플러그인을 사용하면 메이븐에 기능을 추가할 수 있다.
메이븐 프로젝트 생성
메이븐에 포함된 **archetype:generate**라는 골을 이용하면, 간단하게 프로젝트의 기본 부분을 만들 수 있다. 아키타입(archetype)은 프로그램의 템플릿 모음이다.
Intellij를 이용해서도 메이븐을 기반으로 프로그램을 빌드하는 프로젝트를 생성할 수 있다. New Project -> 목록에서 Maven 선택 -> Create from archetype 체크 -> maven-archetype-quickstart 선택
메이븐에서는 mvn 명령어로 각종 조작을 할 수 있는데, 이 명령어들을 인텔리제이의 ‘Run’을 이용하여 실행할 수 있다. 실행할 내용을 컨피그레이션에 설정하면 인텔리제이의 ‘Run’으로 프로그램의 빌드와 실행, 디버그 등의 기능을 수행할 수 있다. (‘Run…’ -> Edit Configurations’ 메뉴에서 설정 가능)
pom.xml
pom.xml 파일에서 POM은 ‘Project Object Model’을 말한다. 이 파일에 프로젝트에 관한 각종 정보를 기술한다.
<project>와 기본속성
모델 버전
1
<modeVersion>4.0.0</modeVersion>
기본적으로 메이븐은 하위 호환성을 지원하기 때문에 이후 새로운 버전이 되더라도 이곳의 버전 번호를 바꾸면 이외 부분은 크게 수정하지 않고도 사용할 수 있다.
그룹 ID
1
<groupId>com.jongmin</groupId>
그룹 ID는 작성할 프로그램이 어디에 소속되어 있는지를 나타낸다.
아티팩트 ID
1
<artifactId>mvn-app</artifactId>
그룹 ID와 함께 프로그램을 식별하는 데 사용된다. ID이기 때문에 같은 그룹 내에서 같은 프로젝트 이름이 중복되지 않도록 주의해야 한다.
버전
1
<version>1.0-SNAPSHOT</version>
메이븐을 사용하는 프로젝트를 빌드하거나 패키징한 경우 여기서 지정된 번호가 생성된 프로그램의 버전으로 설정된다. 보통은 생성된 JAR 파일의 파일명에도 사용된다.
패키지 종류
1
<packaging>jar</packaging>
보통은 jar을 지정하지만, zip이라고 지정하면 ZIP 파일로 패키징한다.
애플리케이션 이름
1
<name>mvn-app</name>
작성하는 애플리케이션의 이름을 지정한다. 그룹 ID나 아티팩트 ID와 달리 유일한 값일 필요가 없다.
<build>와 <plugins> 태그는 여러 개 사용할 수 없다. 반드시 1개씩 있고, 그 안에 모든 <plugin>을 모아서 사용한다.
메이븐의 골과 플러그인
exec:java 골은 플러그인을 사용해 추가된 것이다. 사실, 지금까지 사용했던 모든 골들도 플러그인으로 추가된 것이다.
compile : maven-compiler-plugin
package : maven-jar-plugin
test : maven-surefire-plugin
하지만 위의 플러그인은 표준으로 포함되어 있기 때문에 플러그인이라고 의식하지 못했던 것이다.
표준이 아닌 <plugin> 태그에 의해 추가된 플러그인의 골을 지정하는 경우에는 xx:xx와 같이 요소가 둘인 경우가 일반적이다. 플러그인 하나가 여러 골을 가질 수도 있기 때문에 ‘플로그인:골’ 형태로 기술한다.
<plugin>이 필수는 아니다. 플러그인으로 추가하여 이용하는 골이라고 해서 <plugin>에 기술하지 않으면 사용하지 못하는 것은 아니다. <plugin>은 플러그인에 포함된 설정 등의 정보를 기술하는 태그이다. 그렇기 때문에 설정이 필요하지 않으면 기술할 필요가 없다.
인텔리제이에서 사용하기
플러그인을 통해 개발 도구의 프로젝트로 변환이 가능하다.
1
mvn idea:idea
위 골을 실행하면 인텔리제이에서 프로젝트를 다루는데 필요한 파일들이 생성된다.
1
mvn idea:clean
인텔리제이 프로젝트에서 인텔리제이 관련 파일을 삭제하여 원래의 메이븐 프로젝트로 돌리려면 위의 골을 실행한다.
실행 가능한 JAR 파일 만들기
앞서 mvn package로 패키징했지만 이렇게 생성된 JAR 파일은 단순히 패키징 된 것이기 때문에 실행되지는 않는다.
1
java -jar 00.jar
따라서 위의 명렁을 실행해도 00.jar에 기본 Manifest 속성이 없어 실행에 실패하게 된다.
실행 가능한 JAR 파일을 만들기 위해서는 maven-jar-plugin을 이용해 다음과 같은 <plugin> 태그를 작성하면 된다.
Java 개발자라면 꼭 읽어보아야 한다는 Effective Java 책이다. Java 언어를 처음 접하는 개발자보다는 어느정도 Java를 이용해 개발을 하고 있는 개발자에게 많이 추천되는 책이다. 실제 책 도입 부분에서도 Java 언어를 처음 공부하는 개발자 보다는 중급 이상의 프로그래머 반열에 오르려면 반드시 읽어야 할 내용들을 포함하고 있다고 말하고 있다.
나는 아무래도 이직 후 자바 개발과 스프링 프레임워크를 처음 접하게 되었는데, 자바 웹 애플리케이션 개발 전반에 대해 이해하고자 스프링 관련된 서적을 먼저 읽고 있었지만, 여러 팀 동료분들이 코드리뷰를 해주시면서 “이펙티브 자바” 책을 읽어보면 도움이 많이 될 것 같다고 조언해주셔서 읽어보게 되었다.
이 책은 총 78개의 규칙으로 구성되어 있으며, 각 규칙은 최고의 프로그래머와 노련한 프로그래머 대부분이 유용하다고 믿는 지침들을 요약한 것이다. 책에서 등장하는 첫 번째 규칙이 **”규칙 1. 생성자 대신 정적 팩터리 메서드를 사용할 수 없는지 생각해 보라”**인데, 동료분께 코드리뷰 받으면서 조언 받았던 부분이기도 했다. 그래서 첫 부분부터 아주 재밌게 읽어나갔다. 그 외에도 평소 코드리뷰에서 말씀해 주셨던 여러 내용들을 이 책을 통해 자세하게 알 수 있었다.
책 자체 내용은 쉽게 읽을 수 있는 정도는 아니었다. 오히려 이해하기 위해 고민하는 부분에서 깨닫게 되는 부분도 많은것 같다. (특히 제네릭 부분과 병행성 부분은 아직도 좀 어려운데 이 부분은 앞으로 어느 정도 시간이 지난 후 다시 읽어보면 또 다르게 받아들여지지 않을까 싶다.) 결과적으로 책을 읽고 난 후, 이부분을 개발할 때는 어떤 부분을 고려해 보아야 겠다라는 생각이 조금은 들게 된것 같다.
책 자체는 얇지는 않지만 각 파트 별로 여러개의 규칙으로 구성되어 있고, 각 규칙들은 정말 길어봐야 5~6장 정도의 분량이기 때문에 짬내서 읽기에도 좋았던것 같다. Java를 사용해 개발하고 있는 개발자 분들 중 읽어 보시지 않은 분들이 계시다면 꼭 추천드리고 싶은 책이다.
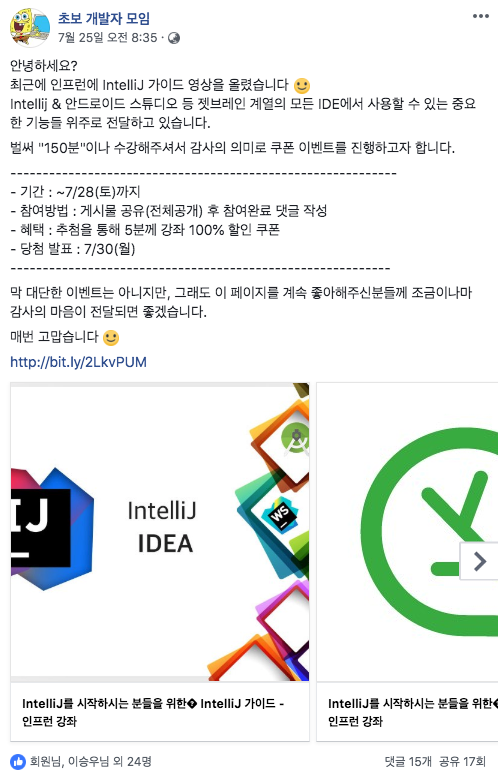
오오…? 당첨된 것이다. 신가하게 개발 서적 혹은 강의 관련된 이벤트에 자주 당첨되는것 같다. 자세히 보니 5명 뽑는 이벤트에 15명이 지원한건가… 그래도 당첨됐다는 사실에 기뻤다! 평소에 자주보는 페이지이기도 하고 위의 IntelliJ 강의는 처음 나왔을 때, 들어보고 싶었다는 생각이 있었지만 공부할게 너무 많아 미뤄놨었는데 마침 당첨된 기념으로 월요일 퇴근 후 바로 끝장을 보았다.
어디에 도움이 될까?
대부분의 개발자는 자신만의 개발 환경을 구축해서 사용한다. 예를 들면, 자신만의 dot file 들을 만들어 사용한다던가 IDEA의 세팅들을 커스터마이징해서 사용하는 것들이 있다. 나도 처음에는 IDEA의 “자동 정렬”과 같은 가장 간단한 단축키부터 사용하기 시작해 현재는 IntelliJ에 IdeaVim 플러그인 설치해서 사용할 정도로 나만의 개발환경을 구축하는데 적지 않은 시간을 쏟았다.
처음에는 물론 사용하기 쉽지 않다. 그러나 적응하기 시작하는 순간 엄청난 생산성의 향상을 가져온다. 손이 마우스로 가지 않고 vim을 사용하면 심지어 방향키 까지도 손이 가지 않는다.
