실습 코드들은 IntelliJ를 이용해 SpringBoot 2.1.3.RELEASE 버전 기반으로 프로젝트를 생성 후(web, lombok 포함) 진행했습니다.
이번에는 포스팅에서는 지난번 ListenableFuture를 사용하면서 발생한 콜백헬을 어떻게 개선할지에 대해서 이야기합니다. ListenableFuture를 Wrapping 하는 Completion이라는 클래스를 만들어, chainable하게 사용할 수 있는 방식으로 코드를 만들어봅니다. 콜백헬의 문제로는 에러를 처리하는 코드가 중복이 된다는 것도 있는데, 이 부분도 해결해봅니다.
@Bean public ThreadPoolTaskExecutor myThreadPool(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); te.setCorePoolSize(1); te.setMaxPoolSize(1); te.initialize(); return te; }
@Bean public ThreadPoolTaskExecutor myThreadPool(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); te.setCorePoolSize(1); te.setMaxPoolSize(1); te.initialize(); return te; }
@Bean public ThreadPoolTaskExecutor myThreadPool(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); te.setCorePoolSize(1); te.setMaxPoolSize(1); te.initialize(); return te; }
@Bean public ThreadPoolTaskExecutor myThreadPool(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); te.setCorePoolSize(1); te.setMaxPoolSize(1); te.initialize(); return te; }
@Bean public ThreadPoolTaskExecutor myThreadPool(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); te.setCorePoolSize(1); te.setMaxPoolSize(1); te.initialize(); return te; }
실습 코드들은 IntelliJ를 이용해 SpringBoot 2.1.3.RELEASE 버전 기반으로 프로젝트를 생성 후(web, lombok 포함) 진행했습니다.
Thread Pool Hell
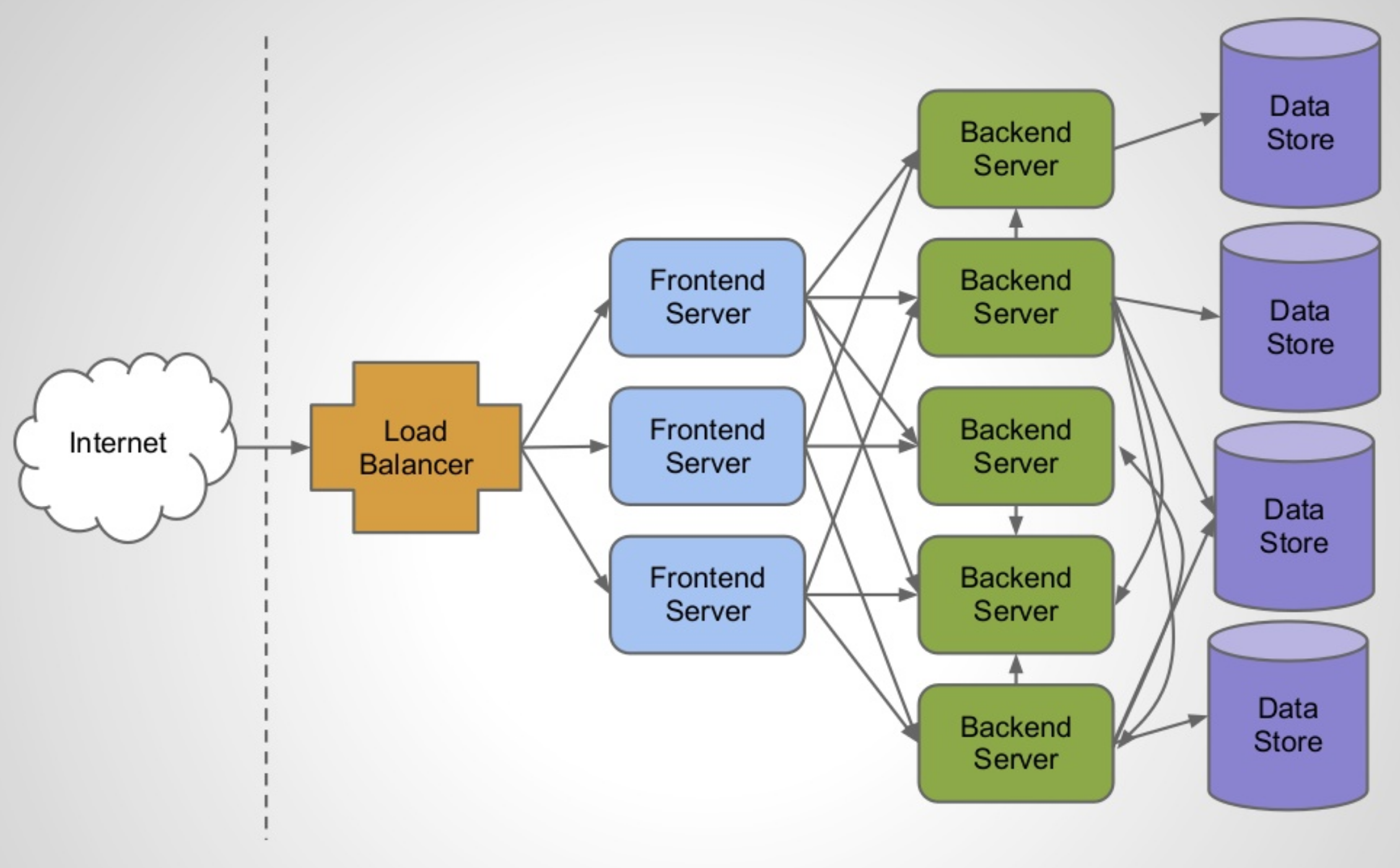
스프링의 비동기 기술 을 이용해 클라이언트로부터 요청을 받은 후 실제 작업은 작업 스레드 풀에 위임하고 현재의 서블릿 스레드는 서블릿 스레드 풀에 반환 후, 다음 요청이 들어올 경우 바로 사용할 수 있게 효율적으로 처리하도록 만들었습니다. 그러나 아직 문제가 있습니다.
아주 빠르게 무언가를 계산하고 해당 처리를 끝내는 경우라면 굳이 비동기 MVC(서블릿)를 사용하지 않아도 문제가 없지만, 하나의 요청에 대한 처리를 수행하면서 외부의 서비스들을 호출하는 작업이 많이 있는 경우, 문제는 단순히 비동기를 서블릿을 사용하는 것만으로 해결할 수 없는 경우가 많이 있습니다. (서블릿 요청은 바로 사용 가능하더라도 워커 스레드가 I/O 같은 작업으로 인해 블록되기 때문입니다.)
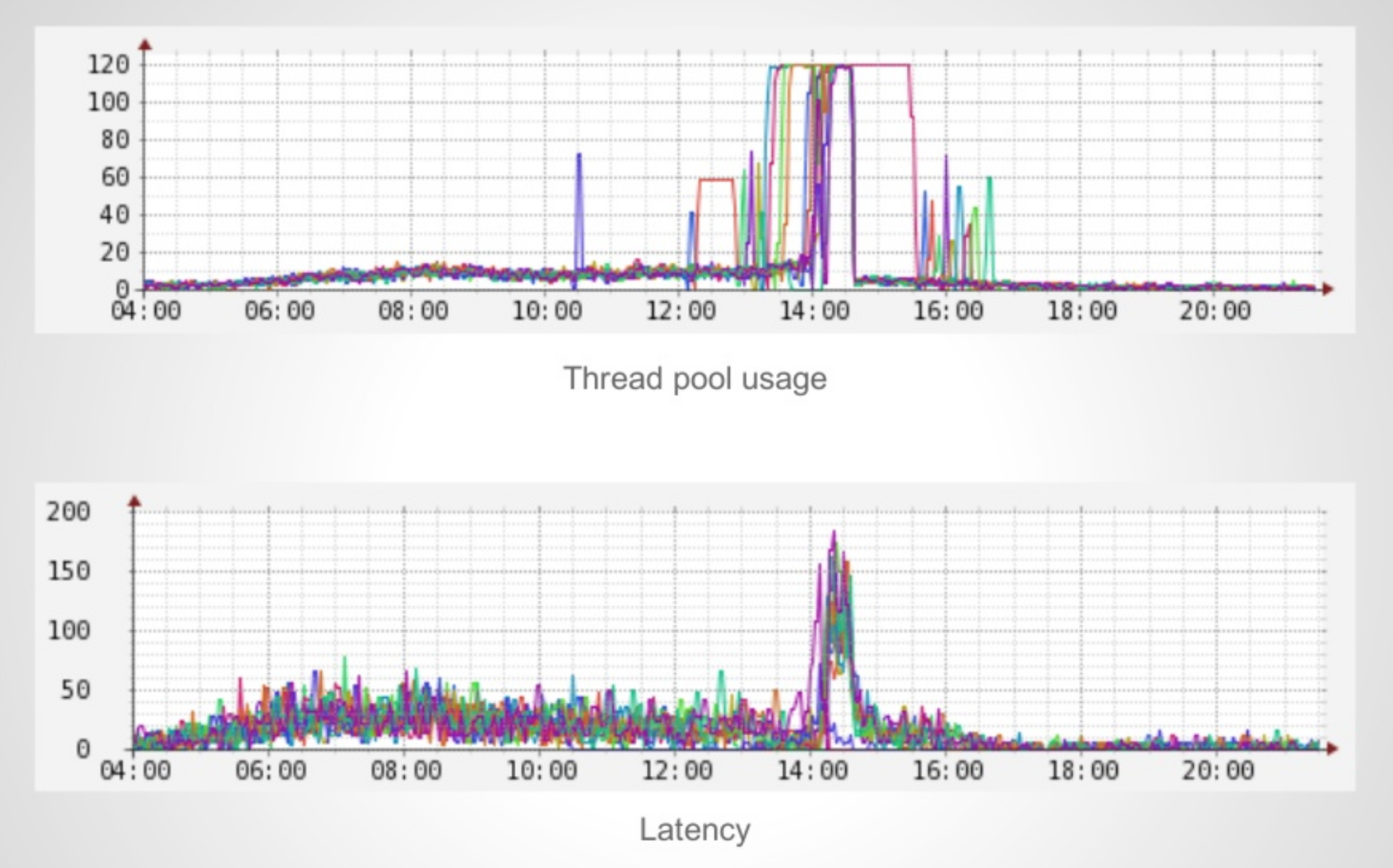
Thread Pool Hell이란 풀 안에 있는 스레드에 대한 사용 요청이 급격하게 증가해 추가적인 요청이 들어올 때, 사용 가능한 스레드 풀의 스레드가 없기 때문에 대기 상태에 빠져 요청에 대한 응답이 느려지게 되는 상태를 말합니다.
최근 서비스들은 아래의 그럼처럼 하나의 요청을 처리함에 있어 다른 서버로의 요청(Network I/O)이 많아졌습니다. 조금전 설명한 것처럼 비동기 서블릿을 사용하더라도 하나의 요청을 처리하는 동안 하나의 작업(워커) 스레드는 그 시간동안 대기상태에 빠지게 되어 결국에는 스레드 풀의 가용성이 떨어지게 됩니다. 이번 포스팅에서는 해당 문제를 해결해가는 과정을 다루고 있습니다.
Upgrade Client (For Load Test)
지난 번에 작성했던 Client를 조금 수정하도록 합니다. 기존의 Client는 100개의 스레드를 순차적으로 만들면서 서버로의 Request를 만들었던 문제가 있었습니다. 이제는 100개의 스레드를 만들고 CyclicBarrier를 이용해 100개의 스레드에서 동시에 Request를 만들도록 변경해보겠습니다.
@Slf4j publicclassLoadTest{ static AtomicInteger counter = new AtomicInteger(0);
publicstaticvoidmain(String[] args)throws InterruptedException, BrokenBarrierException { ExecutorService es = Executors.newFixedThreadPool(100);
RestTemplate rt = new RestTemplate(); String url = "http://localhost:8080/rest?idx={idx}";
CyclicBarrier barrier = new CyclicBarrier(101);
for (int i = 0; i < 100; i++) { // submit이 받는 callable은 return을 가질 수 있으며, exception도 던질 수 있다. es.submit(() -> { int idx = counter.addAndGet(1); log.info("Thread {}", idx); barrier.await();
StopWatch sw = new StopWatch(); sw.start();
String res = rt.getForObject(url, String.class, idx);
// await을 만난 스레드가 101번째가 될 때, 모든 스레드들도 await에서 풀려나 이후 로직을 수행한다. // 메인 스레드 1개, Executors.newFixedThreadPool로 생성한 스레드 100개 barrier.await(); StopWatch main = new StopWatch(); main.start();
es.shutdown(); // 지정된 시간이 타임아웃 걸리기 전이라면 대기작업이 진행될 때까지 기다린다. // (100초안에 작업이 끝날때까지 기다리거나, 100초가 초과되면 종료) es.awaitTermination(100, TimeUnit.SECONDS); main.stop(); log.info("Total: {}", main.getTotalTimeSeconds()); } }
외부 서비스 호출 테스트
클라이언트의 요청을 받아 외부 서비스를 호출하고 해당 결과를 이용해서 응답을 돌려주는 테스트를 진행합니다. 테스트를 진행하기 위해서는 2개의 스프링 애플리케이션이 필요합니다. 2개의 스프링 애플리케이션의 설정은 다음과 같습니다.
application.properties 파일에서 다음과 같이 Tomcat의 스레드 개수를 1개로 설정합니다.
1
server.tomcat.max-threads=1
Remote Application
다른 하나의 스프링 애플리케이션을 생성하고 이전에 만들었던 스프링 애플리케이션의 컨트롤러 내부에서 만들었던 요청을 받아 처리할 수 있도록 컨트롤러 추가합니다. 8080 포트가 아닌 8081 포트를 사용하고 tomcat 스레드를 1000개로 설정합니다. RemoteApplication은 application.properties의 값을 사용하게 하지 않고 직접 프로퍼티를 설정해줍니다.
아래와 같이 설정하면 Intellij를 이용해서 하나의 프로젝트에서 2개의 스프링 애플리케이션을 실행할 수 있습니다.
publicstaticvoidmain(String[] args){ // 하나의 프로젝트에서 2개의 스프링 애플리케이션을 띄우기 위해 외부 서비스 역할을 하는 RemoteApplication은 // application.properties가 아닌 별도의 프로퍼티를 이용하도록 직접 설정한다. System.setProperty("server.port", "8081"); System.setProperty("server.tomcat.max-threads", "1000"); SpringApplication.run(RemoteApplication.class, args); } }
결과 확인
MainApplication과 RemoteApplication을 각각 실행하고 Client를 이용한 테스트 결과는 다음과 같습니다. 100개의 클라이언트 요청을 처리하는데 0.4초 정도의 시간이 걸렸습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
... ... ... 01:54:27.539 [pool-1-thread-40] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 01:54:27.539 [pool-1-thread-40] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 01:54:27.539 [pool-1-thread-40] INFO com.example.study.LoadTest - idx: 40, Elapsed: 0.4 -> res: hello40/service 01:54:27.541 [pool-1-thread-77] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 01:54:27.541 [pool-1-thread-77] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 01:54:27.541 [pool-1-thread-77] INFO com.example.study.LoadTest - idx: 77, Elapsed: 0.401 -> res: hello77/service 01:54:27.543 [pool-1-thread-48] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 01:54:27.543 [pool-1-thread-48] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 01:54:27.543 [pool-1-thread-48] INFO com.example.study.LoadTest - idx: 48, Elapsed: 0.403 -> res: hello48/service 01:54:27.545 [pool-1-thread-8] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 01:54:27.545 [pool-1-thread-8] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 01:54:27.546 [pool-1-thread-8] INFO com.example.study.LoadTest - idx: 8, Elapsed: 0.407 -> res: hello8/service 01:54:27.548 [pool-1-thread-33] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 01:54:27.548 [pool-1-thread-33] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 01:54:27.548 [pool-1-thread-33] INFO com.example.study.LoadTest - idx: 33, Elapsed: 0.409 -> res: hello33/service 01:54:27.548 [main] INFO com.example.study.LoadTest - Total: 0.407
이번에는 RemoteApplication의 요청 처리 부분에 2초간 Thread sleep을 주고 다시 한 번 클라이언트를 이용해 테스트를 진행해봅니다.
Thread sleep을 추가하고 다시 테스트를 해보면 결과는 다음과 같습니다. 100개의 요청을 약 0.4초만에 모두 처리하던 이전과 달리 매 요청을 처리하는데 약 2초의 시간이 증가하고 있습니다. 결국 마지막 요청은 약 2 * 100 = 200초 후에서야 응답을 받을 수 있기 때문에 모든 요청에 대한 처리는 200초 정도 걸릴 것 입니다.
02:25:22.056 [pool-1-thread-32] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:22.058 [pool-1-thread-32] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:22.061 [pool-1-thread-32] INFO com.example.study.LoadTest - idx: 32, Elapsed: 2.233 -> res: hello32/service 02:25:24.060 [pool-1-thread-56] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:24.060 [pool-1-thread-56] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:24.060 [pool-1-thread-56] INFO com.example.study.LoadTest - idx: 56, Elapsed: 4.231 -> res: hello56/service 02:25:26.068 [pool-1-thread-93] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:26.068 [pool-1-thread-93] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:26.068 [pool-1-thread-93] INFO com.example.study.LoadTest - idx: 93, Elapsed: 6.238 -> res: hello93/service 02:25:28.077 [pool-1-thread-31] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:28.077 [pool-1-thread-31] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:28.077 [pool-1-thread-31] INFO com.example.study.LoadTest - idx: 31, Elapsed: 8.249 -> res: hello31/service 02:25:30.081 [pool-1-thread-20] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:30.082 [pool-1-thread-20] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:30.082 [pool-1-thread-20] INFO com.example.study.LoadTest - idx: 20, Elapsed: 10.254 -> res: hello20/service 02:25:32.089 [pool-1-thread-46] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 02:25:32.089 [pool-1-thread-46] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 02:25:32.089 [pool-1-thread-46] INFO com.example.study.LoadTest - idx: 46, Elapsed: 12.26 -> res: hello46/service ... ... ...
이런 결과가 나오게 된 이유는 클라이언트로부터의 요청을 받아 처리하는 Main Application의 tomcat thread가 1개이고, 1개의 서블릿 스레드를 이용해 클라이언트의 요청을 처리하는 과정에서 Remote Application에 대한 요청(Network I/O)에서 응답을 받기까지 약 2초간 스레드가 block되기 때문입니다.
AsyncRestTemplate
위의 문제는 MainApplication의 tomcat 스레드는 클라이언트의 요청을 처리하며 외부 서비스(RemoteApplication)로 요청(Network I/O)을 보낸 후, 응답이 올 때까지 대기하고 있는 상태라는 점입니다. 해당 시간동안 CPU는 아무 일을 처리하지 않기때문에 자원이 소모되고 있습니다.
이 문제를 해결하기 위해서는 API를 호출하는 작업을 비동기적으로 바꿔야합니다. tomcat 스레드는 요청에 대한 작업을 다 끝내기 전에 반환을 해서 바로 다음 요청을 처리하도록 사용합니다. 그리고 외부 서비스로부터 실제 결과를 받고 클라이언트의 요청에 응답을 보내기 위해서는 새로운 스레드를 할당 받아 사용합니다. (외부 서비스로부터 실제 결과를 받고 클라이언트에 응답을 보내기 위해서는 새로운 스레드를 할당 받아야 하지만, 외부 API를 호출하는 동안은 스레드(tomcat) 자원을 낭비하고 싶지 않다는 것이 목적이다.)
스프링 3.x 버전에서는 이 문제를 간단히 해결하기 어려웠지만 스프링 4 부터 제공하는 AsyncRestTemplate을 사용하면 이 문제를 쉽게 해결할 수 있습니다. AsyncRestTemplate은 비동기 클라이언트를 제공하는 클래스이며 ListenableFuture를 반환합니다. 스프링은 컨트롤러에서 ListenableFuture를 리턴하면 해당 스레드는 즉시 반납하고, 스프링 MVC가 자동으로 등록해준 콜백에 의해 결과가 처리됩니다.
... ... ... 16:55:49.088 [pool-1-thread-4] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.089 [pool-1-thread-4] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.089 [pool-1-thread-4] INFO com.example.study.LoadTest - idx: 4, Elapsed: 2.658 -> res: hello4/service 16:55:49.090 [pool-1-thread-44] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.090 [pool-1-thread-44] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.090 [pool-1-thread-44] INFO com.example.study.LoadTest - idx: 44, Elapsed: 2.659 -> res: hello44/service 16:55:49.091 [pool-1-thread-93] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.091 [pool-1-thread-93] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.091 [pool-1-thread-93] INFO com.example.study.LoadTest - idx: 93, Elapsed: 2.658 -> res: hello93/service 16:55:49.095 [pool-1-thread-66] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.096 [pool-1-thread-66] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.096 [pool-1-thread-66] INFO com.example.study.LoadTest - idx: 66, Elapsed: 2.664 -> res: hello66/service 16:55:49.098 [pool-1-thread-16] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.098 [pool-1-thread-16] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.098 [pool-1-thread-16] INFO com.example.study.LoadTest - idx: 16, Elapsed: 2.667 -> res: hello16/service 16:55:49.101 [pool-1-thread-57] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.101 [pool-1-thread-57] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.101 [pool-1-thread-57] INFO com.example.study.LoadTest - idx: 57, Elapsed: 2.669 -> res: hello57/service 16:55:49.104 [pool-1-thread-2] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.104 [pool-1-thread-2] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.105 [pool-1-thread-2] INFO com.example.study.LoadTest - idx: 2, Elapsed: 2.674 -> res: hello2/service 16:55:49.105 [pool-1-thread-15] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 16:55:49.105 [pool-1-thread-15] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 16:55:49.105 [pool-1-thread-15] INFO com.example.study.LoadTest - idx: 15, Elapsed: 2.674 -> res: hello15/service 16:55:49.106 [main] INFO com.example.study.LoadTest - Total: 2.673
클라이언트의 요청이 들어 올 때, MainApplication의 스레드 상태를 살펴보면, tomcat 스레드는 그대로 1개 입니다.(http-nio-8080-exec-1) 그러나 비동기 작업을 처리하기 위해서 순간적으로 백그라운드에 100개의 스레드 새로 생성되는것을 확인할 수 있습니다.
Netty non-blocking I/O
지금까지 Tomcat의 스레드가 1개이지만 요청을 비동기적으로 처리함으로써 Tomcat의 스레드는 바로 반환이되어 다시 그 후의 요청에 Tomcat의 스레드를 이용해 요청을 받을 수 있었습니다. 그러나 결과적으로는 실제 비동기 요청을 처리하는 스레드는 요청의 수 만큼 계속 생성되는 것을 확인할 수 있었습니다.
이번에는 이렇게 비동기 요청을 처리하는 스레드의 수도 Netty의 non blocking I/O를 이용함으로써 비동기 요청을 처리하는 스레드도 줄여보고자 합니다. 그러면 결과적으로 tomcat의 스레드 1개, netty의 non blocking I/O를 이용하기위한 필요한 스레드의 수만큼만 생성되어 클라이언트의 요청을 모두 처리할 수 있을 것 입니다.
먼저 netty의 dependency를 build.gradle 혹은 pom.xml에 추가합니다. 저는 build.gradle에 의존성을 추가해 주었습니다.
... ... ... 18:24:49.958 [pool-1-thread-65] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.958 [pool-1-thread-65] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.958 [pool-1-thread-65] INFO com.example.study.LoadTest - idx: 65, Elapsed: 2.744 -> res: hello65/service 18:24:49.964 [pool-1-thread-59] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.964 [pool-1-thread-59] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.964 [pool-1-thread-59] INFO com.example.study.LoadTest - idx: 59, Elapsed: 2.751 -> res: hello59/service 18:24:49.964 [pool-1-thread-14] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.965 [pool-1-thread-14] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.965 [pool-1-thread-14] INFO com.example.study.LoadTest - idx: 14, Elapsed: 2.752 -> res: hello14/service 18:24:49.968 [pool-1-thread-31] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.968 [pool-1-thread-31] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.968 [pool-1-thread-31] INFO com.example.study.LoadTest - idx: 31, Elapsed: 2.754 -> res: hello31/service 18:24:49.969 [pool-1-thread-63] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.969 [pool-1-thread-63] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.969 [pool-1-thread-63] INFO com.example.study.LoadTest - idx: 63, Elapsed: 2.755 -> res: hello63/service 18:24:49.969 [pool-1-thread-19] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.969 [pool-1-thread-19] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.969 [pool-1-thread-19] INFO com.example.study.LoadTest - idx: 19, Elapsed: 2.755 -> res: hello19/service 18:24:49.970 [pool-1-thread-62] DEBUG org.springframework.web.client.RestTemplate - Response 200 OK 18:24:49.970 [pool-1-thread-62] DEBUG org.springframework.web.client.RestTemplate - Reading to [java.lang.String] as "text/plain;charset=UTF-8" 18:24:49.970 [pool-1-thread-62] INFO com.example.study.LoadTest - idx: 62, Elapsed: 2.756 -> res: hello62/service 18:24:49.970 [main] INFO com.example.study.LoadTest - Total: 2.755
스레드를 확인해보면 다음과 같이 tomcat 스레드 1개, netty가 non blocking I/O를 사용하는데 필요로 하는 몇개의 스레드가 추가된 것 말고는 스레드 수가 크게 증가하지 않은것을 확인할 수 있습니다.
DeferredResult
이전 포스팅에서 살펴 보았던 DeferredResult를 사용하면 AsyncRestTemplate을 사용하여 외부 서비스를 호출한 후, 그 결과를 다시 이용해 클라이언트의 요청에 응답하는 추가 로직 부분을 작성할 수 있습니다.
컨트롤러에서 DeferredResult 오브젝트를 반환하는 시점에는 바로 응답이 가지 않고, 추후 해당 DeferredResult 오브젝트에 값을 set(setResult, setErrorResult) 해줄 때, 클라이언트에게 응답이 가게 됩니다. 이를 이용하려면 ListenableFuture에 콜백을 추가해 해당 콜백 로직 안에서 결과를 이용해 DeferredResult 오브젝트의 set 메서드를 호출하면 됩니다.
@GetMapping("/rest") public DeferredResult<String> rest(int idx){ // 오브젝트를 만들어서 컨트롤러에서 리턴하면 언제가 될지 모르지만 언제인가 DeferredResult에 값을 써주면 // 그 값을 응답으로 사용 DeferredResult<String> dr = new DeferredResult<>();
ListenableFuture<ResponseEntity<String>> f1 = rt.getForEntity("http://localhost:8081/service?req={req}", String.class, "hello" + idx); f1.addCallback(s -> { dr.setResult(s.getBody() + "/work"); }, e -> { dr.setErrorResult(e.getMessage()); });
publicstaticvoidmain(String[] args){ // 하나의 프로젝트에서 2개의 스프링 애플리케이션을 띄우기 위해 외부 서비스 역할을 하는 RemoteApplication은 // application.properties가 아닌 별도의 프로퍼티를 이용하도록 직접 설정한다. System.setProperty("server.port", "8081"); System.setProperty("server.tomcat.max-threads", "1000"); SpringApplication.run(RemoteApplication.class, args); } }
@GetMapping("/rest") public DeferredResult<String> rest(int idx){ // 오브젝트를 만들어서 컨트롤러에서 리턴하면 언제가 될지 모르지만 언제인가 DeferredResult에 값을 써주면 // 그 값을 응답으로 사용 DeferredResult<String> dr = new DeferredResult<>();
// 결과 20:35:53.892 [main] INFO com.example.study.FutureEx - Exit 20:35:55.888 [pool-1-thread-1] INFO com.example.study.FutureEx - Async
Future
Future는 자바 1.5에서 등장한 비동기 계산의 결과를 나타내는 Interface 입니다.