이런 개발 환경을 구축하는데 있어 한가지 문제가 있다. 어떤 기능들이 있는지 알아야 찾아서 사용할텐데 어떤 기능들이 있는지 조차 파악하기가 마냥 쉬운게 아니라는 것이다. 대부분 내가 모르는 기능을 누군가 사용할때는 “이런 기능이 있었어?” 라는 반응이 많은데 이게 문제다! 한 번 사용하면 계속 사용하게 되는데 처음 사용하기가 어려운 이유이기도 하다.
다행히도 위의 강의는 이런 문제를 해소해준다! IntelliJ를 처음 사용하는 사람도! 이미 사용하고 있던 사람도! 모두 도움이 될 것이다. 어떤 기능이 있는지, 해당 기능을 어떤 단축키를 통해 사용할 수 있는지 강의를 보고 배워보자!
강의를 수강하며 새롭게 알게된 기능중 라인 합치기의 경우 Vim의 Shift + J 단축키를 이용해 사용하고 있었는데, 단순히 두 라인을 합쳐주는 기능하는 걸 넘어서, IntelliJ의 Shift + Cmd + J는 문자열을 합칠 경우 더 유용하게 사용 가능했다. 그래서 Shift + Cmd + J를 Shift + J로 변경해버렸다!
단축키
수강하며 실습해 볼 수 있는 단축키 리스트
코드 템플릿 메인 메소드 : psvm System.out.println() : sout
실행환경 실행 현재 포커스 : Ctrl + Shift + R 이전 실행 : Ctrl + R
코드 Edit 메인 메소드 실행 : 라인 복사 : Cmd + D 라인 삭제 : Cmd + 백스페이스 라인 합치기 : Ctrl + Shift + J 라인 이동 : Shfit + Option + 위 (아래) 구문 이동 : Shift + Cmd + 위 (아래) Element 단위 이동 : Option + Shift + Cmd + 좌 (우) 인자값 즉시 보기 : Cmd + P 코드 구현부 즉시 보기 : Option + Space Doc 즉시 보기 : F1
포커스 단어별 이동 : Option + <, > 단어별 선택 : Shift + Option + <, > 라인 첫/끝 이동 : Fn + <, > 라인 전체 선택 : Shift + Cmd + <, > / Shift + Fn + <, > Page Up/Down : Fn + 위/아래 포커스 범위 한 단계씩 늘리기 : Option + 위 (아래) 포커스 뒤로/앞으로 가기 : Cmd + [, ] 멀티 포커스 : Option + Option + 아래 오류 라인 자동 포커스 : F2
검색 현재 파일에서 검색 : Cmd + F 현재 파일에서 교체 : Cmd + R 전체에서 검색 : Shift + Cmd + F 전체에서 교체 : Shift + Cmd + R 정규표현식으로 검색, 교체 : Regex 체크 파일 검색 : Shift + Cmd + O 메소드 검색 : Option + Cmd + O Action 검색 : Shift + Cmd + A 최근 열었던 파일 목록 보기 : Cmd + E 최근 수정했던 파일 목록 보기 : Shift + Cmd + E
자동완성 스마트 자동 완성 : Shift + Ctrl + Space 스태틱 메소드 자동 완성 : Ctrl + Space + Space Getter/Setter/생성자 자동 완성 : Cmd + N Override 메소드 자동완성 : Ctrl + I Live Template 목록 보기 : Cmd + J
리팩토링 변수 추출하기 : Cmd + Option + V 파라미터 추출하기 : Cmd + Option + P 메소드 추출하기 : Cmd + Option + M 이너클래스 추출하기 : F6 이름 일괄 변경하기 : Shift + F6 타입 일괄 변경하기 : Shift + Cmd + F6 Import 정리하기 : Ctrl + Option + O 코드 자동 정렬하기 : Cmd + Option + L
디버깅 Debug 모드로 실행하기 (현재 위치의 메소드) : Shift + Ctrl + D Debug 모드로 실행하기 (이전에 실행한 메소드) : Ctrl + D Resume (다음 브레이크 포인트로 이동하기) : Cmd + Option + R Step Over (현재 브레이크에서 다음 한줄로 이동하기) : F8 Step Into (현재 브레이크의 다음 메소드로 이동) : F7 Step Out (현재 메소드의 밖으로 이동) : Shift + F8 Evaluate Expression (브레이크된 상태에서 코드 사용하기) : Option + F8 Watch (브레이크 이후의 코드 변경 확인하기) : 단축키 X
Git Git View On : Cmd + 9 Git Option Popup : Ctrl + V Git History : Ctrl + V => 4 Branch : Ctrl + V => 7 Commit : Cmd + K Push : Shift + Cmd + K Pull : Shift + Cmd + A => git pull Github 연동하기 : Shift + Cmd + A => share GitHub
위의 메서드보다 람다식이 간결하고 이해하기 쉽다. 게다가 모든 메서드는 클래스에 포함되어야 하므로 클래스도 새로 만들어야 하고, 객체도 생성해야만 비로소 이 메서드를 호출할 수 있다. 그러나 람다식은 이 모든 과정없이 오직 람다식 자체만으로도 이 메서드의 역할을 대신할 수 있다.
또한, 람다식은 메서드의 매개변수로 전달되어지는 것이 가능하고, 메서드의 결과로 반환될 수도 있다. 람다식으로 인해 메서드를 변수처럼 다루는 것이 가능해진 것이다.
람다식 작성하기
랃마식은 ‘익명 함수’답게 메서드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통{} 사이에 ‘->’를 추가한다.
반환값이 있는 경우, return문 대신 ‘식(expression)’으로 대신 할 수 있다. 식의 연산결과가 자동으로 반환값이 된다. 이때는 ‘문장(statement)’이 아닌 ‘식’이므로 끝에 ‘;’을 붙이지 않는다.
람다식에 선언된 매개변수의 타입은 추론이 가능한 경우는 생략할 수 있는데, 대부분의 경우에 생략가능하다. 람다식에 반환타입이 없는 이유도 항상 추론이 가능하기 때문이다.
매개변수가 하나뿐인 경우에는 괄호()를 생략할 수 있다. 단, 매개변수의 타입이 있으면 괄호()를 생략할 수 없다.
마찬가지로 괄호{}안의 문장이 하나일 때는 괄호{}를 생략할 수 있다. 이 때 문장의 끝에 ‘;’를 붙이지 않아야 한다. 그러나 괄호{} 안의 문장이 return문일 경우 괄호{}를 생략할 수 없다.
함수형 인터페이스(Funtional Interface)
자바에서 모든 메서드는 클래스 내에 포함되어야 한다. 사실 람다식은 익명 클래스의 객체와 동일하다.
하나의 메서드가 선언된 인터페이스를 정의해서 람다식을 다루는 것은 기존의 자바의 규칙들을 어기지 않으면서도 자연스럽다. 그래서 인터페이스를 통해 람다식을 다루기로 결정되었으며, 람다식을 다루기 위한 인터페이스를 함수형 인터페이스(functional interface)라고 부른다.
단, 함수형 인터페이스에는 오직 하나의 추상 메서드만 정의되어 있어야 한다는 제약이 있다. 그래야 람다식과 인터페이스의 메서드가 1:1로 연결 될 수 있기 때문이다. 반면에 static 메서드와 default 메서드의 개수에는 제약이 없다.
**@FunctionalInterface**를 붙이면, 컴파일러가 함수형 인터페이스를 올바르게 정의했는지 확인해주므로, 꼭 붙이는 것이 좋다.
함수형 인터페이스 타입의 매개변수와 반환타입 함수형 인터페이스 MyFunction이 아래와 같이 정의되어 있을 때,
람다식을 참조변수로 다룰 수 있다는 것은 메서드를 통해 람다식을 주고받을 수 있다는 것을 의미한다. 즉, 변수처럼 메서드를 주고받는 것이 가능해진 것이다. (사실상 메서드가 아니라 객체를 주고받는 것이라 달라진 것은 없다.)
람다식의 타입과 형변환 함수형 인터페이스로 람다식을 참조할 수 있는 것일 뿐, 람다식의 타입이 함수형 인터페이스의 타입과 일치하는 것은 아니다. 람다식은 익명 객체이고 익명 객체는 타입이 없다. 정확히는 타입은 있지만 컴파일러가 임의로 이름을 정하기 때문에 알 수 없는 것이다. 그래서 대입 연산자의 양변의 타입을 일치시키기 위해 형변환이 필요하다.
1
MyFunction f = (Myfunction)(() -> {});
람다식은 MyFunction 인터페이스를 직접 구현하지 않았지만, 이 인터페이스를 구현한 클래스의 객체와 완전히 동일하기 때문에 위처럼 형변환을 허용한다. 그리고 이 형변환은 생략가능하다.
람다식은 이름이 없을 뿐 객체인데도, Object 타입으로 형변환 할 수 없다. 람다식은 오직 함수형 인터페이스로만 형변환이 가능하다.
일반적인 익명 객체라면, 객체의 타입이 **’외부클래스이름$번호’**와 같은 형식으로 타입이 결정되었을 텐데, 람다식의 타입은 **’외부클래스이름$$Lambda$번호’**와 같은 형식으로 되어 있다.
외부 변수를 참조하는 람다식 람다식도 익명 객체, 즉 익명 클래스의 인스턴스이므로 람다식에서 외부에 선언된 변수에 접근하는 규칙은 익명 클래스와 동일하다.
람다식 내에서 참조하는 지역변수는 final이 붙지 않았어도 상수로 간주한다.(인스턴스 변수는 변경 가능) 람다식 내에서 지역변수를 참조하면 람다식 내에서나 다른 어느 곳에서도 이 변수의 값을 변경할 수 없다.
java.util.function 패키지
java.util.function 패키지에 일반적으로 자주 쓰이는 형식의 메서드를 함수형 인터페이스로 미리 정의해 놓았다. 매번 새로운 함수형 인터페이스를 정의하지 말고, 가능하면 이 패키지의 인터페이스를 활용하는 것이 좋다.
그래야 함수형 인터페이스에 정의된 메서드 이름도 통일되고, 재사용성이나 유지보수 측면에서도 좋다. 자주 쓰이는 가장 기본적인 함수형 인터페이스는 다음과 같다.
java.lang.Runnable
메서드 : void run()
매개변수도 없고, 반환값도 없음.
Supplier<T>
메서드 : T get()
매개변수는 없고, 반환값만 있음.
Consumer<T>
메서드 : void accept(T t)
Supplier와 반대로 매개변수만 있고, 반환값이 없음
Function<T, R>
메서드 : R apply(T t)
일반적인 함수, 하나의 매개변수를 받아서 결과를 반환
Predicate<T>
메서드 : boolean test(T t)
조건식을 표현하는데 사용됨.
타입 문자 ‘T’는 ‘Type’을, ‘R’은 ‘Return Type’을 의미한다.
인터페이스 이름 앞에 접두사 ‘Bi’가 붙으면 매개변수가 두 개인 함수형 인터페이스이다.
3개 이상의 매개변수를 갖는 함수형 인터페이스를 선언한다면 직접 만들어서 서야한다.
컬렉션 프레임웍의 인터페이스에 디폴트 메서드가 추가되었다.
Collection
boolean removeIf(Predicate<E> filter) : 조건에 맞는 요소를 삭제
List
void replaceAll(UnaryOperator<E> operator) : 모든 요소를 변환하여 대체
Iterable
void forEach(Consumer<T> action) : 모든 요소에 작업 action을 수행
Map
V compute(K key, BiFunction<K,V,V> f) : 지정된 키의 값에 작업 f를 수행
V computeIfAbsent(K key, BiFunction<K,V> f) : 키가 없으면, 작업 f 수행 후 추가
V computeIfPresentt(K key, BiFunction<K,V,V> f) : 지정된 키가 있을 때, 작업 f 수행
V merge(K key, V value, BiFunction<V,V,V> f) : 모든 요소에 병합작업 f를 수행
void forEach(BiConsumer<K,V> action) : 모든 요소에 작업 action을 수행
void replaceAll(BiFunction<K,V,V> f) : 모든 요소에 치환작업 f를 수행
래퍼클래스를 사용하는 것은 비효율적이다. 그래서 보다 효율적으로 처리할 수 있도록 기본형을 사용하는 함수형 인터페이스들이 제공된다.
ToIntFunction<T> : ToBFunction은 출력이 B타입이다. 입력은 generic 타입
intFunction<R> : AFunction은 입력이 A타입이고 출력은 generic 타입
ObjintConsumer<T> : ObjAFunction은 입력이 T, A타입이고 출력은 없다.
Function의 합성과 Predicate의 결합
java.util.function 패키지의 함수형 인터페이스에는 추상형메서드 외에도 디폴트 메서드와 static 메서드가 정의되어 있다.
Function의 합성 함수 f, g가 있을 때, **f.andThen(g)**는 함수 f를 먼저 적용하고, 그 다음에 함수 g를 적용한다. 그리고 **f.compose(g)**는 반대로 g를 먼저 적용하고 f를 적용한다.
1 2 3 4
Function<String, Integer> f = (s) -> Integer.parseInt(s, 16); Function<Integer, String> g = (i) -> Integer.toBinaryString(i); Function<String, String> h = f.andThen(g); Function<Integer, Integer> i = f.compose(g);
Predicate의 결합 여러 조건식을 논리 연산자로 연결해서 하나의 식을 구성할 수 있는 것처럼, 여러 Predicate를 and(), or(), negate()로 연결해서 하나의 새로운 Predicate를 결합할 수 있다.
메서드 참조
람다식을 더욱 간결하게 표현할 수 있는 방법이 있다. 람다식이 하나의 메서드만 호출하는 경우에는 메서드 참조라는 방법으로 람다식을 간략히 할 수 있다.
1 2 3 4 5
/// 변환 전 Function<String, Integer> f = (String s) -> Integer.parseInt(s);
/// 변환 후 Function<String, Integer> f = Integer::parseInt;
하나의 메서드만 호출하는 람다식은 ‘클래스이름::메서드이름’ 또는 ‘참조변수::메서드이름’
으로 바꿀 수 있다.
메서드 참조는 람다식을 마치 static 변수처럼 다룰 수 있게 해준다. 메서드 참조는 코드를 간략히 하는데 유용해서 많이 사용된다.
스트림(stream)
스트림이란?
스트림은 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓았다. 데이터 소스를 추상화했다는 것은, 데이터 소스가 무엇이던 간에 같은 방식으로 다룰 수 있게 되었다는 것과 코드의 재사용성이 높아진다는 것을 의미한다.
스트림은 일회용이다. 스트림은 Iterator처럼 일회용이다. 한번 사용하면 닫혀서 다시 사용할 수 없다. 필요하다면 스트림을 다시 생성해야 한다.
스트림은 작업을 내부 반복으로 처리한다. 내부 반복이라는 것은 반복문을 메서드의 내부에 숨길 수 있다는 것을 의미한다. forEach()는 스트림에 정의된 메서드 중의 하나로 매개변수에 대입된 람다식을 데이터 소스의 모든 요소에 적용한다. (forEach()는 메서드 안에 for문을 넣어버린 것이다.)
스트림의 연산 스트림이 제공하는 다양한 연산을 이용해서 복잡한 작업들을 간단히 처리할 수 있다.
중간 연산 : 연산 결과가 스트림인 연산. 스트림에 연속해서 중간 연산을 할 수 있음
최종 연산 : 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하므로 단 한번만 가능
지연된 연산 스트림 연산에서 한 가지 중요한 점은 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것이다. 중간 연산을 호출하는 것은 단지 어떤 작업이 수행되어야하는지를 지정해주는 것일 뿐이다. 최종 연산이 수행되어야 비로소 스트림의 요소들이 중간 연산을 거쳐 최종 연산에서 소모된다.
병렬 스트림 스트림으로 데이터를 다룰 때의 장점 중 하나가 병렬 처리가 쉽다는 것이다. 병렬 스트림은 내부적으로 fork&join을 이용해서 자동적으로 연산을 병렬로 수행한다. 모든 스트림은 기본적으로 병렬 스트림이 아니므로 병렬 스트림을 사용하려면 parallelStream() 메서드를 사용해 병렬 스트림으로 전환해야 한다.
스트림 만들기
스트림의 소스가 될 수 있는 대상은 배열, 컬렉션, 임의의 수 등 다양하다.
컬렉션 컬렉션의 최고 조상인 Collection에 stream()이 정의되어 있다. 그래서 Collection의 자손인 List와 Set을 구현한 컬렉션 클래스들은 모두 이 메서드로 스트림을 생성할 수 있다. stream()은 해당 컬렉션을 소스로 하는 스트림을 반환한다.
1
Stream<T> Collection.stream()
배열 배열을 소스로 하는 스트림을 생성하는 메서드는 다음과 같이 Stream과 Arrays에 static 메서드로 정의되어 있다.
1 2 3 4
Stream<T> Stream.of(T... values) Stream<T> Stream.of(T[]) Stream<T> Arrays.stream(T[]) Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive)
그리고 int, long, double과 같은 기본형 배열을 소스로 하는 스트림을 생성하는 메서드도 있다.
1 2 3 4
IntStream IntStream.of(int ...values) // 가변인자 IntStream IntStream.of(int[]) IntStream Arrays.stream(int[]) IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
특정 범위의 정수 IntStream과 LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성해서 반환하는 range()와 rangeClosed()를 가지고 있다.
임의의 수 난수를 생성하는데 사용하는 Random 클래스에는 해당 타입의 난수들로 이루어지는 스트림을 반환하는 인스턴스 메서드들이 포함되어 있다.
스트림의 중간연산
스트림 자르기 - skip(), limit() skip()과 limit()은 스트림의 일부를 잘라낼 때 사용한다.
스트림의 요소 걸러내기 - filter(), distinct() distinct()는 스트림에서 중복된 요소들을 제거하고, filter()는 주어진 조건(Predicate)에 맞지 않는 요소를 걸러낸다.
정렬 - sorted() 스트림을 정렬할 때는 sorted()를 사용하면 된다.
sorted()는 지정된 Comparator로 스트림을 정렬하는데, Comparator대신 int값을 반환하는 람다식을 사용하는 것도 가능하다. Comparator를 지정하지 않으면 스트림 요소의 기본 정렬 기준(Comparable)으로 정렬한다. 단, 스트림의 요소가 Comparable을 구현한 클래스가 아니면 예외가 발생한다.
JDK 1.8부터 Comparator 인터페이스에 static 메서드와 디폴트 메서드가 많이 추가되었는데, 이 메서드들을 이용하면 정렬이 쉬워진다. 이 메서드들은 모두 Comparator<T>를 반환한다.
변환 - map() 스트림의 요소에 저장된 값 중에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 때가 있다. 이 때 사용하는 것이 바로 map()이다. 이 메서드의 선언부는 아래와 같으며, 매개변수로 T타입을 R타입으로 변환해서 반환하는 함수를 지정해야한다.
1
Stream<R> map(Function<? super T,? extends R> mapper)
조회 - peek() 연산과 연산 사이에 올바르게 처리되었는지 확인하고 싶다면, peek()를 사용한다. forEach()와 달리 스트림의 요소를 소모하지 않으므로 연산 사이에 여러 번 끼워 넣어도 문제가 되지 않는다.
filter()나 map()의 결과를 확인할 때 유용하게 사용될 수 있다.
mapToInt(), mapToLong(), mapToDouble() map()은 연산의 결과로 Stream<T> 타입의 스트림을 반환하는데, 스트림의 요소를 숫자로 변환하는 경우 IntStream과 같은 기본형 스트림으로 변환하는 것이 더 유용할 수 있다.
count()만 지원하는 Stream<T>와 달리 IntStream과 같은 기본형 스트림은 아래와 같이 숫자를 다루는데 편리한 메서드들을 제공한다.
sum()과 average()를 모두 호출해야할 때, 스트림을 또 생성해야하므로 불편하다. 그래서 summaryStatistics()라는 메서드가 따로 제공된다.