비동기적인 작업을 수행한다는 것은 현재 진행하고 있는 스레드가 아닌 별도의 스레드에서 작업을 수행하는 것을 말합니다. 같은 스레드에서 메서드를 호출할 때는 결과를 리턴 값을 받지만, 비동기적으로 작업을 수행할 때는 결과값을 전달받을 수 있는 무언가의 interface가 필요한데 Future가 그 역할을 합니다.
비동기 작업에서 결과를 반환하고 싶을 때는 runnable대신 callable interface를 이용하면 결과 값을 return 할 수 있습니다. 또한 예외가 발생했을 때 해당 예외를 비동기 코드를 처리하는 스레드 안에서 처리하지 않고 밖으로 던질 수 있습니다.
Future<String> f = es.submit(() -> { Thread.sleep(2000); log.info("Async"); return"Hello"; });
log.info(f.get()); log.info("Exit"); } }
// 결과 20:43:11.704 [pool-1-thread-1] INFO com.example.study.FutureEx - Async 20:43:11.706 [main] INFO com.example.study.FutureEx - Hello 20:43:11.706 [main] INFO com.example.study.FutureEx - Exit
Future를 통해서 비동기 결과의 값을 가져올 때는 get 메서드를 사용합니다. 그러나 get 메서드를 호출하게 되면 비동기 작업이 완료될 때까지 해당 스레드가 blocking됩니다.
Future는 비동기적인 연산 혹은 작업을 수행하고 그 결과를 갖고 있으며, 완료를 기다리고 계산 결과를 반환(get)하는 메소드와 그 외에도 해당 연산이 완료되었는지 확인하는(isDone) 메소드를 제공합니다.
// 결과 00:28:39.459 [main] INFO com.example.study.FutureEx - false 00:28:41.461 [pool-1-thread-1] INFO com.example.study.FutureEx - Async 00:28:41.467 [main] INFO com.example.study.FutureEx - Exit 00:28:41.467 [main] INFO com.example.study.FutureEx - true 00:28:41.467 [main] INFO com.example.study.FutureEx - Hello
비동기 작업의 결과를 가져오는 방법은 Future와 같은 결과를 다루는 handler를 이용하거나 callback을 이용하는 2가지 방법이 있습니다. 아래의 예시 코드는 FutureTask의 비동기 작업이 완료될 경우 호출되는 done() 메서드를 재정의하여 callback을 이용하는 방법입니다.
// 결과 01:03:04.153 [main] INFO com.example.study.FutureEx - EXIT 01:03:06.153 [pool-1-thread-1] INFO com.example.study.FutureEx - Async 01:03:06.153 [pool-1-thread-1] INFO com.example.study.FutureEx - Hello
위 예시 코드의 callback 관련 부분을 FutureTask를 상속받아 done() 메서드를 재정의함으로써, 비동기 코드와 그 결과를 갖고 작업을 수행하는 callback을 좀 더 가독성이 좋게 작성할 수 있습니다.
publicstaticvoidmain(String[] args){ ExecutorService es = Executors.newCachedThreadPool();
CallbackFutureTask f = new CallbackFutureTask(() -> { Thread.sleep(2000); log.info("Async"); return"Hello"; }, log::info);
es.execute(f); es.shutdown(); } }
// 결과 01:05:01.978 [main] INFO com.example.study.FutureEx - EXIT 01:05:03.977 [pool-1-thread-1] INFO com.example.study.FutureEx - Async 01:05:03.978 [pool-1-thread-1] INFO com.example.study.FutureEx - Hello
위 예시 코드에 SuccessCallback을 추가한 것처럼 ExceptionCallback을 추가하여 비동기 코드에서 예외가 발생할 경우, 해당 예외를 처리하는 callback도 추가할 수 있습니다.
@Override protectedvoiddone(){ super.done(); try { this.sc.onSuccess(get()); /* InterruptedException은 예외긴 예외이지만, 현재 작업을 수행하지 말고 중단해라 라고 메시지를 보내는 용도이다. 따라서 현재 스레드에 interrupt를 체크하고 종료한다. */ } catch (InterruptedException e) { Thread.currentThread().interrupt(); } catch (ExecutionException e) { // 래핑된 에러를 빼내어 전달한다. ec.onError(e.getCause()); } } }
publicstaticvoidmain(String[] args){ ExecutorService es = Executors.newCachedThreadPool();
CallbackFutureTask f = new CallbackFutureTask(() -> { Thread.sleep(2000); if (1 == 1) thrownew RuntimeException("Async ERROR!!!"); log.info("Async"); return"Hello"; }, s -> log.info("Result: {}", s), e -> log.info("Error: {}", e.getMessage()));
es.execute(f); es.shutdown();
log.info("EXIT"); } }
// 결과 01:11:53.460 [main] INFO com.example.study.FutureEx - EXIT 01:11:55.463 [pool-1-thread-1] INFO com.example.study.FutureEx - Error: Async ERROR!!!
스프링의 비동기 기술
@Async
Spring MVC 3.2 부터 Servlet 3.0 기반의 비동기 요청 처리가 가능해졌습니다. @Async 어노테이션을 추가해 해당 메서드를 비동기적으로 호출할 수 있습니다. 해당 메서드를 호출한 호출자(caller)는 즉시 리턴하고 메소드의 실제 실행은 Spring TaskExecutor에 의해서 실행됩니다. 비동기로 실행되는 메서드는 Future 형식의 값을 리턴하고, 호출자는 해당 Future의 get() 메서드를 호출하기 전에 다른 작업을 수행할 수 있습니다.
@Service publicstaticclassMyService{ /* 내부적으로 AOP를 이용해 복잡한 로직이 실행된다. 비동기 작업은 return값으로 바로 결과를 줄 수 없다. (Future 혹은 Callback을 이용해야 한다.) */ @Async public Future<String> hello()throws InterruptedException { log.info("hello()"); Thread.sleep(1000); returnnew AsyncResult<>("Hello"); } }
publicstaticvoidmain(String[] args){ // try with resource 블록을 이용해 빈이 다 준비된 후 종료되도록 설정 try (ConfigurableApplicationContext c = SpringApplication.run(StudyApplication.class, args)) { } }
@Autowired MyService myService;
// 모든 빈이 다 준비된 후 실행됨 (현재는 일종의 컨트롤러라고 생각) @Bean ApplicationRunner run(){ return args -> { log.info("run()"); Future<String> res = myService.hello(); log.info("exit: {}", res.isDone()); log.info("result: {}", res.get()); }; } }
// 결과 2019-04-0423:29:31.960 INFO 41618 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-04-0423:29:31.960 INFO 41618 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 928 ms 2019-04-0423:29:32.161 INFO 41618 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-04-0423:29:32.337 INFO 41618 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-04-04 23:29:32.341 INFO 41618 --- [ main] com.example.study.StudyApplication : Started StudyApplication in 1.631 seconds(JVM running for2.101) 2019-04-04 23:29:32.343 INFO 41618 --- [ main] com.example.study.StudyApplication : run() 2019-04-04 23:29:32.346 INFO 41618 --- [ main] com.example.study.StudyApplication : exit: false 2019-04-04 23:29:32.350 INFO 41618 --- [ task-1] com.example.study.StudyApplication : hello() 2019-04-04 23:29:33.351 INFO 41618 --- [ main] com.example.study.StudyApplication : result: Hello 2019-04-04 23:29:33.354 INFO 41618 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'
ListenableFuture
스프링 4.0 부터 제공하는 Future 인터페이스를 확장한 ListenableFuture를 이용하면 비동기 처리의 결과 값을 사용할 수 있는 callback을 추가할 수 있습니다. @Async 어노테이션을 사용하는 메서드에서 스프링 4.1 부터 제공하는 ListenableFuture 인터페이스를 구현한 AsyncResult를 반환하면 됩니다.
publicstaticvoidmain(String[] args){ // try with resource 블록을 이용해 빈이 다 준비된 후 종료되도록 설정 try (ConfigurableApplicationContext c = SpringApplication.run(StudyApplication.class, args)) { } }
// 결과 2019-04-0423:42:46.348 INFO 44559 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-04-0423:42:46.348 INFO 44559 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 959 ms 2019-04-0423:42:46.557 INFO 44559 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-04-0423:42:46.736 INFO 44559 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-04-04 23:42:46.740 INFO 44559 --- [ main] com.example.study.StudyApplication : Started StudyApplication in 1.779 seconds(JVM running for2.306) 2019-04-04 23:42:46.742 INFO 44559 --- [ main] com.example.study.StudyApplication : run() 2019-04-04 23:42:46.748 INFO 44559 --- [ main] com.example.study.StudyApplication : exit 2019-04-04 23:42:46.751 INFO 44559 --- [ task-1] com.example.study.StudyApplication : hello() 2019-04-04 23:42:47.752 INFO 44559 --- [ task-1] com.example.study.StudyApplication : Hello 2019-04-04 23:42:48.757 INFO 44559 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'
ThreadPoolTaskExecutor
@Async 어노테이션을 사용해 해당 메서드를 비동기적으로 호출할 경우 ThreadPool을 명시적으로 선언하지 않으면, 기본적으로 SimpleAsyncTaskExecutor를 사용합니다. SimpleAsyncTaskExecutor는 각 비동기 호출마다 계속 새로운 스레드를 만들어 사용하기 때문에 비효율적입니다. 이 경우 ThreadPoolTaskExecutor를 직접 만들어 사용하는게 효율적입니다.
ThreadPoolTaskExecutor는 CorePool, QueueCapacity, MaxPoolSize를 직접 설정할 수 있습니다. 각 값에 대한 설명은 코드에 추가했습니다.
@Service publicstaticclassMyService{ /* 기본적으로 SimpleAsyncTaskExecutor를 사용한다. 스레드를 계속 새로 만들어 사용하기 때문에 비효율적이다. */ @Async // @Async("tp") ThreadPool이 여러개일 경우 직접 지정 가능하다. public ListenableFuture<String> hello()throws InterruptedException { log.info("hello()"); Thread.sleep(1000); returnnew AsyncResult<>("Hello"); } }
@Bean ThreadPoolTaskExecutor tp(){ ThreadPoolTaskExecutor te = new ThreadPoolTaskExecutor(); // 1) 스레드 풀을 해당 개수까지 기본적으로 생성함. 처음 요청이 들어올 때 poll size만큼 생성한다. te.setCorePoolSize(10); // 2) 지금 당장은 Core 스레드를 모두 사용중일때, 큐에 만들어 대기시킨다. te.setQueueCapacity(50); // 3) 대기하는 작업이 큐에 꽉 찰 경우, 풀을 해당 개수까지 더 생성한다. te.setMaxPoolSize(100); te.setThreadNamePrefix("myThread"); return te; }
publicstaticvoidmain(String[] args){ // try with resource 블록을 이용해 빈이 다 준비된 후 종료되도록 설정 try (ConfigurableApplicationContext c = SpringApplication.run(StudyApplication.class, args)) { } }
@Autowired MyService myService;
// 모든 빈이 다 준비된 후 실행됨 (현재는 일종의 컨트롤러라고 생각) @Bean ApplicationRunner run(){ return args -> { log.info("run()"); ListenableFuture<String> f = myService.hello(); f.addCallback(s -> log.info(s), e-> log.info(e.getMessage())); log.info("exit");
Thread.sleep(2000); }; } }
// 결과 2019-04-0500:03:11.304 INFO 47863 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-04-0500:03:11.304 INFO 47863 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1061 ms 2019-04-0500:03:11.367 INFO 47863 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'tp' 2019-04-0500:03:11.677 INFO 47863 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-04-05 00:03:11.680 INFO 47863 --- [ main] com.example.study.StudyApplication : Started StudyApplication in 1.751 seconds(JVM running for2.208) 2019-04-05 00:03:11.681 INFO 47863 --- [ main] com.example.study.StudyApplication : run() 2019-04-05 00:03:11.686 INFO 47863 --- [ main] com.example.study.StudyApplication : exit 2019-04-05 00:03:11.687 INFO 47863 --- [ myThread1] com.example.study.StudyApplication : hello() 2019-04-05 00:03:12.691 INFO 47863 --- [ myThread1] com.example.study.StudyApplication : Hello
Servlet Async
@Async 어노테이션을 설명할 때 말했던 것처럼, Spring MVC 3.2 부터 Servlet 3.0 기반의 비동기 요청 처리가 가능해졌습니다. 기존 Controller 메서드를 Callable로 변경함으로써 비동기로 만들 수 있습니다. Controller 메서드를 비동기로 변경해도 해당 처리가 서블릿 스레드가 아닌 다른 스레드에서 발생한다는 점을 제외하면 기존 Controller 메서드의 동작 방식과는 큰 차이가 없습니다. (참고 : Spring MVC 3.2 Preview: Making a Controller Method Asynchronous)
Servlet 3.0 & 3.1
Servlet 3.0: 비동기 서블릿
HTTP connection은 이미 논블록킹 IO
서블릿 요청 읽기, 응답 쓰기는 블록킹
비동기 작업 시작 즉시 서블릿 스레드 반납
비동기 작업이 완료되면 서블릿 스레드 재할당
비동기 서블릿 컨텍스트 이용 (AsyncContext)
Servlet 3.1: 논블록킹 IO
논블록킹 서블릿 요청, 응답 처리
Callback
스레드가 블록되는 상황은 CPU와 메모리 자원을 많이 소모합니다. 컨텍스트 스위칭이 일어나기 때문입니다. 기본적으로 스레드가 블로킹되면 wating 상태로 변경되면서 컨텍스트 스위칭이 일어나고 추후 I/O 작업이 끝나 running 상태로 변경되면서 다시 컨텍스트 스위칭이 일어나 총 2번의 컨텍스트 스위칭이 일어납니다. Java InputStream과 OutputStream은 블록킹 방식이다. RequestHttpServletRequest, RequestHttpServletResponse는 InputSream과 OutputStream을 사용하기 때문에 서블릿은 기본적으로 블로킹 IO 방식이다.