반대로 IntStream을 Stream<T>로 변환할 때는 mapToObj()를, Stream<Integer>로 변환할 때는 boxed()를 사용한다.
1 2 3
IntStream intStream = new Random().ints(1, 46); // 1~45 사이의 정수 Stream<String> lottoStream = intStream.distinct().limit(6).sorted().mapToObj(i -> i + ","); lottoStream.forEach(System.out::print);
flatMap() - Stream<T[]>를 Stream<T>로 변환 스트림의 요소가 배열이거나 map()의 연산결과가 배열인 경우, 즉 스트림의 타입이 Stream<T[]>인 경우, Stream<T>로 다루는 것이 더 편리할 때가 있다. 그럴 때는 map()대신 flatMap()을 사용하면 된다.
1 2 3 4
Stream<String[]> strArrStrm = Stream.of( new String[]{"abc", "def", "ghi"}, new String[]{"ABC", "GHI", "JKLMN"} );
Optional<String> optVal = Optional.of("abc"); String str1 = optVal.get(); // optVal에 저장된 값을 반환. null이면 예외 발생 String str2 = optVal.orElse(""); // optVal에 저장된 값이 null일 때는, ""을 반환
**orElse()**의 변형으로 null을 대체할 값을 반환하는 람다식을 지정할 수 있는 **orElseGet()**과 null일 때 지정된 예외를 발생시키는 **orElseThrow()**가 있다.
1 2
String str3 = optVal2.orElseGet(String::new); // () -> new String()과 동일 String str4 = optVal2.orElseThrow(NullPointerException::new); // null이면 예외 발생
Stream처럼 Optional 객체에도 filter()와 map(), 그리고 flatMap()을 사용할 수 있다.
**isPresent()**는 Optional 객체의 값이 null이면 false를, 아니면 true를 반환한다. **ifPresent()**은 값이 있으면 주어진 람다식을 실행하고 , 없으면 아무 일도 하지 않는다. ifPresent()는 Optional<T>를 반환하는 findAny()나 findFirst()와 같은 최종 연산과 잘 어울린다.
스트림의 최종 연산
최종 연산은 스트림의 요소를 소모해서 결과를 만들어낸다. 그래서 최종 연산후에는 스트림이 닫히게 되고 더 이상 사용할 수 없다. 최종 연산의 결과는 스트림 요소의 합과 같은 단일 값이거나, 스트림의 요소가 담긴 배열 또는 컬렉션일 수 있다.
forEach() 반환 타입이 void이므로 스트림의 요소를 출력하는 용도로 많이 사용된다.
1
voidforEach(Consumer<? super T> action)
조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny() 스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는지, 일부가 일치하는지 아니면 어떤 요소도 일치하지 않는지 확인하는데 사용할 수 있는 메서드들이다. 이 메서드들은 모두 매개변수로 Predicate를 요구하며, 연산결과로 boolean을 반환한다.
통계 - count(), sum(), average(), max(), min() IntStream과 같은 기본형 스트림에는 스트림의 요소들에 대한 통계 정보를 얻을 수 있는 메서드들이 있다. 대부분의 경우 위의 메서드를 사용하기보다 기본형 스트림으로 변환하거나 reduce()와 collect()를 사용해 통계 정보를 얻는다.
리듀싱 - reduce() 스트림의 요소를 줄여나가면서 연산을 수행하고 최종결과를 반환한다. 처음 두 요소를 가지고 연산한 결과를 가지고 그 다음 요소와 연산한다. 그래서 매개변수의 타입이 BinaryOperator<T>인 것이다. 이 과정에서 스트림의 요소를 하나씩 소모하게 되며, 스트림의 모든 요소를 소모하게 되면 그 결과를 반환한다.
최종 연산 count()와 sum() 등은 내부적으로 모두 reduce()를 이용해서 작성되어 있다.
1 2 3 4
int count = intStream.reduce(0, (a,b) -> a + 1); // count() int sum = intStream.reduce(0, (a,b) -> a + b); // sum() int max = intStream.reduce(Integer.MIN_VALUE, (a,b) -> a>b ? a:b); // max() int min = intStream.reduce(Integer.MAX_VALUE, (a,b) -> a<b ? a:b); // min()
Collect()
**collect()는 스트림의 요소를 수집하는 최종 연산으로 리듀싱(reducing)과 유사하다. **collect()가 스트림의 요소를 수집하려면, 어떻게 수집할 것인가에 대한 방법이 정의되어 있어야 하는데, 이 방법을 정의한 것이 바로 컬렉터(collector)이다.
컬렉터는 Collector 인터페이스를 구현한 것으로, 직접 구현할 수도 있고 미리 작성된 것을 사용할 수도 있다. Collectors 클래스는 미리 작성된 다양한 종류의 컬렉터를 반환하는 static 메서드를 갖고 있다.
collect() : 스트림의 최종연산, 매개변수로 컬렉터를 필요로 한다.
Collector : 인터페이스, 컬렉터는 이 인터페이스를 구현해야 한다.
Collectors : 클래스, static 메서드로 미리 작성된 컬렉터를 제공한다.
스트림을 컬렉션과 배열로 변환 - toList(), toSet(), toMap(), toCollection(), toArray() List나 Set이 아닌 특정 컬렉션을 지정하려면, toCollection()에 해당 컬렉션의 생성자 참조를 매개변수로 넣어주면 된다.
1 2 3 4
List<String> names = stuStream.map(Student::getName) .collect(Collectors.toList()); ArrayList<String> list = names.stream() .collect(Collectors.toCollection(ArrayList::new));
Map은 키와 값의 쌍으로 저장해야하므로 객체의 어떤 필드를 키로 사용할지와 값으로 사용할지를 지정해줘야 한다.
스트림에 저장된 요소들을 ‘T[]’ 타입의 배열로 변환하려면, toArray()를 사용하면 된다. 단, 해당 타입의 생성자 참조를 매개변수로 지정해줘야 한다. 만일 매개변수를 지정하지 않으면 반환되는 배열의 타입은 ‘Object[]’이다.
1 2 3
Student[] stuNames = studentStream.toArray(Student[]::new); // OK Student[] stuNames = studentStream.toArray(); // 에러 Object[] stuNames = studentStream.toArray(); // OK
통계 - countint(), summingInt(), averagingInt(), maxBy(), minBy() 최종 연산들이 제공하는 통계 정보를 collect()로 똑같이 얻을 수 있다.
리듀싱 - reducing() 리듀싱 역시 collect()로 가능하다.
1 2 3 4 5 6 7
IntStream intStream = new Random().ints(1, 46).distinct().limit(6);
OptionalInt max = intStream.reduce(Integer::max); Optional<Integer> max = intStream.boxed().collect(reducing(Integer::max));
long sum = intStream.reduce(0, (a, b) -> a + b); long sum = intStream.boxed().collect(reducing(0, (a, b) -> a + b));
1 2
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0, Integer::sum); int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum));
문자열 결합 - joining() 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환한다. 구분자를 지정해줄 수도 있고, 접두사와 접미사도 가능하다. 스트림의 요소가 String이나 StringBuffer처럼 CharSequence의 자손인 경우에만 결합이 가능하므로 스트림의 요소가 문자열이 아닌 경우에는 먼저 map()을 이용해서 스트림의 요소를 문자열로 변환해야 한다.
만일 map()없이 스트림에 바로 joining()하면, 스트림의 요소에 toString()을 호출한 결과를 결합한다.
그룹화와 분할 - groupingBy, partitioningBy() 그룹화는 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미하고, 분할은 스트림의 요소를 두 가지, 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로의 분할을 의미한다. 스트림을 두 개의 그룹으로 나눠야 한다면, partitioningBy()로 분할하는 것이 더 빠르다. 그 외에는 groupingBy()를 쓰면 된다. 그룹화와 분할의 결과는 Map에 반환된다.
Object[] toArray(Object[] a) : 지정된 배열에 Collection의 객체를 저장해서 반환한다.
List 인터페이스
List 인터페이스는 중복을 허용하면서 저장순서가 유지되는 컬렉션을 구현하는데 사용된다.
void add(int index, Object element) : 지정된 위치(index)에 객체(element) 또는 컬렉션에 포함된 객체들을 추가한다.
Object get(int index) : 지정된 위치(index)에 있는 객체를 반환한다.
int indexOf(Object o) : 지정된 객체의 위치(index)를 반환한다. (List의 첫 번째 요소부터 순방향으로 찾는다.)
lastIndexOf(Object o) : 지정된 객체의 위치(index)를 반환한다. (List의 마지막 요소부터 역방향으로 찾는다.)
ListIterator listIterator() : List의 객체에 접근할 수 있는 ListIterator를 반환한다.
Object remove(int index) : 지정된 위치(index)에 있는 객체를 삭제하고 삭제된 객체를 반환한다.
Object set(int index, Object element) : 지정된 위치(index)에 객체(element)를 저장한다.
void sort(Comparator c) : 지정된 비교자(comparator)로 List를 정렬한다.
List subList(int fromIndex, int toIndex) : 지정된 범위(fromIndex 부터 toIndex)에 있는 객체를 반환한다.
Set 인터페이스
Set 인터페이스는 중복을 허용하지 않고 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용된다.
Map 인터페이스
Map 인터페이스는 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스를 구현하는 데 사용된다. 키는 중복될 수 없지만 값은 중복을 허용한다. 구현 클래스로는 Hashtable, HashMap, LinkedHashMap, SortedMap, TreeMap 등이 있다.
void clear() : Map의 모든 객체를 삭제한다.
boolean containsKey(Object key) : 지정된 key객체와 일치하는 Map의 Key객체가 있는지 확인한다.
boolean containsValue(Object value) : 지정된 value객체와 일치하는 Map의 Value객체가 있는지 확인한다.
Set entrySet() : Map에 저장되어 있는 key-value 쌍을 Map.Entry 타입의 객체로 저장한 Set으로 반환한다.
booelan equals(Object o) : 동일한 Map인지 비교한다.
Object get(Object key) : 지정한 key객체에 대응하는 value객체를 찾아서 반환한다.
void putAll(Map t) : 지정된 Map의 모든 key-value 쌍을 추가한다.
Object remove(Object key) : 지정한 key객체와 일치하는 key-value객체를 삭제한다.
int size() : Map에 저장된 key-value 쌍의 개수를 반환한다.
Collection values() : Map에 저장된 모든 value객체를 반환한다.
Map 인터페이스에서 값(value)은 중복을 허용하기 때문에 Collection 타입으로 반환하고, 키(key)는 중복을 허용하지 않기 때문에 Set 타입으로 반환한다.
Map.Entry 인터페이스
Map.Entry 인터페이스는 Map 인터페이스의 내부 인터페이스이다. 내부 클래스와 같이 인터페이스도 인터페이스 안에 인터페이스를 정의하는 내부 인터페이스(inner interface)를 정의하는 것이 가능하다.
Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의해 놓았다.
boolean equals(Object o) : 동일한 Entry인지 비교한다.
Object getKey() : Entry의 key객체를 반환한다.
Object getValue() : Entry의 value객체를 반환한다.
int hashCode() : Entry의 해시코드를 반환한다.
Object setValue(Object value) : Entry의 value객체를 지정된 객체로 바꾼다.
ArrayList
List 인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용한다는 특징을 갖는다.
ArrayList는 기존의 Vector를 개선한 것으로 Vector와 구현원리와 기능적인 측면은 동일하다.
ArrayList는 Object배열을 이용해서 데이터를 순차적으로 저장한다. 계속 배열에 순서대로 저장되며, 배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장된다.
(Vector는 capacity가 부족할 경우 자동적으로 기존의 크기보다 2배의 크기로 증가된다. 그러나 생성자 Vector(int initialCapacity, int capacityIncrement)를 사용해서 인스턴스를 생성한 경우에는 지정해준 capacityIncrement만큼 증가하게 된다.)
배열은 크기를 변경할 수 없기 때문에 ArrayList나 Vector 같이 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는 데는 효율이 좋지만, 용량을 변경해야 할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야하기 때문에 상당히 효율이 떨어진다는 단점을 가지고 있다.
LinkedList
배열은 가장 기본적인 형태의 자료구조로 구조가 간단하며 사용하기 쉽고 데이터를 읽어오는데 걸리는 시간(접근시간, access time)이 가장 빠르다는 장점을 가지고 있지만 다음과 같은 단점도 가지고 있다.
크기를 변경할 수 없다.
크기를 변경할 수 없으므로 새로운 배열을 생성해서 데이터를 복사하는 작업이 필요 하다.
실행속도를 향상시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르지만,
배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야 한다.
이러한 배열의 단점을 보완하기 위해서 링크드 리스트(linked list)라는 자료구조가 고안되었다. 배열은 모든 데이터가 연속적으로 존재하지만 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어 있다.
링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
1 2 3 4
classNode{ Node next; // 다음 요소의 주소를 저장 Object obj; // 데이터를 저장 }
링크드 리스트는 이동방향이 단방향이기 때문에 다음 요소에 대한 접근은 쉽지만 이전요소에 대한 접근은 어렵다. 이 점을 보완한 것이 더블 링크드 리스트(이중 연결리스트, doubly linked list)이다.
더블 링크드 리스트는 링크드 리스트보다 각 요소에 대한 접근과 이동이 쉽기 때문에 링크드 리스트보다 더 많이 사용된다.
1 2 3 4 5
classNode{ Node next; // 다음 요소의 주소를 저장 Node previous; // 이전 요소의 주소를 저장 Object obj; // 데이터를 저장 }
더블 링크드 리스트의 접근성을 보다 향상시킨 것이 ‘더블 써큘러 링크드 리스트(이중 연결형 연결 리스트)’이다. 단순히 더블 링크드 리스트의 첫 번째 요소와 마지막 요소를 서로 연결시킨 것이다.
실제로 LinkedList 클래스는 이름과 달리 ‘링크드 리스트’가 아닌 ‘더블 링크드 리스트’로 구현되어 있는데, 이는 링크드 리스트의 단점인 낮은 접근성(accessability)을 높이기 위한 것이다.
순차적으로 추가/삭제하는 경우에는 ArrayList가 LinkedList보다 빠르다. 만약 ArrayList의 크기가 충분하지 않으면, 새로운 크기의 ArrayList를 생성하고 데이터를 복사하는 일이 발생하게 되므로 순차적으로 데이터를 추가해도 ArrayList보다 LinkedList가 더 빠를 수 있다. 순차적으로 삭제한다는 것은 마지막 데이터부터 역순으로 삭제해나간다는 것을 의미하며, ArrayList는 마지막 데이터부터 삭제할 경우 각 요소들의 재배치가 필요하지 않기 때문에 상당히 빠르다. (단지 마지막 요소의 값을 null로만 바꾸면 되기 때문이다.)
중간 데이터를 추가/삭제하는 경우에는 LinkedList가 ArrayList보다 빠르다. LinkedList는 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 상당히 빠르다. 반면에 ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 늦다. 사실 데이터의 개수가 그리 크지 않다면 어느 것을 사용해도 큰 차이가 나지는 않는다.
데이터의 개수가 많아질수록 데이터를 읽어 오는 시간, 즉 접근시간(access time)은 ArrayList가 LinkedList보다 빠르다. 배열의 경우 만일 n번째 원소의 값을 얻어 오고자 한다면 단순히 아래와 같은 수식을 계산함으로써 해결된다. (배열은 각 요소들이 연속적으로 메모리상에 존재하기 때문이다.)
n번째 데이터의 주소 = 배열의 주소 + n * 데이터 타입의 크기
그러나, LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이 아니기 때문에 처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
Stack과 Queue
순차적으로 데이터를 추가하고 삭제하는 스택에는 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합하지만, 큐는 데이터를 꺼낼 때 항상 첫 번째 저장된 데이터를 삭제하므로, ArrayList와 같은 배열기반의 컬렉션 클래스를 사용한다면 데이터를 꺼낼 때마다 빈 공간을 채우기 위해 데이터의 복사가 발생하므로 비효율적이다. 그래서 큐는 ArrayList보다 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
Stack의 메서드
boolean empty() : Stack이 비어있는지 알려준다.
Object peek() : Stack의 맨 위에 저장된 객체를 반환. pop()과 달리 Stack에서 객체를 꺼내지는 않음.
Object pop() : Stack의 맨 위에 저장된 객체를 꺼낸다.
Object push(Object item) : Stack에 객체(item)를 저장한다.
int search(Object o) : Stack에서 주어진 객체(o)를 찾아서 그 위치를 반환. 못찾으면 -1을 반환.
Object peek() : 삭제없이 요소를 읽어 온다. Queue가 비어있으면 null을 반환
자바에서는 스택을 Stack클래스로 구현하여 제공하고 있지만 큐는 Queue인터페이스로만 정의해 놓았을 뿐 별도의 클래스를 제공하고 있지 않다. 대신 Queue인터페이스를 구현한 클래스들이 있어서 이 들 중의 하나를 선택해서 사용하면 된다.
PriorityQueue
Queue인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼내게 된다는 특징이 있다. 그리고 null은 저장할 수 없다.
Deque(Double-Ended Queue)
Queue의 변형으로, 한 쪽 끝으로만 추가/삭제할 수 있는 Queue와 달리, Deque은 양쪽 끝에 추가/삭제가 가능하다. Deque의 조상은 Queue이며, 구현체로는 ArrayDeque와 LinkedList 등이 있다.
덱은 스택과 큐를 하나로 합쳐놓은 것과 같으며 스택으로 사용할 수도 있고, 큐로 사용할 수도 있다.
Iterator, ListIterator, Enumeration
Iterator, ListIterator, Enumeration은 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다. Enumeration은 Iterator의 구버젼이며, ListIterator는 Iterator의 기능을 향상 시킨 것이다.
Iterator
컬렉션 프레임웍에서는 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화하였다. 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator인터페이스를 정의하고, Collection인터페이스에는 Iterator를 반환하는 iterator()를 정의하고 있다.
iterator()는 Collection인터페이스에 정의된 메서드이므로 Collection인터페이스의 자손인 List와 Set에도 포함되어 있다. 그래서 List나 Set인터페이스를 구현하는 컬렉션은 iterator()가 각 컬렉션의 특징에 알맞게 작성되어 있다.
boolean hasNext() : 읽어 올 요소가 남아있는지 확인한다.
Object next() : 다음 요소를 읽어 온다. next()를 호출하기 전에 hasNext()를 호출해서 읽어 올 요소가 있는지 확인하는 것이 안전하다.
void remove() : next()로 읽어 온 요소를 삭제한다.
ListIterator와 Enumeration
Enumeration은 컬렉션 프레임웍이 만들어지기 이전에 사용하던 것으로 Iterator의 구버젼이라고 생각하면 된다.
ListIterator는 Iterator를 상속받아서 기능을 추가한 것으로, 컬렉션의 요소에 접근할 때 Iterator는 단방향으로만 이동할 수 있는 데 반해 ListIterator는 양방향으로의 이동이 가능하다. 다만 List인터페이스를 구현한 컬렉션에서만 사용할 수 있다.
Arrays
Arrays클래스에는 배열을 다루는데 유용한 메서드가 정의되어 있다. Arrays에 정의된 메서드는 모두 static메서드이다.