// 결과 2019-04-0601:12:41.761 INFO 69216 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-04-0601:12:41.762 INFO 69216 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1206 ms 2019-04-0601:12:41.993 INFO 69216 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-04-0601:12:42.182 INFO 69216 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-04-06 01:12:42.186 INFO 69216 --- [ main] com.example.study.StudyApplication : Started StudyApplication in 2.073 seconds(JVM running for2.807) 2019-04-06 01:12:44.161 INFO 69216 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2019-04-06 01:12:44.162 INFO 69216 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2019-04-06 01:12:44.169 INFO 69216 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 7 ms 2019-04-06 01:12:44.190 INFO 69216 --- [nio-8080-exec-1] com.example.study.StudyApplication : callable 2019-04-06 01:12:44.198 INFO 69216 --- [ task-1] com.example.study.StudyApplication : async
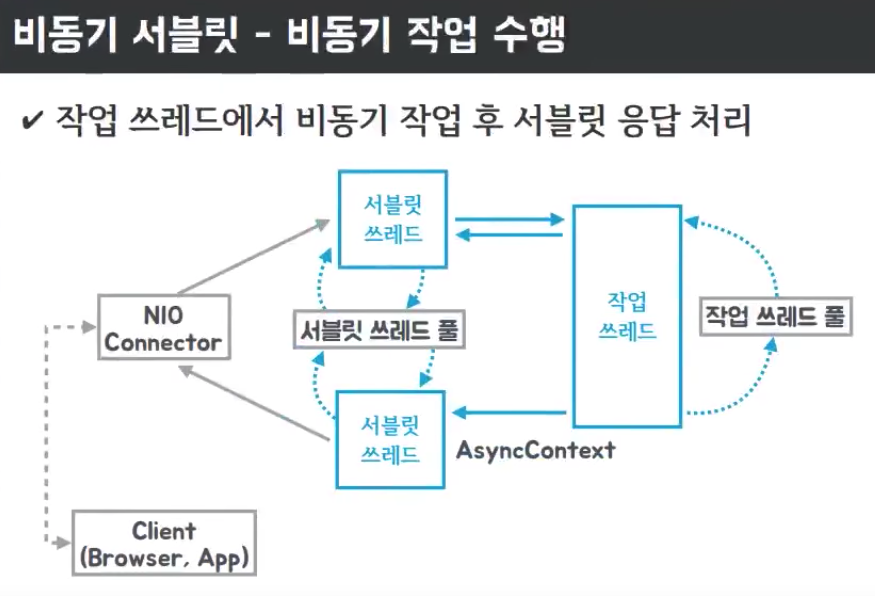
실제로 비동기 서블릿은 아래의 그림처럼 동작합니다.
Client (For Load Test)
지금부터는 Spring에서 Sync Servlet을 이용할 때와 Async Servlet을 이용했을 때의 차이점을 알아보기 위해 테스트를 할 수 있도록, 먼저 여러 Request를 동시에 생성하는 Client를 작성해봅니다. Spring에서 제공하는 RestTemplate을 이용해 100개의 Request를 동시에 호출합니다.
es.shutdown(); // 지정된 시간이 타임아웃 걸리기 전이라면 대기작업이 진행될 때까지 기다린다. // (100초안에 작업이 끝날때까지 기다리거나, 100초가 초과되면 종료) es.awaitTermination(100, TimeUnit.SECONDS); main.stop(); log.info("Total: {}", main.getTotalTimeSeconds()); } }
Change Tomcat Thread Count
위의 비동기 서블릿 그림에서 볼 수 있듯이, Async Servlet은 클라이언트로부터 요청을 받은 후 실제 작업은 작업 스레드 풀에 위임하고 현재의 서블릿 스레드는 서블릿 스레드 풀에 반환 후, 다음 요청이 들어올 경우 사용할 수 있도록 합니다. 이에 반해, Sync Servlet은 요청을 받은 서블릿 스레드에서 실제 작업까지 전부 진행하기 때문에 요청에 대한 응답을 반환하기 전까지는 새로운 요청을 처리할 수 없는 상태입니다.
실제 이처럼 동작하는지 확인하기 위해서 application.properties 파일에서 다음과 같이 Tomcat의 스레드 개수를 1개로 설정합니다.
1
server.tomcat.max-threads=1
Sync vs Async
Sync
먼저 아래와 같이 Sync Servlet을 이용해 서버를 띄운 후 위의 Client 코드를 이용해 테스트를 진행합니다.
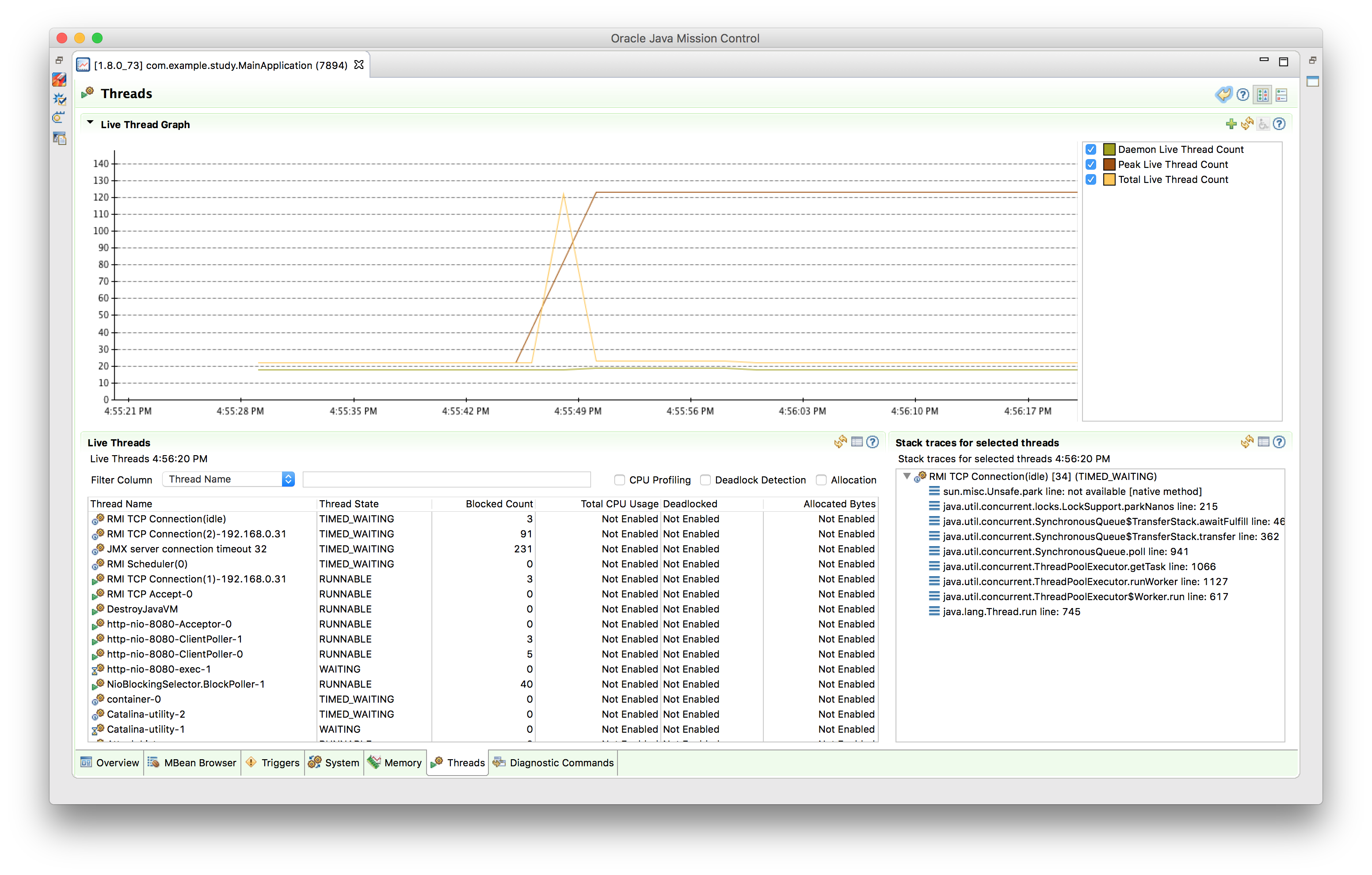
해당 서버를 띄우고 Client(LoadTest) 코드를 사용해 테스트를 진행하면 결과는 다음과 같습니다. Tomcat의 스레드가 하나이며 Sync 방식으로 동작하기 때문에 한 번에 하나의 클라이언트 요청만 처리할 수 있습니다. 서버 로그를 확인하면 nio-8080-exec-1 라는 이름을 가진 한개의 스레드가 요청을 처리하고 있습니다.
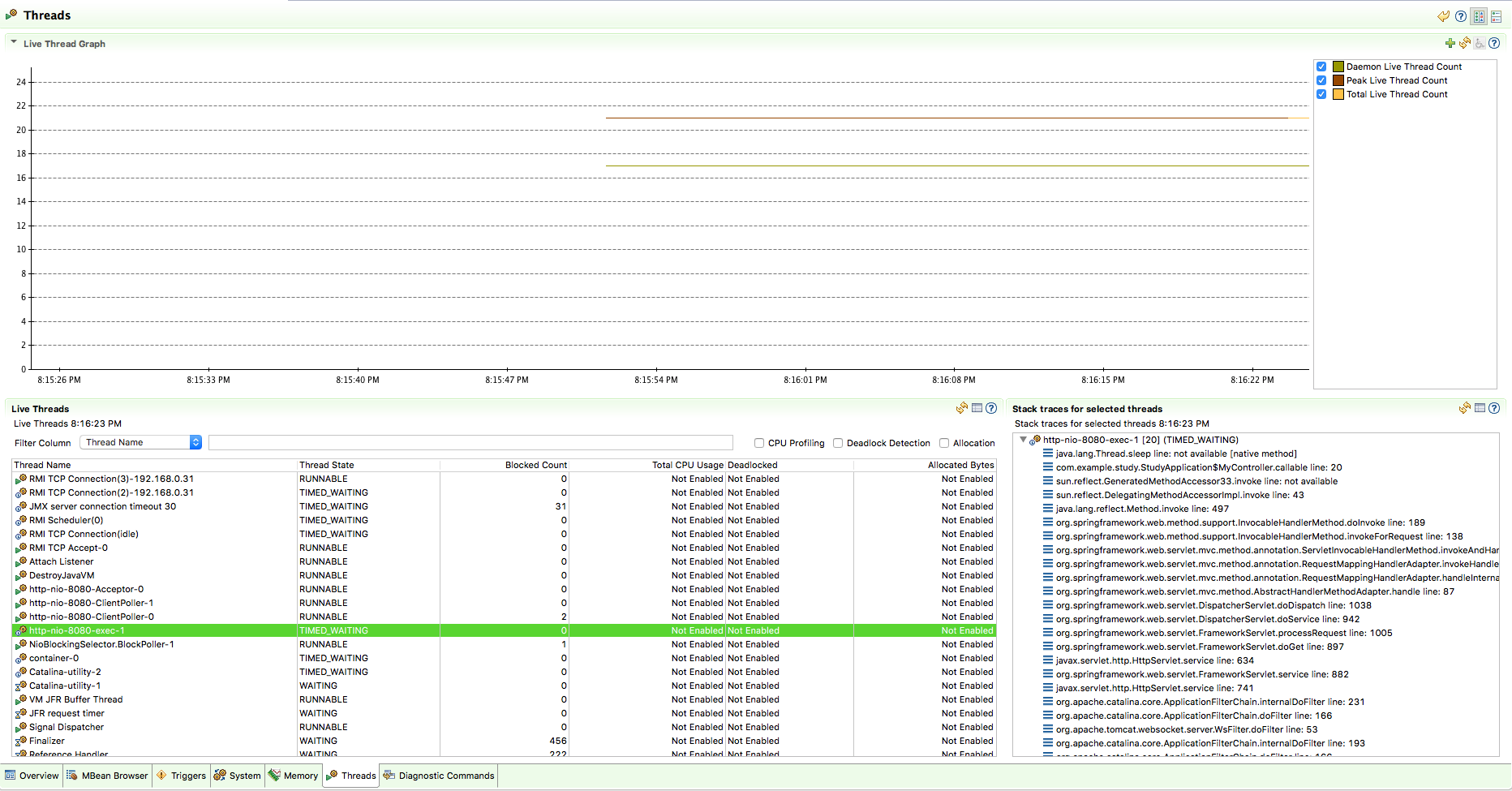
이번에는 JMC(Java Mission Control)를 이용해 실제 서버의 스레드 상황을 살펴보겠습니다.
JMC를 이용해 클라이언트 요청이 들어올 때, Thread 상태를 보면 다음과 같습니다. 동시에 100개의 클라이언트 요청이 들어왔지만, 스레드 수는 그대로 유지되고 있으며, 여러 스레드 목록 중에 nio-8080-exec-1 스레드가 존재하고 있는것을 확인할 수 있습니다.
Async
이번에는 서버 코드를 아래와 같이 Async Servlet을 이용하도록 수정한 후 서버를 띄워 Client 코드를 이용해 테스트를 진행합니다. (작업 스레드 풀은 WebMvcConfigurer를 통해 설정해줍니다.)
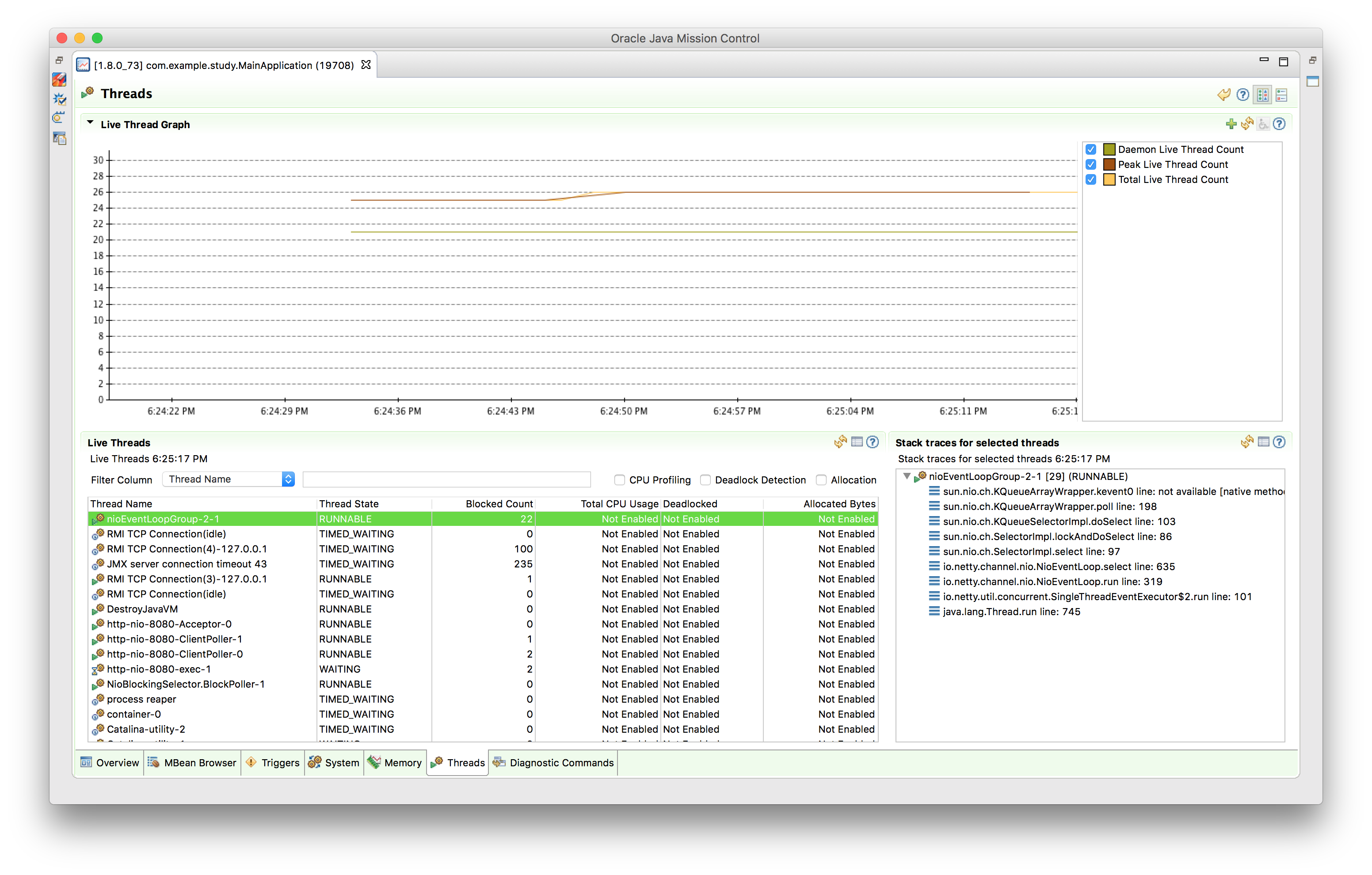
Client(LoadTest) 코드를 사용해 테스트를 진행하면 결과는 다음과 같습니다. Tomcat의 스레드가 하나이지만 Async 방식으로 동작하기 때문에 해당 요청에 대한 실제 처리는 워커 스레드 풀에서 사용되고 있지 않은 스레드를 이용해 처리합니다. 서버 로그를 확인하면 nio-8080-exec-1 라는 이름을 가진 한개의 Tomcat 스레드와 workThreadX라는 이름을 가진 100개의 워커 스레드를 확인할 수 있습니다.
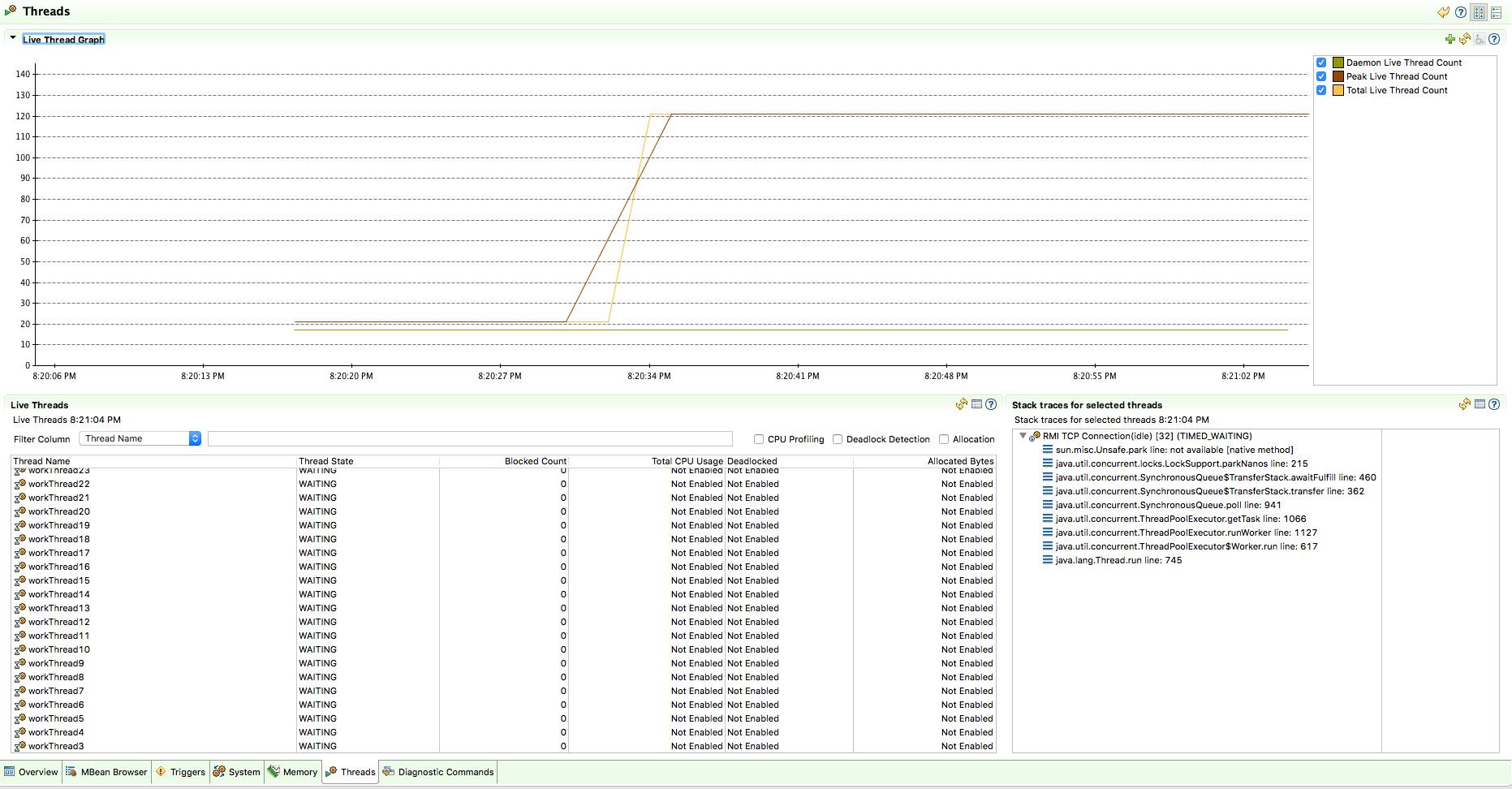
이번에도 역시 JMC(Java Mission Control)를 이용해 실제 서버의 스레드 상황을 살펴보겠습니다.
nio-8080-exec-1 라는 이름을 가진 한개의 Tomcat 스레드와 workThreadX라는 이름을 가진 100개의 워커 스레드를 확인할 수 있습니다.
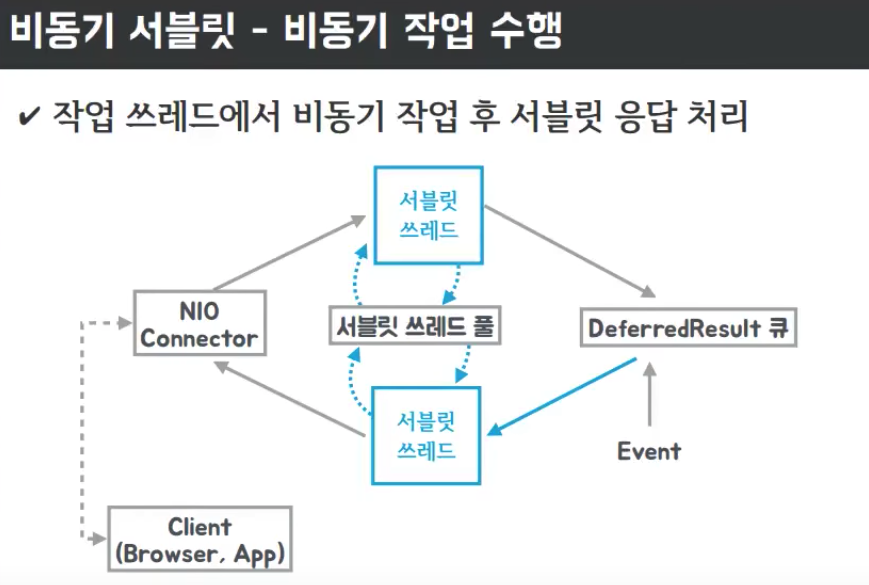
DeferredResult
DeferredResult는 Spring 3.2 부터 사용 가능합니다. 비동기 요청 처리를 위해 사용하는 Callable의 대안을 제공합니다. “지연된 결과”를 의미하며 외부의 이벤트 혹은 클라이언트 요청에 의해서 지연되어 있는 HTTP 요청에 대한 응답을 나중에 써줄 수 있는 기술입니다. 별도로 워커 스레드를 만들어 대기하지 않고도 처리가 가능합니다.
@RestController publicstaticclassMyController{ Queue<DeferredResult<String>> results = new ConcurrentLinkedQueue<>();
@GetMapping("/dr") public DeferredResult<String> dr(){ log.info("dr"); DeferredResult<String> dr = new DeferredResult<>(); results.add(dr); return dr; }
@GetMapping("/dr/count") public String drCount(){ return String.valueOf(results.size()); }
@GetMapping("/dr/event") public String drEvent(String msg){ for (DeferredResult<String> dr : results) { dr.setResult("Hello " + msg); results.remove(dr); } return"OK"; } }
LoadTest 코드를 이용해 /dr로 100개의 요청을 보내고, 크롬에서 /dr/count로 DeferredResult가 담겨있는 큐의 사이즈를 확인해봅니다. 그리고 마지막으로 /dr/event로 큐에 담긴 DeferredResult 객체에 setResult로 결과를 반환합니다. 100개의 요청이 동시에 완료되는 것을 확인할 수 있습니다.
ResponseBodyEmitter
ResponseBodyEmitter는 Spring 4.2 부터 사용 가능합니다. 비동기 요청 처리의 결과로 하나 이상의 응답을 위해 사용되는 리턴 값 Type 입니다. DeferredResult가 하나의 결과를 생성해 요청을 처리했다면, ResponseBodyEmitter는 여러개의 결과를 만들어 요청을 처리할 수 있습니다.
토비님은 매 라이브 코딩마다 말씀하시길 단순히 코드를 보는 것과 실행 후 결과를 실제로 확인해보는 것은 또 다른 차이가 있을 수 있다고 말씀하십니다. 매우 공감합니다!
위의 내용들은 모두 라이브 코딩에 포함되어 있는 내용이지만 실제로 따라해보면서 해당 내용들을 정리하는 차원으로 작성해보았습니다. 따라하며 토비님이 라이브 코딩을 진행하셨을 때와 달라진 몇 가지를 수정한 부분도 있고, 서버의 스레드를 직접 확인해보고자 처음에는 VisualVM을 사용하려 했지만 계속 실패해 JMC을 이용해 진행했습니다.
라이브 코딩을 보며 자바와 스프링의 비동기 기술에 대해 개인적으로 궁금했던 부분들이 많이 해소되었습니다!! 앞으로 남은 내용들도 따라하며 정리해 보도록 하겠습니다.
그럼 위의 3가지 방법 중 어떤 방법을 사용하는 것이 좋을까? 먼저, 3가지 방식들을 비교하기전에 Test Runner, @RunWith, Rule에 대해서 간단하게 알아보자.
Test Runner
JUnit 프레임워크에서 테스트 클래스 내에 존재하는 각각의 테스트 메소드 실행을 담 당하고 있는 클래스를 Test Runner라고 한다. Test Runner는 테스트 클래스의 구조에 맞게 테스트 메소드들을 실행하고 결과를 표시하는 역할을 수행한다. 우리 눈에는 보이지 않지만, 테스트 케이스를 IDE에서 실행하면 내부적으로 는 JUnit의 BlockJUnit4ClassRunner라는 Test Runner 클래스가 실행되고, IDE는 그 결과를 해석해서 우리에게 보기 편한 화면으로 보여준다.