배열의 복사 - copyOf(), copyOfRagne()
copyOf()는 배열 전체를, copyOfRange()는 배열의 일부를 복사해서 새로운 배열을 만들어 반환한다. copyOfRange()에 지저왼 범위의 끝은 포함되지 안는다.
배열 채우기 - fill(), setAll()
fill()은 배열의 모든 요소를 지정된 값으로 채운다. setAll()은 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받는다. 이 메서드를 호출할 때는 함수형 인터페이스를 구현한 객체를 매개변수로 지정하던가 아니면 람다식을 지정해야 한다.
배열의 정렬과 검색 - sort(), binarySearch()
sort()는 배열을 정렬할 때, 그리고 배열에 저장된 요소를 검색할 때는 binarySearch()를 사용한다. binarySearch()는 배열에서 지정된 값이 저장된 위치(index)를 찾아서 반환하는데, 반드시 배열이 정렬된 상태이어야 올바른 결과를 얻는다. (검색한 값과 일치하는 요소가 여러 개 있다면, 이 중 어떤 것의 위치가 반환될지는 알 수 없다.)
문자열의 비교와 출력 - equals(), toString(), deepEquals(), deepToString()
toString()은 배열의 모든 요소를 문자열로 편하게 출력할 수 있다. toString은 일차원 배열에만 사용할 수 있으므로, 다차원 배열에서는 deepToString()을 사용해야 한다. deepToString()은 배열의 모든 요소를 재귀적으로 접근해서 문자열을 구성하므로 2차원뿐만 아니라 3차원 이상의 배열에 대해서도 동작한다.
equals()는 두 배열에 저장된 모든 요소를 비교해서 같으면 true, 다르면 false를 반환한다. equals()도 일차원 배열에만 사용가능하므로, 다차원 배열의 비교에는 deepEquals()를 사용해야 한다.
배열을 List로 변환 - asList(Object… a)
asList()는 배열을 List에 담아서 반환한다. 한 가지 주의할 점은 asList()가 반환한 List의 크기를 변경할 수 없다는 것이다. 저장된 내용은 변경 가능하나, 추가 또는 삭제가 불가능하다. 만약 크기를 변경할 수 있는 List가 필요하다면 다음과 같이 하면 된다.
1
List list = new ArrayList(Arrays.asList(1, 2, 3, 4, 5));
parallelXXX(), spliterator(), stream()
parallel로 시작하는 이름의 메서드는 빠른 결과를 얻기 위해 여러 쓰레드가 작업을 나누어 처리하도록 한다. spliterator()는 여러 쓰레드가 처리할 수 있게 하나의 작업을 여러 작업으로 나누는 Spliterator를 반환하며, stream()은 컬렉션을 스트림으로 변환한다.
Comparator와 Comparable
Comparator와 Comparable은 모두 인터페이스로 컬렉션을 정렬하는데 필요한 메서드를 정의하고 있으며, Comparable을 구현하고 있는 클래스들은 같은 타입의 인터페이스끼리 서로 비교할 수 있는 클래스들(주로 wrapper클래스)이 있으며, 기본적으로 오름차순으로 구현되어 있다. 그래서 Comparable을 구현한 클래스는 정렬이 가능하다는 것을 의미한다.
Comparator의 compare()와 Comparable의 compareTo()는 두 객체를 비교한다는 같은 기능을 목적으로 만들어 졌다. compareTo()는 반환값은 int지만 실제로는 비교하는 두 객체가 같으면 0, 비교하는 값보다 작으면 음수, 크면 양수를 반환하도록 구현해야한다. compare()도 객체를 비교해서 음수, 0, 양수 중의 하나를 반환하도록 구현해야한다.
Comparable : 기본 정렬기준(오름차순)을 구현하는데 사용.
Comparator : 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용
Arrays.sort()는 배열을 정렬할 때, Comparator를 지정해주지 않으면 저장하는 객체에 구현된 내용에 따라 정렬된다.
1 2
staticvoidsort(Object[] a)// 객체 배열에 저장된 객체가 구현한 Comparable에 의한 정렬 staticvoidsort(Object[] a, Comparator c)// 지정한 Comparator에 의한 정렬
HashSet
HashSet은 Set인터페이스를 구현한 가장 대표적인 컬렉션이며, Set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다.
ArrayList와 같이 List인터페이스를 구현한 컬렉션과 달리 HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
HashSet은 내부적으로 HashMap을 이용해서 만들어졌으며, HashSet이란 이름은 해싱(hasing)을 이용해서 구현했기 때문에 붙여진 것이다.
HashSet의 add메서드는 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해 추가하려는 요소의 equals()와 hashCode()를 호출하기 때문에 equals()와 hashCode()를 목적에 맞게 오버라이딩해야 한다.
오버라이딩을 통해 작성된 hashCode()는 다음의 세 가지 조건을 만족 시켜야 한다.
실행 중인 애플리케이션 내의 동일한 객체에 대해서 여러 번 hashCode()를 호출해도 동일한 int 값을 반환해야 한다. 하지만, 실행시마다 동일한 int값을 반환할 필요는 없다. (String 클래스는 문자열의 내용으로 해시코드를 만들어 내기 때문에 내용이 같은 문자열에 대한 hashCode() 호출은 항상 동일한 해시코드를 반환한다. 반면에 Object클래스는 객체의 주소로 해시코드를 만들어 내기 때문에 실행할 때마다 해시코드값이 달라질 수 있다.)
equals메서드를 이용한 비교에 의해서 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해서 얻은 결과는 반드시 같아야 한다.
equals메서드를 호출했을 때 false를 반환하는 두 객체는 hashCode() 호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮지만, 해싱(hashing)을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 int값을 반환하는 것이 좋다.
TreeSet
TreeSet은 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다. 이진 검색 트리는 정렬, 검색, 범위검색(range search)에 노은 성능을 보이는 자료구조이며 TreeSet은 이진 검색 트리의 성능을 향상시킨 ‘레드-블랙 트리(Red-Black tree)’로 구현되어 있다.
Set인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
HashMap과 Hashtable
Hashtable과 HashMap의 관계는 Vector와 ArrayList의 관계와 같아서 Hashtable보다는 새로운 버전인 HashMap을 사용할 것을 권한다.
HashMap은 Map을 구현했으므로 Map의 특징인 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로 저장한다는 특징을 갖는다. 그리고 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
HashMap은 Entry라는 내부 클래스를 다시 정의하고, 다시 Entry타입의 배열을 선언하고 있다. 키(key)와 값(value)은 별개의 값이 아니라 서로 관련된 값이기 때문에 각각의 배열로 선언하기 보다는 하나의 클래스로 정의해서 하나의 배열로 다루는 것이 데이터의 무결성적인 측면에서 더 바람직하기 때문이다.
HashMap은 키와 값을 각각 Object타입으로 저장한다. 즉 어떠한 객체도 저장할 수 있지만 키는 주로 String을 대문자 또는 소문자로 통일해서 사용하곤 한다.
Set entrySet() : HashMap에 저장된 키와 값을 엔트리(키와 값의 결합)의 형태로 Set에 저장해서 반환
Object put(Object key, Object value) : 지정된 키와 값을 HashMap에 저장
Collection values() : HashMap에 저장된 모든 값을 컬렉션의 형태로 반환
해싱과 해시함수
해싱이란 해시함수(hash function)을 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법을 말한다. 해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.
해싱에서 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어 있다.
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하게 된다.
검색하고자 하는 값의 키로 해시함수를 호출한다.
해시함수의 계산결과인 해시코드를 이용해서 해당 값이 저장되어 있는 링크드 리스트를 찾는다.
링크드 리스트에서 검색한 키와 일치하는 데이터를 찾는다.
링크드 리스트는 검색에 불리한 자료구조이기 때문에 링크드 리스트의 크기가 커질수록 검색속도가 떨어지게 된다.
하나의 링크드 리스트에 최소한의 데이터만 저장되려면, 저장될 데이터의 크기를 고려해서 HashMap의 크기를 적절하게 지정해주어야 하고, 해시함수가 서로 다른 키에 대해서 중복된 해시코드의 반환을 최소화해야 한다. 그래야 HashMap에서 빠른 검색시간을 얻을 수 있다.
실제로는 HashMap과 같이 해싱을 구현한 컬렉션 클래스에는 Object클래스에 정의된 hashCode()를 해시함수로 사용한다. Object클래스에 정의된 hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어 내기 때문에 모든 객체에 대헤 hashCode()를 호출한 결과가 서로 다른 좋은 방법이다.
String클래스의 경우 Object로부터 상속받은 hashCode()를 오버라이딩해서 문자열의 내용으로 해시코드를 만들어 낸다. 그래서 서로 다른 String인스턴스일지라도 같은 내용의 문자열을 가졌다면 hashCode()를 호출하면 같은 해시코드를 얻는다.
HashSet과 마찬가지로 HashMap에서도 서로 다른 두 객체에 대해 equals()로 비교한 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식한다. (이미 존재하는 키에 대한 값을 저장하면 기존의 값을 새로운 값으로 덮어쓴다.)
그래서 새로운 클래스를 정의할 때 equals()를 오버라이딩해다 한다면 hashCode()도 같이 오버라이딩해서 equals()의 결과가 true인 두 객체의 해시코드가 항상 같도록 해주어야 한다.
그렇지 않으면 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는 equals()의 호출결과가 true지만 해시코드가 다른 두 객체를 서로 다른 것으로 인식하고 따로 저장할 것이다.
TreeMap
TreeMap은 이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다. 그래서 검색과 정렬에 적합한 컬렉션 클래스이다.
검색에 관한 대부분의 경우에서는 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋다. 다만 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하자.
Properties
Properties는 HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로, Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 비해 Properties는 (String, String)의 형태로 저장하는 보다 단순화된 컬렉션클래스이다.
주로 애플리케이션의 환경설정과 관련된 속성(property)을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다.