대부분의 Java 통합개발환경(IDE)은 JUnit 프레임워크를 내장 지원하고 있다. 그래서 종종 JUnit이 독립적인 프레임워크라기보다는 하나의 기능처럼 생각될 수 있다. 하지만 JUnit 프레임워크는 분명 독립적인 소프트웨어이고, 애초부터 그렇게 만들어 졌다. 그렇기 때문에 명령행 프롬프트에서 실행하거나 셸 스크립트 등을 이용해서 실행할 수도 있다.
@RunWith
@RunWith annotation은 JUnit에 내장된 기본 테스트 러너인 BlockJUnit4ClassRunner 대신에 @RunWith(클래스이름.class)를 이용해 JUnit Test 클래스를 실행하기 위한 Test Runner를 명시적으로 지정할 수 있다. 지정된 클래스를 이용해 테스트 클래스 내의 테스트 메소드들을 수행하도록 지정해주는 annotation이다. 일종의 JUnit 프레임워크의 확장지점이다. 이런 구조를 이용해서 많은 애플리케이션이나 프레임워크가 자신에게 필요한 Test Runner를 직접 만들어 자신만의 고유한 기능을 추가해 테스트를 수행하고 있다. 예를 들면, 스프링 프레임워크에서 제공하는 SpringJUnit4ClassRunner, SpringRunner같은 클래스는 이 확장 기능을 이용한 대표적인 사례 중 하나다.
Rule
JUnit 4.7 버전부터 추가된 기능으로 하나의 테스트 클래스 내에서 각 테스트 메소드의 동작 방식을 재정의하거나 추가하기 위해 사용하는 기능이다. 테스트 케이스 수행을 좀 더 세밀하게 조작할 수 있게 된다.
결론
MockitoJUnit의 rule을 사용하면 MockitoJUnitRunner와 똑같은 기능을 수행하면서, 다른 Test Runner를 사용할 수 있다. 사용하고 있는 Mockito의 버전이 1.10.17, JUnit 버전이 4.7 이상이라면 @RunWith가 아닌 MockitoJUnit의 rule을 사용해서 Mockito annotation을 사용하는 field를 초기화 하자
위의 메서드보다 람다식이 간결하고 이해하기 쉽다. 게다가 모든 메서드는 클래스에 포함되어야 하므로 클래스도 새로 만들어야 하고, 객체도 생성해야만 비로소 이 메서드를 호출할 수 있다. 그러나 람다식은 이 모든 과정없이 오직 람다식 자체만으로도 이 메서드의 역할을 대신할 수 있다.
또한, 람다식은 메서드의 매개변수로 전달되어지는 것이 가능하고, 메서드의 결과로 반환될 수도 있다. 람다식으로 인해 메서드를 변수처럼 다루는 것이 가능해진 것이다.
람다식 작성하기
랃마식은 ‘익명 함수’답게 메서드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통{} 사이에 ‘->’를 추가한다.
반환값이 있는 경우, return문 대신 ‘식(expression)’으로 대신 할 수 있다. 식의 연산결과가 자동으로 반환값이 된다. 이때는 ‘문장(statement)’이 아닌 ‘식’이므로 끝에 ‘;’을 붙이지 않는다.
람다식에 선언된 매개변수의 타입은 추론이 가능한 경우는 생략할 수 있는데, 대부분의 경우에 생략가능하다. 람다식에 반환타입이 없는 이유도 항상 추론이 가능하기 때문이다.
매개변수가 하나뿐인 경우에는 괄호()를 생략할 수 있다. 단, 매개변수의 타입이 있으면 괄호()를 생략할 수 없다.
마찬가지로 괄호{}안의 문장이 하나일 때는 괄호{}를 생략할 수 있다. 이 때 문장의 끝에 ‘;’를 붙이지 않아야 한다. 그러나 괄호{} 안의 문장이 return문일 경우 괄호{}를 생략할 수 없다.
함수형 인터페이스(Funtional Interface)
자바에서 모든 메서드는 클래스 내에 포함되어야 한다. 사실 람다식은 익명 클래스의 객체와 동일하다.
하나의 메서드가 선언된 인터페이스를 정의해서 람다식을 다루는 것은 기존의 자바의 규칙들을 어기지 않으면서도 자연스럽다. 그래서 인터페이스를 통해 람다식을 다루기로 결정되었으며, 람다식을 다루기 위한 인터페이스를 함수형 인터페이스(functional interface)라고 부른다.
단, 함수형 인터페이스에는 오직 하나의 추상 메서드만 정의되어 있어야 한다는 제약이 있다. 그래야 람다식과 인터페이스의 메서드가 1:1로 연결 될 수 있기 때문이다. 반면에 static 메서드와 default 메서드의 개수에는 제약이 없다.
**@FunctionalInterface**를 붙이면, 컴파일러가 함수형 인터페이스를 올바르게 정의했는지 확인해주므로, 꼭 붙이는 것이 좋다.
함수형 인터페이스 타입의 매개변수와 반환타입 함수형 인터페이스 MyFunction이 아래와 같이 정의되어 있을 때,
람다식을 참조변수로 다룰 수 있다는 것은 메서드를 통해 람다식을 주고받을 수 있다는 것을 의미한다. 즉, 변수처럼 메서드를 주고받는 것이 가능해진 것이다. (사실상 메서드가 아니라 객체를 주고받는 것이라 달라진 것은 없다.)
람다식의 타입과 형변환 함수형 인터페이스로 람다식을 참조할 수 있는 것일 뿐, 람다식의 타입이 함수형 인터페이스의 타입과 일치하는 것은 아니다. 람다식은 익명 객체이고 익명 객체는 타입이 없다. 정확히는 타입은 있지만 컴파일러가 임의로 이름을 정하기 때문에 알 수 없는 것이다. 그래서 대입 연산자의 양변의 타입을 일치시키기 위해 형변환이 필요하다.
1
MyFunction f = (Myfunction)(() -> {});
람다식은 MyFunction 인터페이스를 직접 구현하지 않았지만, 이 인터페이스를 구현한 클래스의 객체와 완전히 동일하기 때문에 위처럼 형변환을 허용한다. 그리고 이 형변환은 생략가능하다.
람다식은 이름이 없을 뿐 객체인데도, Object 타입으로 형변환 할 수 없다. 람다식은 오직 함수형 인터페이스로만 형변환이 가능하다.
일반적인 익명 객체라면, 객체의 타입이 **’외부클래스이름$번호’**와 같은 형식으로 타입이 결정되었을 텐데, 람다식의 타입은 **’외부클래스이름$$Lambda$번호’**와 같은 형식으로 되어 있다.
외부 변수를 참조하는 람다식 람다식도 익명 객체, 즉 익명 클래스의 인스턴스이므로 람다식에서 외부에 선언된 변수에 접근하는 규칙은 익명 클래스와 동일하다.
람다식 내에서 참조하는 지역변수는 final이 붙지 않았어도 상수로 간주한다.(인스턴스 변수는 변경 가능) 람다식 내에서 지역변수를 참조하면 람다식 내에서나 다른 어느 곳에서도 이 변수의 값을 변경할 수 없다.
java.util.function 패키지
java.util.function 패키지에 일반적으로 자주 쓰이는 형식의 메서드를 함수형 인터페이스로 미리 정의해 놓았다. 매번 새로운 함수형 인터페이스를 정의하지 말고, 가능하면 이 패키지의 인터페이스를 활용하는 것이 좋다.
그래야 함수형 인터페이스에 정의된 메서드 이름도 통일되고, 재사용성이나 유지보수 측면에서도 좋다. 자주 쓰이는 가장 기본적인 함수형 인터페이스는 다음과 같다.
java.lang.Runnable
메서드 : void run()
매개변수도 없고, 반환값도 없음.
Supplier<T>
메서드 : T get()
매개변수는 없고, 반환값만 있음.
Consumer<T>
메서드 : void accept(T t)
Supplier와 반대로 매개변수만 있고, 반환값이 없음
Function<T, R>
메서드 : R apply(T t)
일반적인 함수, 하나의 매개변수를 받아서 결과를 반환
Predicate<T>
메서드 : boolean test(T t)
조건식을 표현하는데 사용됨.
타입 문자 ‘T’는 ‘Type’을, ‘R’은 ‘Return Type’을 의미한다.
인터페이스 이름 앞에 접두사 ‘Bi’가 붙으면 매개변수가 두 개인 함수형 인터페이스이다.
3개 이상의 매개변수를 갖는 함수형 인터페이스를 선언한다면 직접 만들어서 서야한다.
컬렉션 프레임웍의 인터페이스에 디폴트 메서드가 추가되었다.
Collection
boolean removeIf(Predicate<E> filter) : 조건에 맞는 요소를 삭제
List
void replaceAll(UnaryOperator<E> operator) : 모든 요소를 변환하여 대체
Iterable
void forEach(Consumer<T> action) : 모든 요소에 작업 action을 수행
Map
V compute(K key, BiFunction<K,V,V> f) : 지정된 키의 값에 작업 f를 수행
V computeIfAbsent(K key, BiFunction<K,V> f) : 키가 없으면, 작업 f 수행 후 추가
V computeIfPresentt(K key, BiFunction<K,V,V> f) : 지정된 키가 있을 때, 작업 f 수행
V merge(K key, V value, BiFunction<V,V,V> f) : 모든 요소에 병합작업 f를 수행
void forEach(BiConsumer<K,V> action) : 모든 요소에 작업 action을 수행
void replaceAll(BiFunction<K,V,V> f) : 모든 요소에 치환작업 f를 수행
래퍼클래스를 사용하는 것은 비효율적이다. 그래서 보다 효율적으로 처리할 수 있도록 기본형을 사용하는 함수형 인터페이스들이 제공된다.
ToIntFunction<T> : ToBFunction은 출력이 B타입이다. 입력은 generic 타입
intFunction<R> : AFunction은 입력이 A타입이고 출력은 generic 타입
ObjintConsumer<T> : ObjAFunction은 입력이 T, A타입이고 출력은 없다.
Function의 합성과 Predicate의 결합
java.util.function 패키지의 함수형 인터페이스에는 추상형메서드 외에도 디폴트 메서드와 static 메서드가 정의되어 있다.
Function의 합성 함수 f, g가 있을 때, **f.andThen(g)**는 함수 f를 먼저 적용하고, 그 다음에 함수 g를 적용한다. 그리고 **f.compose(g)**는 반대로 g를 먼저 적용하고 f를 적용한다.
1 2 3 4
Function<String, Integer> f = (s) -> Integer.parseInt(s, 16); Function<Integer, String> g = (i) -> Integer.toBinaryString(i); Function<String, String> h = f.andThen(g); Function<Integer, Integer> i = f.compose(g);
Predicate의 결합 여러 조건식을 논리 연산자로 연결해서 하나의 식을 구성할 수 있는 것처럼, 여러 Predicate를 and(), or(), negate()로 연결해서 하나의 새로운 Predicate를 결합할 수 있다.
메서드 참조
람다식을 더욱 간결하게 표현할 수 있는 방법이 있다. 람다식이 하나의 메서드만 호출하는 경우에는 메서드 참조라는 방법으로 람다식을 간략히 할 수 있다.
1 2 3 4 5
/// 변환 전 Function<String, Integer> f = (String s) -> Integer.parseInt(s);
/// 변환 후 Function<String, Integer> f = Integer::parseInt;
하나의 메서드만 호출하는 람다식은 ‘클래스이름::메서드이름’ 또는 ‘참조변수::메서드이름’
으로 바꿀 수 있다.
메서드 참조는 람다식을 마치 static 변수처럼 다룰 수 있게 해준다. 메서드 참조는 코드를 간략히 하는데 유용해서 많이 사용된다.
스트림(stream)
스트림이란?
스트림은 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓았다. 데이터 소스를 추상화했다는 것은, 데이터 소스가 무엇이던 간에 같은 방식으로 다룰 수 있게 되었다는 것과 코드의 재사용성이 높아진다는 것을 의미한다.
스트림은 일회용이다. 스트림은 Iterator처럼 일회용이다. 한번 사용하면 닫혀서 다시 사용할 수 없다. 필요하다면 스트림을 다시 생성해야 한다.
스트림은 작업을 내부 반복으로 처리한다. 내부 반복이라는 것은 반복문을 메서드의 내부에 숨길 수 있다는 것을 의미한다. forEach()는 스트림에 정의된 메서드 중의 하나로 매개변수에 대입된 람다식을 데이터 소스의 모든 요소에 적용한다. (forEach()는 메서드 안에 for문을 넣어버린 것이다.)
스트림의 연산 스트림이 제공하는 다양한 연산을 이용해서 복잡한 작업들을 간단히 처리할 수 있다.
중간 연산 : 연산 결과가 스트림인 연산. 스트림에 연속해서 중간 연산을 할 수 있음
최종 연산 : 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하므로 단 한번만 가능
지연된 연산 스트림 연산에서 한 가지 중요한 점은 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것이다. 중간 연산을 호출하는 것은 단지 어떤 작업이 수행되어야하는지를 지정해주는 것일 뿐이다. 최종 연산이 수행되어야 비로소 스트림의 요소들이 중간 연산을 거쳐 최종 연산에서 소모된다.
병렬 스트림 스트림으로 데이터를 다룰 때의 장점 중 하나가 병렬 처리가 쉽다는 것이다. 병렬 스트림은 내부적으로 fork&join을 이용해서 자동적으로 연산을 병렬로 수행한다. 모든 스트림은 기본적으로 병렬 스트림이 아니므로 병렬 스트림을 사용하려면 parallelStream() 메서드를 사용해 병렬 스트림으로 전환해야 한다.
스트림 만들기
스트림의 소스가 될 수 있는 대상은 배열, 컬렉션, 임의의 수 등 다양하다.
컬렉션 컬렉션의 최고 조상인 Collection에 stream()이 정의되어 있다. 그래서 Collection의 자손인 List와 Set을 구현한 컬렉션 클래스들은 모두 이 메서드로 스트림을 생성할 수 있다. stream()은 해당 컬렉션을 소스로 하는 스트림을 반환한다.