Collections
Arrays가 배열과 관련된 메서드를 제공하는 것처럼, Collections는 컬렉션과 관련된 메서드를 제공한다. fill(), copy(), sort(), binarySearch() 등의 메서드는 두 클래스에 포함되어 있으며 같은 기능을 한다.
컬렉션의 동기화
멀티 쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체의 동기화(synchronization)가 필요하다.
Vector와 Hashtable과 같은 구버전(JDK1.2 이전)의 클래스들은 자체적으로 동기화처리가 되어 있는데, 멀티쓰레드 프로그래밍이 아닌 경우에는 불필요한 기능이 되어 성능을 떨어뜨리는 요인이 된다.
그래서 새로 추가된 ArrayList와 HashMap과 같은 컬렉션은 동기화를 자체적으로 처리하지 않고 필요한 경우에만 java.util.Collections클래스의 동기화 메서드를 이용해서 동기화처리가 가능하도록 변경하였다.
1 2 3 4 5 6
static Collection synchronizedCollection(Collection c) static List synchronizedList(List list) static Set synchronizedSet(Set s) static Map synchronizedMap(Map m) static SortedSet synchronizedSortedSet(SortedSet s) static SortedMap synchronizedSortedMap(SortedMap m)
변경불가 컬렉션 만들기
컬렉션에 저장된 데이터를 보호하기 위해서 컬렉션을 변경할 수 없게 읽기전용으로 만들어야 할 때가 있다.
1 2 3 4 5 6
static Collection unmodifiableCollection(Collection c) static List unmodifiableList(List list) static Set unmodifiableSet(Set s) static Map unmodifiableMap(Map m) static SortedSet unmodifiableSortedSet(SortedSet s) static SortedMap unmodifiableSortedMap(SortedMap m)
컬렉션 클래스 정리 & 요약
ArrayList : 배열기반, 데이터의 추가와 삭제에 불리, 순차적인 추가/삭제는 제일 빠름. 임의의 요소에 대한 접근성이 뛰어남.
LinkedList : 연결기반, 데이터의 추가와 삭제에 유리. 임의의 요소에 대한 접근성이 좋지 않다.
HashMap : 배열과 연결이 결합된 형태. 추가, 삭제, 검색, 접근성이 모두 뛰어남. 검색에는 최고성능을 보인다.
날짜/시간 및 타임존을 다루는 국제적인 규약은 다양하다. RFC 822, 1036, 1123, 2822, 3339, ISO 8601 등이 있다. 여기서는 ISO 8601과 RFC 3339와 관련된 표기법을 알아본다.
1 2 3 4 5 6 7 8
// 로컬 시간을 의미하는 ISO 8601 문자열 2017-11-06T15:00:00.000
// UTC(GMT) 시간을 의미하는 ISO 8601 문자열 2017-11-06T06:00:00.000Z
// 로컬 시간을 의미하면서 UTC(GMT) 대비 +09:00 임을 의미하는 ISO 8601 문자열 2017-11-06T15:00:00.000+09:00
2017-11-06T15:00:00.000은 ISO 8601의 기본 형식이다. 해당 시간이 로컬 시간 임을 의미한다.
2017-11-06T06:00:00.000Z와 같이 뒤에 Z 식별자를 추가하면 해당 시간이 UTC(GMT) 시간 임을 의미한다.
2017-11-06T15:00:00.000+09:00와 같이 뒤에 Z 대신 +HH:mm 식별자를 추가하면 해당 시간이 로컬 시간이면서 **UTC(GMT)**와 09:00 만큼 차이가 남을 의미한다. 이 형식의 장점은 인간이 손쉽게 추가적인 계산 없이 로컬 시간을 인지하면서 추가적으로 타임존 정보까지 제공하기 때문에 가장 인간친화적이라고 할 수 있다.
날짜와 시간
Date는 날짜와 시간을 다룰 목적으로 JDK 1.0부터 제공되어온 클래스이다. Date 클래스는 기능이 부족했기 때문에, Calendar라는 새로운 클래스를 그 다음 버젼인 JDK 1.1부터 제공하기 시작했다. Calendar는 Date보다는 훨씬 나았지만 몇 가지 단점들이 있었고, JDK 1.8부터 java.time 패키지로 기존의 단점들을 개선한 새로운 클래스들이 추가되었다.
Date 클래스는 java.util 패키지에 속해있다.
Date와 Calendar간의 변환
Calendar가 새로 추가되면서 Date는 대부분의 메서드가 ‘deprecated’되었으므로 잘 사용되지 않는다. 그럼에도 불구하고 여전히 Date를 필요로 하는 메서드들이 존재하기 때문에 Calendar를 Date로 또는 그 반대로 변환할 일이 생긴다.
1 2 3 4 5 6 7 8 9
1. Calendar를 Date로 변환 Calendar cal = Calendar.getInstance(); Date d1 = new Date(cal.getTimeInMillis()); // Date(long date) Date d2 = cal.getTime();
2. Date를 Calendar로 변환 Date d = new Date(); Calendar cal = Calendar.getInstance(); cal.setTime(d);
Calendar.getInstance()를 통해서 얻은 인스턴스는 기본적으로 현재 시스템의 날짜와 시간에 대한 정보를 담고 있다. (GregorianCalendar, BuddhistCalendar)
형식화 클래스
자바의 형식화 클래스는 java.text 패키지에 포함되어 있으며 숫자, 날짜, 텍스트 데이터를 일정한 형식에 맞게 표현할 수 있는 방법을 객체지향적으로 설계하여 표준화하였다. 형식화 클래스는 형식화에 사용될 패턴을 정의하는데, 데이터를 정의된 패턴에 맞춰 형식화할 수 있을 뿐만 아니라 역으로 형식화된 데이터에서 원래의 데이터를 얻어낼 수도 있다. 즉, 형식화된 데이터의 패턴만 정의해주면 복잡한 문자열에서도 substring()을 사용하지 않고도 쉽게 원하는 값을 얻어낼 수 있다는 것이다.
DecimalFormat
형식화 클래스 중에서 숫자를 형식화 하는데 사용되는 것이 DecimalFormat이다. DecimalFormat을 이용하면 숫자 데이터를 정수, 부동소수점, 금액 등의 다양한 형식으로 표현할 수 있으며, 반대로 일정한 형식의 테스트 데이터를 숫자로 쉽게 변환하는 것도 가능하다.
1 2 3
double number = 1234567.89; DecimalFormat df = new DecimalFormat("#.#E0"); String result = df.format(number);
Number 클래스는 Integer, Double과 같은 숫자를 저장하는 래퍼 클래스의 조상이며, doubleValue()는 Number에 저장된 값을 double형의 값으로 변환하여 반환한다. 이 외에도 intValue(), floatValue()등의 메서드가 Number클래스에 정의되어 있다.
SimpleDateFormat
Date와 Calendar만으로는 날짜 데이터를 원하는 형태로 다양하게 출력하는 것은 불편하고 복잡하다. 그러나 SimpleDateFormat을 사용하면 이러한 문제들이 간단하게 해결된다.
DateFormat은 추상클래스로 SimpleDateFormat의 조상이다. DateFormat는 추상클래스이므로 인스턴스를 생성하기 위해서는 getDateInstance()와 같은 static 메서드를 이용해야 한다. getDateInstance()에 의해서 반환되는 것은 DateFormat을 상속받아 완전하게 구현한 SimpleDateFormat 인스턴스이다.
1 2 3 4 5
Date today = new Date(); SimpleDateFormat dt = new SimpleDateFormat("yyyy-MM-dd");
// 오늘 날짜를 yyyy-MM-dd 형태로 변환하여 반환한다. String result = df.format(today);
Date 인스턴스만 format 메서드에 사용될 수 있다.
1 2
DateFormat df = new SimpleDateFormat("yyyy년 MM월 dd일"); Date d = df.parse("2018년 6월 6일");
parse(String source)를 사용하여 날짜 데이터의 출력형식을 변환하는 방법을 보여주는 예제이다. Integer의 parseInt()가 문자열을 정수로 변환하는 것처럼 SimpleDateFormat의 parse(String source)는 문자열(source)을 날짜(Date인스턴스)로 변환해주기 때문에 매우 유용하게 쓰일 수 있다.
ChoiceFormat
ChoiceFormat은 특정 범위에 속하는 값을 문자열로 변환해준다. 연속적 또는 불연속적인 범위의 값들을 처리하는 데 있어서 if문이나 switch문은 적절하지 못한 경우가 많다. 이럴때 ChoiceFormat을 잘 사용하면 복잡하게 처리될 수밖에 없었던 코드를 간단하고 직관적으로 만들 수 있다.
MessageFormat
MessageFormat은 데이터를 정해진 양식에 맞게 출력할 수 있도록 도와준다. 데이터가 들어갈 자리를 마련해 놓은 양식을 미리 작성하고 프로그램을 이용해서 다수의 데이터를 같은 양식으로 출력할 때 사용하면 좋다. 하나의 데이터를 다양한 양식으로 출력할 때 사용한다.
그리고 SimpleDateFormat의 parse처럼 MessageFormat의 parse를 이용하면 지정된 양식에서 필요한 데이터만을 손쉽게 추출해 낼 수도 있다.
String result = MessageFormat.format(msg, arguments);
MessageFormat에 사용될 양식인 문자열 msg를 작성할 때 ‘{숫자}’로 표시된 부분이 데이터가 출력될 자리이다.
데이터를 양식에 넣어서 출려하는것 뿐만 아니라, parse(String source)를 이용해서 출력된 데이터로부터 필요한 데이터만을 뽑아낼 수 있다.
Java.time 패키지
java의 탄생부터 지금까지 날짜와 시간을 다루는데 사용해왔던, Date와 Calendar가 가지고 있던 단점들을 해소하기 위해 JDK1.8부터 ‘java.time 패키지’가 추가되었다. 이 패키지는 다음과 같이 4개의 하위 패키지를 가지고 있다.
java.time : 날짜와 시간을 다루는데 필요한 핵심 클래스들을 제공
java.time.chrono : 표준(ISO)이 아닌 달력 시스템을 위한 클래스들을 제공
java.time.format : 날짜와 시간을 파싱하고, 형식화하기 위한 클래스들을 제공
java.time.temporal : 날짜와 시간의 필드(field)와 단위(unit)를 위한 클래스들을 제공
java.time.zone : 시간대(time-zone)와 관련된 클래스들을 제공
위의 패키지들에 속한 클래스들의 가장 큰 특징은 String 클래스처럼 **불변(immutable)**이라는 것이다. 그래서 날짜나 시간을 변경하는 메서드들은 기존의 객체를 변경하는 대신 항상 변경된 새로운 객체를 반환한다. 기존 Calendar 클래스는 변경 가능하므로, 멀티 쓰레드 환경에서 안전하지 못하다.
멀티 쓰레드 환경에서는 동시에 여러 쓰레드가 같은 개겣에 접근할 수 있기 때문에, 변경 가능한 객체는 데이터가 잘못될 가능성이 있으며, 이를 쓰레드에 안전(thread-safe)하지 않다고 한다.
java.time 패키지의 핵심 클래스
날짜와 시간을 하나로 표현하는 Calendar 클래스와 달리, java.time 패키지에서는 날짜와 시간을 별도의 클래스로 분리해 놓았다. 시간을 표현할 때는 LocalTime 클래스를 사용하고, 날짜를 표현할 때는 LocalDate 클래스를 사용한다. 그리고 날짜와 시간이 모두 필요할 때는 LocalDateTime 클래스를 사용하면 된다.
LocalDate + LocalTime -> LocalDateTime 날짜 시간 날짜 & 시간
여기에 시간대(time-zone)까지 다뤄야 한다면, ZonedDateTime 클래스를 사용한다.
LocalDateTime + 시간대 -> ZonedDateTime
Calendar는 ZonedDateTime처럼, 날짜와 시간 그리고 시간대까지 모두 가지고 있다. Date와 유사한 클래스로는 Instant가 있는데, 이 클래스는 날짜와 시간을 초 단위(정확히는 나노초)로 표현한다. 날짜와 시간을 초단위로 표현한 값을 타임스탬프(time-stamp) 라고 부르는데, 이 값은 날짜와 시간을 하나의 정수로 표현할 수 있으므로 날짜와 시간의 차이를 계산하거나 순서를 비교하는데 유리해서 데이터베이스에 많이 사용한다.
객체 생성하기 - now(), of()
java.time 패키지에 속한 클래스의 객체를 생성하는 가장 기본적인 방법은 now()와 of()를 사용하는 것이다.
LocalDate와 LocalTime은 java.time 패키지의 가장 기본이 되는 클래스이며, 나머지 클래스들은 이들의 확장이므로 이 두 클래스만 잘 이해하고 나면 나머지는 아주 쉬워진다.
객체를 생성하는 방법은 현재의 날짜와 시간을 LocalDate와 LocalTime으로 각각 반환하는 now()와 지정된 날짜와 시간으로 LocalDate와 LocalTime 객체를 생성하는 of()가 있다.
특정 필드의 값 가져오기 - get(), getXXX()
필드의 값 변경하기 - with(), plus(), minus()
날짜와 시간의 비교 - isAfter(), isBefore(), isEqual()
Instant
Instant는 에포크 타임(EPOCH TIME, 1970-01-01 00:00:00 UTC)부터 경과된 시간을 나노초 단위로 표현한다. 사람이 보기에는 불편하지만, 단일 진법으로 다루기 때문에 계산에는 편리하다. 사람이 사용하는 날짜와 시간에는 여러 진법이 섞여있어서 계산하기 어렵다.
Instant를 생성할 때는 위와 같이 now()와 ofEpochSecond()를 사용한다. 그리고 필드에 저장된 값을 가져올 때는 다음과 같이 한다.
1 2
long epochSec = now.getEpochSecond(); int nano = now.getNano();
위의 코드처럼, Instant는 시간을 초 단위와 나노초 단위로 나누어 저장한다. 오라클 데이터베이스의 타임스탬프(timestamp)처럼 밀리초 단위의 EPOCH TIME을 필요로 하는 경우를 위해 toEpochMilli()가 정의되어 있다.
1
longtoEpochMilli()
Instant는 항상 UTC(+00:00)를 기준으로 하기 때문에, LocalTime과 차이가 있을 수 있다. 예를 들어 한국은 시간대가 ‘+09:00’이므로 Instant와 LocalTime간에는 9시간의 차이가 있다. 시간대를 고려해야하는 경우 OffsetDateTime을 사용하는 것이 더 나은 선택일 수 있다.
UTC는 ‘Coordinated Universal Time’의 약어로 ‘세계 협정시’이라고 하며, 1972년 1월 1일부터 시행된 국제 표준시이다. 이전에 사용되던 GMT(Greenwich Mean Time)와 UTC는 거의 같지만, UTC가 좀 더 정확하다.
LocalDateTime과 ZonedDateTime
LocalDateTime에 시간대(time-zone)를 추가하면, ZonedDateTime이 된다. 기존에는 TimeZone클래스로 시간대를 다뤘지만 새로운 시간 패키지에서는 ZoneId라는 클래스를 사용한다. ZoneId는 일광 절약시간(DST, Daylight Saving Time)을 자동적으로 처리해주므로 더 편리하다.
LocalDate에 시간 정보를 추가하는 atTime()을 쓰면 LocalDateTime을 얻을 수 있는 것처럼, LocalDateTime에 atZone()으로 시간대 정보를 추가하면, ZonedDateTime을 얻을 수 있다.
UTC로부터 얼마만큼 떨어져 있는지를 ZoneOffSet으로 표현한다. 위의 결과에서 알 수 있듯이 서울은 ‘+9’이다. 즉, UTC보다 9시간(32400초=60*60*9)이 빠르다.
1 2
ZoneOffset krOffset = ZonedDateTime.now().getOffset(); int krOffsetInSec = KrOffset.get(ChronoField.OFFSET_SECONDS); // 32400초
OffsetDateTime
ZonedDateTime은 ZoneId로 구역을 표현하는데, ZoneId가 아닌 ZoneOffset을 사용하는 것이 OffSetDateTime이다. ZoneId는 일광절약시간처럼 시간대와 관련된 규칙들을 포함하고 있는데, ZoneOffset은 단지 시간대를 시간의 차이로만 구분한다. 컴퓨터에게 일광절약시간처럼 계절별로 시간을 더했다 뺐다 하는 것과 같은 행위는 위험하다. 아무런 변화 없이 일관된 시간체계를 유지하는 것이 더 안전하다. 같은 지역 내의 컴퓨터 간에 데이터를 주고 받을 때, 전송시간을 표현하기에 LocalDateTime이면, 충분하겠지만, 서로 다른 시간대에 존재하는 컴퓨터간의 통신에는 OffsetDateTime이 필요하다.
일광 절약 시간제(Daylight saving time, DST) 또는 서머 타임(summer time)은 하절기에 표준시를 원래 시간보다 한 시간 앞당긴 시간을 쓰는 것을 말한다. 즉, 0시에 일광 절약 시간제를 실시하면 1시로 시간을 조정해야 하는 것이다. 실제 낮 시간과 사람들이 활동하는 낮 시간 사이의 격차를 줄이기 위해 사용한다.
1 2 3 4 5
ZonedDateTime zdt = ZondedDateTime.of(date, time, zid); OffsetDateTime odt = offsetDateTime.of(date, time, krOffset);
// 특정 구역 시간의 다른 구역 시간 구하기 ZoneId nyId = ZoneId.of("America/New_York"); ZonedDateTime nyTime = ZonedDateTime.now().withZoneSameInstant(nyId); System.out.println("ZonedDateTime3 : " + nyTime);
with()는 LocalTime, LocalDateTime, ZonedDateTime, Instant 등 대부분의 날짜와 시간에 관련된 클래스에 포함되어 있다.
Period와 Duration
Period는 날짜의 차이를, Duration은 시간의 차이를 계산하기 위한 것이다.
between()
두 날짜 date1과 date2의 차이를 나타내는 Period는 between()으로 얻을 수 있다.
1 2 3
LocalDate date1 = LocalDate.of(2014, 1, 1); LocalDate date2 = LocalDate.of(2018, 6, 6); Period pe = Period.between(date1, date2)
date1이 date2보다 날짜 상으로 이전이면 양수로, 이후면 음수로 Period에 저장된다. 그리고 시간차이를 구할 때는 Duration을 사용한다는 것을 제외하고는 Period와 똑같다.
Period, Duration에서 특정 필드의 값을 얻을 때는 get()을 사용한다.
1 2 3 4 5 6
long year = pe.get(ChronoUnit.YEARS); // int getYears() long month = pe.get(ChronoUnit.MONTHS); // int getMonths() long day = pe.get(ChronoUnit.DAYS); // int getDays()
long sec = du.get(ChronoUnit.SECONDS); // long getSeconds() long nano = du.get(ChronoUnit.NANOS); // int getNano()
between()과 until()
until()은 between()과 거의 같은 일을 한다. between()은 static 메서드이고, until()은 인스턴스 메서드라는 차이가 있다.
Period는 년월일을 분리해서 저장하기 때문에, D-day를 구하려는 경우에는 두 개의 매개변수를 받는 until()을 사용하는 것이 낫다.
파싱과 포맷
날짜와 시간을 원하는 형식으로 출력하고 해석(파싱)을 위한 형식화(formatting)와 관련된 클래스들은 java.time.format 패키지에 들어 있다. 그 중에서 DateTimeFormatter가 핵심이다. 이 클래스에는 자주 쓰이는 다양한 형식들을 기본적으로 정의하고 있으며, 그 외의 형식이 필요하다면 직접 정의해서 사용할 수도 있다.