1
Stream<T> Collection.stream()
배열 배열을 소스로 하는 스트림을 생성하는 메서드는 다음과 같이 Stream과 Arrays에 static 메서드로 정의되어 있다.
1 2 3 4
Stream<T> Stream.of(T... values) Stream<T> Stream.of(T[]) Stream<T> Arrays.stream(T[]) Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive)
그리고 int, long, double과 같은 기본형 배열을 소스로 하는 스트림을 생성하는 메서드도 있다.
1 2 3 4
IntStream IntStream.of(int ...values) // 가변인자 IntStream IntStream.of(int[]) IntStream Arrays.stream(int[]) IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
특정 범위의 정수 IntStream과 LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성해서 반환하는 range()와 rangeClosed()를 가지고 있다.
임의의 수 난수를 생성하는데 사용하는 Random 클래스에는 해당 타입의 난수들로 이루어지는 스트림을 반환하는 인스턴스 메서드들이 포함되어 있다.
스트림의 중간연산
스트림 자르기 - skip(), limit() skip()과 limit()은 스트림의 일부를 잘라낼 때 사용한다.
스트림의 요소 걸러내기 - filter(), distinct() distinct()는 스트림에서 중복된 요소들을 제거하고, filter()는 주어진 조건(Predicate)에 맞지 않는 요소를 걸러낸다.
정렬 - sorted() 스트림을 정렬할 때는 sorted()를 사용하면 된다.
sorted()는 지정된 Comparator로 스트림을 정렬하는데, Comparator대신 int값을 반환하는 람다식을 사용하는 것도 가능하다. Comparator를 지정하지 않으면 스트림 요소의 기본 정렬 기준(Comparable)으로 정렬한다. 단, 스트림의 요소가 Comparable을 구현한 클래스가 아니면 예외가 발생한다.
JDK 1.8부터 Comparator 인터페이스에 static 메서드와 디폴트 메서드가 많이 추가되었는데, 이 메서드들을 이용하면 정렬이 쉬워진다. 이 메서드들은 모두 Comparator<T>를 반환한다.
변환 - map() 스트림의 요소에 저장된 값 중에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 때가 있다. 이 때 사용하는 것이 바로 map()이다. 이 메서드의 선언부는 아래와 같으며, 매개변수로 T타입을 R타입으로 변환해서 반환하는 함수를 지정해야한다.
1
Stream<R> map(Function<? super T,? extends R> mapper)
조회 - peek() 연산과 연산 사이에 올바르게 처리되었는지 확인하고 싶다면, peek()를 사용한다. forEach()와 달리 스트림의 요소를 소모하지 않으므로 연산 사이에 여러 번 끼워 넣어도 문제가 되지 않는다.
filter()나 map()의 결과를 확인할 때 유용하게 사용될 수 있다.
mapToInt(), mapToLong(), mapToDouble() map()은 연산의 결과로 Stream<T> 타입의 스트림을 반환하는데, 스트림의 요소를 숫자로 변환하는 경우 IntStream과 같은 기본형 스트림으로 변환하는 것이 더 유용할 수 있다.
count()만 지원하는 Stream<T>와 달리 IntStream과 같은 기본형 스트림은 아래와 같이 숫자를 다루는데 편리한 메서드들을 제공한다.
sum()과 average()를 모두 호출해야할 때, 스트림을 또 생성해야하므로 불편하다. 그래서 summaryStatistics()라는 메서드가 따로 제공된다.
반대로 IntStream을 Stream<T>로 변환할 때는 mapToObj()를, Stream<Integer>로 변환할 때는 boxed()를 사용한다.
1 2 3
IntStream intStream = new Random().ints(1, 46); // 1~45 사이의 정수 Stream<String> lottoStream = intStream.distinct().limit(6).sorted().mapToObj(i -> i + ","); lottoStream.forEach(System.out::print);
flatMap() - Stream<T[]>를 Stream<T>로 변환 스트림의 요소가 배열이거나 map()의 연산결과가 배열인 경우, 즉 스트림의 타입이 Stream<T[]>인 경우, Stream<T>로 다루는 것이 더 편리할 때가 있다. 그럴 때는 map()대신 flatMap()을 사용하면 된다.
1 2 3 4
Stream<String[]> strArrStrm = Stream.of( new String[]{"abc", "def", "ghi"}, new String[]{"ABC", "GHI", "JKLMN"} );
Optional<String> optVal = Optional.of("abc"); String str1 = optVal.get(); // optVal에 저장된 값을 반환. null이면 예외 발생 String str2 = optVal.orElse(""); // optVal에 저장된 값이 null일 때는, ""을 반환
**orElse()**의 변형으로 null을 대체할 값을 반환하는 람다식을 지정할 수 있는 **orElseGet()**과 null일 때 지정된 예외를 발생시키는 **orElseThrow()**가 있다.
1 2
String str3 = optVal2.orElseGet(String::new); // () -> new String()과 동일 String str4 = optVal2.orElseThrow(NullPointerException::new); // null이면 예외 발생
Stream처럼 Optional 객체에도 filter()와 map(), 그리고 flatMap()을 사용할 수 있다.
**isPresent()**는 Optional 객체의 값이 null이면 false를, 아니면 true를 반환한다. **ifPresent()**은 값이 있으면 주어진 람다식을 실행하고 , 없으면 아무 일도 하지 않는다. ifPresent()는 Optional<T>를 반환하는 findAny()나 findFirst()와 같은 최종 연산과 잘 어울린다.
스트림의 최종 연산
최종 연산은 스트림의 요소를 소모해서 결과를 만들어낸다. 그래서 최종 연산후에는 스트림이 닫히게 되고 더 이상 사용할 수 없다. 최종 연산의 결과는 스트림 요소의 합과 같은 단일 값이거나, 스트림의 요소가 담긴 배열 또는 컬렉션일 수 있다.
forEach() 반환 타입이 void이므로 스트림의 요소를 출력하는 용도로 많이 사용된다.
1
voidforEach(Consumer<? super T> action)
조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny() 스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는지, 일부가 일치하는지 아니면 어떤 요소도 일치하지 않는지 확인하는데 사용할 수 있는 메서드들이다. 이 메서드들은 모두 매개변수로 Predicate를 요구하며, 연산결과로 boolean을 반환한다.
통계 - count(), sum(), average(), max(), min() IntStream과 같은 기본형 스트림에는 스트림의 요소들에 대한 통계 정보를 얻을 수 있는 메서드들이 있다. 대부분의 경우 위의 메서드를 사용하기보다 기본형 스트림으로 변환하거나 reduce()와 collect()를 사용해 통계 정보를 얻는다.
리듀싱 - reduce() 스트림의 요소를 줄여나가면서 연산을 수행하고 최종결과를 반환한다. 처음 두 요소를 가지고 연산한 결과를 가지고 그 다음 요소와 연산한다. 그래서 매개변수의 타입이 BinaryOperator<T>인 것이다. 이 과정에서 스트림의 요소를 하나씩 소모하게 되며, 스트림의 모든 요소를 소모하게 되면 그 결과를 반환한다.
최종 연산 count()와 sum() 등은 내부적으로 모두 reduce()를 이용해서 작성되어 있다.
1 2 3 4
int count = intStream.reduce(0, (a,b) -> a + 1); // count() int sum = intStream.reduce(0, (a,b) -> a + b); // sum() int max = intStream.reduce(Integer.MIN_VALUE, (a,b) -> a>b ? a:b); // max() int min = intStream.reduce(Integer.MAX_VALUE, (a,b) -> a<b ? a:b); // min()
Collect()
**collect()는 스트림의 요소를 수집하는 최종 연산으로 리듀싱(reducing)과 유사하다. **collect()가 스트림의 요소를 수집하려면, 어떻게 수집할 것인가에 대한 방법이 정의되어 있어야 하는데, 이 방법을 정의한 것이 바로 컬렉터(collector)이다.
컬렉터는 Collector 인터페이스를 구현한 것으로, 직접 구현할 수도 있고 미리 작성된 것을 사용할 수도 있다. Collectors 클래스는 미리 작성된 다양한 종류의 컬렉터를 반환하는 static 메서드를 갖고 있다.
collect() : 스트림의 최종연산, 매개변수로 컬렉터를 필요로 한다.
Collector : 인터페이스, 컬렉터는 이 인터페이스를 구현해야 한다.
Collectors : 클래스, static 메서드로 미리 작성된 컬렉터를 제공한다.
스트림을 컬렉션과 배열로 변환 - toList(), toSet(), toMap(), toCollection(), toArray() List나 Set이 아닌 특정 컬렉션을 지정하려면, toCollection()에 해당 컬렉션의 생성자 참조를 매개변수로 넣어주면 된다.
1 2 3 4
List<String> names = stuStream.map(Student::getName) .collect(Collectors.toList()); ArrayList<String> list = names.stream() .collect(Collectors.toCollection(ArrayList::new));
Map은 키와 값의 쌍으로 저장해야하므로 객체의 어떤 필드를 키로 사용할지와 값으로 사용할지를 지정해줘야 한다.
스트림에 저장된 요소들을 ‘T[]’ 타입의 배열로 변환하려면, toArray()를 사용하면 된다. 단, 해당 타입의 생성자 참조를 매개변수로 지정해줘야 한다. 만일 매개변수를 지정하지 않으면 반환되는 배열의 타입은 ‘Object[]’이다.
1 2 3
Student[] stuNames = studentStream.toArray(Student[]::new); // OK Student[] stuNames = studentStream.toArray(); // 에러 Object[] stuNames = studentStream.toArray(); // OK
통계 - countint(), summingInt(), averagingInt(), maxBy(), minBy() 최종 연산들이 제공하는 통계 정보를 collect()로 똑같이 얻을 수 있다.
리듀싱 - reducing() 리듀싱 역시 collect()로 가능하다.
1 2 3 4 5 6 7
IntStream intStream = new Random().ints(1, 46).distinct().limit(6);
OptionalInt max = intStream.reduce(Integer::max); Optional<Integer> max = intStream.boxed().collect(reducing(Integer::max));
long sum = intStream.reduce(0, (a, b) -> a + b); long sum = intStream.boxed().collect(reducing(0, (a, b) -> a + b));
1 2
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0, Integer::sum); int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum));
문자열 결합 - joining() 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환한다. 구분자를 지정해줄 수도 있고, 접두사와 접미사도 가능하다. 스트림의 요소가 String이나 StringBuffer처럼 CharSequence의 자손인 경우에만 결합이 가능하므로 스트림의 요소가 문자열이 아닌 경우에는 먼저 map()을 이용해서 스트림의 요소를 문자열로 변환해야 한다.
만일 map()없이 스트림에 바로 joining()하면, 스트림의 요소에 toString()을 호출한 결과를 결합한다.
그룹화와 분할 - groupingBy, partitioningBy() 그룹화는 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미하고, 분할은 스트림의 요소를 두 가지, 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로의 분할을 의미한다. 스트림을 두 개의 그룹으로 나눠야 한다면, partitioningBy()로 분할하는 것이 더 빠르다. 그 외에는 groupingBy()를 쓰면 된다. 그룹화와 분할의 결과는 Map에 반환된다.
Object[] toArray(Object[] a) : 지정된 배열에 Collection의 객체를 저장해서 반환한다.
List 인터페이스
List 인터페이스는 중복을 허용하면서 저장순서가 유지되는 컬렉션을 구현하는데 사용된다.
void add(int index, Object element) : 지정된 위치(index)에 객체(element) 또는 컬렉션에 포함된 객체들을 추가한다.
Object get(int index) : 지정된 위치(index)에 있는 객체를 반환한다.
int indexOf(Object o) : 지정된 객체의 위치(index)를 반환한다. (List의 첫 번째 요소부터 순방향으로 찾는다.)
lastIndexOf(Object o) : 지정된 객체의 위치(index)를 반환한다. (List의 마지막 요소부터 역방향으로 찾는다.)
ListIterator listIterator() : List의 객체에 접근할 수 있는 ListIterator를 반환한다.
Object remove(int index) : 지정된 위치(index)에 있는 객체를 삭제하고 삭제된 객체를 반환한다.
Object set(int index, Object element) : 지정된 위치(index)에 객체(element)를 저장한다.
void sort(Comparator c) : 지정된 비교자(comparator)로 List를 정렬한다.
List subList(int fromIndex, int toIndex) : 지정된 범위(fromIndex 부터 toIndex)에 있는 객체를 반환한다.
Set 인터페이스
Set 인터페이스는 중복을 허용하지 않고 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용된다.
Map 인터페이스
Map 인터페이스는 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스를 구현하는 데 사용된다. 키는 중복될 수 없지만 값은 중복을 허용한다. 구현 클래스로는 Hashtable, HashMap, LinkedHashMap, SortedMap, TreeMap 등이 있다.
void clear() : Map의 모든 객체를 삭제한다.
boolean containsKey(Object key) : 지정된 key객체와 일치하는 Map의 Key객체가 있는지 확인한다.
boolean containsValue(Object value) : 지정된 value객체와 일치하는 Map의 Value객체가 있는지 확인한다.
Set entrySet() : Map에 저장되어 있는 key-value 쌍을 Map.Entry 타입의 객체로 저장한 Set으로 반환한다.
booelan equals(Object o) : 동일한 Map인지 비교한다.
Object get(Object key) : 지정한 key객체에 대응하는 value객체를 찾아서 반환한다.
void putAll(Map t) : 지정된 Map의 모든 key-value 쌍을 추가한다.
Object remove(Object key) : 지정한 key객체와 일치하는 key-value객체를 삭제한다.
int size() : Map에 저장된 key-value 쌍의 개수를 반환한다.
Collection values() : Map에 저장된 모든 value객체를 반환한다.
Map 인터페이스에서 값(value)은 중복을 허용하기 때문에 Collection 타입으로 반환하고, 키(key)는 중복을 허용하지 않기 때문에 Set 타입으로 반환한다.
Map.Entry 인터페이스
Map.Entry 인터페이스는 Map 인터페이스의 내부 인터페이스이다. 내부 클래스와 같이 인터페이스도 인터페이스 안에 인터페이스를 정의하는 내부 인터페이스(inner interface)를 정의하는 것이 가능하다.
Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의해 놓았다.
boolean equals(Object o) : 동일한 Entry인지 비교한다.
Object getKey() : Entry의 key객체를 반환한다.
Object getValue() : Entry의 value객체를 반환한다.
int hashCode() : Entry의 해시코드를 반환한다.
Object setValue(Object value) : Entry의 value객체를 지정된 객체로 바꾼다.
ArrayList
List 인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용한다는 특징을 갖는다.
ArrayList는 기존의 Vector를 개선한 것으로 Vector와 구현원리와 기능적인 측면은 동일하다.
ArrayList는 Object배열을 이용해서 데이터를 순차적으로 저장한다. 계속 배열에 순서대로 저장되며, 배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장된다.
(Vector는 capacity가 부족할 경우 자동적으로 기존의 크기보다 2배의 크기로 증가된다. 그러나 생성자 Vector(int initialCapacity, int capacityIncrement)를 사용해서 인스턴스를 생성한 경우에는 지정해준 capacityIncrement만큼 증가하게 된다.)
배열은 크기를 변경할 수 없기 때문에 ArrayList나 Vector 같이 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는 데는 효율이 좋지만, 용량을 변경해야 할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야하기 때문에 상당히 효율이 떨어진다는 단점을 가지고 있다.
LinkedList
배열은 가장 기본적인 형태의 자료구조로 구조가 간단하며 사용하기 쉽고 데이터를 읽어오는데 걸리는 시간(접근시간, access time)이 가장 빠르다는 장점을 가지고 있지만 다음과 같은 단점도 가지고 있다.
크기를 변경할 수 없다.
크기를 변경할 수 없으므로 새로운 배열을 생성해서 데이터를 복사하는 작업이 필요 하다.
실행속도를 향상시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르지만,
배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야 한다.
이러한 배열의 단점을 보완하기 위해서 링크드 리스트(linked list)라는 자료구조가 고안되었다. 배열은 모든 데이터가 연속적으로 존재하지만 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어 있다.
링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
1 2 3 4
classNode{ Node next; // 다음 요소의 주소를 저장 Object obj; // 데이터를 저장 }
링크드 리스트는 이동방향이 단방향이기 때문에 다음 요소에 대한 접근은 쉽지만 이전요소에 대한 접근은 어렵다. 이 점을 보완한 것이 더블 링크드 리스트(이중 연결리스트, doubly linked list)이다.
더블 링크드 리스트는 링크드 리스트보다 각 요소에 대한 접근과 이동이 쉽기 때문에 링크드 리스트보다 더 많이 사용된다.
1 2 3 4 5
classNode{ Node next; // 다음 요소의 주소를 저장 Node previous; // 이전 요소의 주소를 저장 Object obj; // 데이터를 저장 }
더블 링크드 리스트의 접근성을 보다 향상시킨 것이 ‘더블 써큘러 링크드 리스트(이중 연결형 연결 리스트)’이다. 단순히 더블 링크드 리스트의 첫 번째 요소와 마지막 요소를 서로 연결시킨 것이다.
실제로 LinkedList 클래스는 이름과 달리 ‘링크드 리스트’가 아닌 ‘더블 링크드 리스트’로 구현되어 있는데, 이는 링크드 리스트의 단점인 낮은 접근성(accessability)을 높이기 위한 것이다.
순차적으로 추가/삭제하는 경우에는 ArrayList가 LinkedList보다 빠르다. 만약 ArrayList의 크기가 충분하지 않으면, 새로운 크기의 ArrayList를 생성하고 데이터를 복사하는 일이 발생하게 되므로 순차적으로 데이터를 추가해도 ArrayList보다 LinkedList가 더 빠를 수 있다. 순차적으로 삭제한다는 것은 마지막 데이터부터 역순으로 삭제해나간다는 것을 의미하며, ArrayList는 마지막 데이터부터 삭제할 경우 각 요소들의 재배치가 필요하지 않기 때문에 상당히 빠르다. (단지 마지막 요소의 값을 null로만 바꾸면 되기 때문이다.)
중간 데이터를 추가/삭제하는 경우에는 LinkedList가 ArrayList보다 빠르다. LinkedList는 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 상당히 빠르다. 반면에 ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 늦다. 사실 데이터의 개수가 그리 크지 않다면 어느 것을 사용해도 큰 차이가 나지는 않는다.
데이터의 개수가 많아질수록 데이터를 읽어 오는 시간, 즉 접근시간(access time)은 ArrayList가 LinkedList보다 빠르다. 배열의 경우 만일 n번째 원소의 값을 얻어 오고자 한다면 단순히 아래와 같은 수식을 계산함으로써 해결된다. (배열은 각 요소들이 연속적으로 메모리상에 존재하기 때문이다.)
n번째 데이터의 주소 = 배열의 주소 + n * 데이터 타입의 크기
그러나, LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이 아니기 때문에 처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
Stack과 Queue
순차적으로 데이터를 추가하고 삭제하는 스택에는 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합하지만, 큐는 데이터를 꺼낼 때 항상 첫 번째 저장된 데이터를 삭제하므로, ArrayList와 같은 배열기반의 컬렉션 클래스를 사용한다면 데이터를 꺼낼 때마다 빈 공간을 채우기 위해 데이터의 복사가 발생하므로 비효율적이다. 그래서 큐는 ArrayList보다 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
Stack의 메서드
boolean empty() : Stack이 비어있는지 알려준다.
Object peek() : Stack의 맨 위에 저장된 객체를 반환. pop()과 달리 Stack에서 객체를 꺼내지는 않음.
Object pop() : Stack의 맨 위에 저장된 객체를 꺼낸다.
Object push(Object item) : Stack에 객체(item)를 저장한다.
int search(Object o) : Stack에서 주어진 객체(o)를 찾아서 그 위치를 반환. 못찾으면 -1을 반환.
Object peek() : 삭제없이 요소를 읽어 온다. Queue가 비어있으면 null을 반환
자바에서는 스택을 Stack클래스로 구현하여 제공하고 있지만 큐는 Queue인터페이스로만 정의해 놓았을 뿐 별도의 클래스를 제공하고 있지 않다. 대신 Queue인터페이스를 구현한 클래스들이 있어서 이 들 중의 하나를 선택해서 사용하면 된다.
PriorityQueue
Queue인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼내게 된다는 특징이 있다. 그리고 null은 저장할 수 없다.
Deque(Double-Ended Queue)
Queue의 변형으로, 한 쪽 끝으로만 추가/삭제할 수 있는 Queue와 달리, Deque은 양쪽 끝에 추가/삭제가 가능하다. Deque의 조상은 Queue이며, 구현체로는 ArrayDeque와 LinkedList 등이 있다.
덱은 스택과 큐를 하나로 합쳐놓은 것과 같으며 스택으로 사용할 수도 있고, 큐로 사용할 수도 있다.
Iterator, ListIterator, Enumeration
Iterator, ListIterator, Enumeration은 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다. Enumeration은 Iterator의 구버젼이며, ListIterator는 Iterator의 기능을 향상 시킨 것이다.
Iterator
컬렉션 프레임웍에서는 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화하였다. 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator인터페이스를 정의하고, Collection인터페이스에는 Iterator를 반환하는 iterator()를 정의하고 있다.
iterator()는 Collection인터페이스에 정의된 메서드이므로 Collection인터페이스의 자손인 List와 Set에도 포함되어 있다. 그래서 List나 Set인터페이스를 구현하는 컬렉션은 iterator()가 각 컬렉션의 특징에 알맞게 작성되어 있다.
boolean hasNext() : 읽어 올 요소가 남아있는지 확인한다.
Object next() : 다음 요소를 읽어 온다. next()를 호출하기 전에 hasNext()를 호출해서 읽어 올 요소가 있는지 확인하는 것이 안전하다.
void remove() : next()로 읽어 온 요소를 삭제한다.
ListIterator와 Enumeration
Enumeration은 컬렉션 프레임웍이 만들어지기 이전에 사용하던 것으로 Iterator의 구버젼이라고 생각하면 된다.
ListIterator는 Iterator를 상속받아서 기능을 추가한 것으로, 컬렉션의 요소에 접근할 때 Iterator는 단방향으로만 이동할 수 있는 데 반해 ListIterator는 양방향으로의 이동이 가능하다. 다만 List인터페이스를 구현한 컬렉션에서만 사용할 수 있다.
Arrays
Arrays클래스에는 배열을 다루는데 유용한 메서드가 정의되어 있다. Arrays에 정의된 메서드는 모두 static메서드이다.
배열의 복사 - copyOf(), copyOfRagne()
copyOf()는 배열 전체를, copyOfRange()는 배열의 일부를 복사해서 새로운 배열을 만들어 반환한다. copyOfRange()에 지저왼 범위의 끝은 포함되지 안는다.
배열 채우기 - fill(), setAll()
fill()은 배열의 모든 요소를 지정된 값으로 채운다. setAll()은 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받는다. 이 메서드를 호출할 때는 함수형 인터페이스를 구현한 객체를 매개변수로 지정하던가 아니면 람다식을 지정해야 한다.
배열의 정렬과 검색 - sort(), binarySearch()
sort()는 배열을 정렬할 때, 그리고 배열에 저장된 요소를 검색할 때는 binarySearch()를 사용한다. binarySearch()는 배열에서 지정된 값이 저장된 위치(index)를 찾아서 반환하는데, 반드시 배열이 정렬된 상태이어야 올바른 결과를 얻는다. (검색한 값과 일치하는 요소가 여러 개 있다면, 이 중 어떤 것의 위치가 반환될지는 알 수 없다.)
문자열의 비교와 출력 - equals(), toString(), deepEquals(), deepToString()
toString()은 배열의 모든 요소를 문자열로 편하게 출력할 수 있다. toString은 일차원 배열에만 사용할 수 있으므로, 다차원 배열에서는 deepToString()을 사용해야 한다. deepToString()은 배열의 모든 요소를 재귀적으로 접근해서 문자열을 구성하므로 2차원뿐만 아니라 3차원 이상의 배열에 대해서도 동작한다.
equals()는 두 배열에 저장된 모든 요소를 비교해서 같으면 true, 다르면 false를 반환한다. equals()도 일차원 배열에만 사용가능하므로, 다차원 배열의 비교에는 deepEquals()를 사용해야 한다.
배열을 List로 변환 - asList(Object… a)
asList()는 배열을 List에 담아서 반환한다. 한 가지 주의할 점은 asList()가 반환한 List의 크기를 변경할 수 없다는 것이다. 저장된 내용은 변경 가능하나, 추가 또는 삭제가 불가능하다. 만약 크기를 변경할 수 있는 List가 필요하다면 다음과 같이 하면 된다.
1
List list = new ArrayList(Arrays.asList(1, 2, 3, 4, 5));
parallelXXX(), spliterator(), stream()
parallel로 시작하는 이름의 메서드는 빠른 결과를 얻기 위해 여러 쓰레드가 작업을 나누어 처리하도록 한다. spliterator()는 여러 쓰레드가 처리할 수 있게 하나의 작업을 여러 작업으로 나누는 Spliterator를 반환하며, stream()은 컬렉션을 스트림으로 변환한다.
Comparator와 Comparable
Comparator와 Comparable은 모두 인터페이스로 컬렉션을 정렬하는데 필요한 메서드를 정의하고 있으며, Comparable을 구현하고 있는 클래스들은 같은 타입의 인터페이스끼리 서로 비교할 수 있는 클래스들(주로 wrapper클래스)이 있으며, 기본적으로 오름차순으로 구현되어 있다. 그래서 Comparable을 구현한 클래스는 정렬이 가능하다는 것을 의미한다.
Comparator의 compare()와 Comparable의 compareTo()는 두 객체를 비교한다는 같은 기능을 목적으로 만들어 졌다. compareTo()는 반환값은 int지만 실제로는 비교하는 두 객체가 같으면 0, 비교하는 값보다 작으면 음수, 크면 양수를 반환하도록 구현해야한다. compare()도 객체를 비교해서 음수, 0, 양수 중의 하나를 반환하도록 구현해야한다.
Comparable : 기본 정렬기준(오름차순)을 구현하는데 사용.
Comparator : 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용
Arrays.sort()는 배열을 정렬할 때, Comparator를 지정해주지 않으면 저장하는 객체에 구현된 내용에 따라 정렬된다.
1 2
staticvoidsort(Object[] a)// 객체 배열에 저장된 객체가 구현한 Comparable에 의한 정렬 staticvoidsort(Object[] a, Comparator c)// 지정한 Comparator에 의한 정렬
HashSet
HashSet은 Set인터페이스를 구현한 가장 대표적인 컬렉션이며, Set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다.
ArrayList와 같이 List인터페이스를 구현한 컬렉션과 달리 HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
HashSet은 내부적으로 HashMap을 이용해서 만들어졌으며, HashSet이란 이름은 해싱(hasing)을 이용해서 구현했기 때문에 붙여진 것이다.
HashSet의 add메서드는 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해 추가하려는 요소의 equals()와 hashCode()를 호출하기 때문에 equals()와 hashCode()를 목적에 맞게 오버라이딩해야 한다.
오버라이딩을 통해 작성된 hashCode()는 다음의 세 가지 조건을 만족 시켜야 한다.
실행 중인 애플리케이션 내의 동일한 객체에 대해서 여러 번 hashCode()를 호출해도 동일한 int 값을 반환해야 한다. 하지만, 실행시마다 동일한 int값을 반환할 필요는 없다. (String 클래스는 문자열의 내용으로 해시코드를 만들어 내기 때문에 내용이 같은 문자열에 대한 hashCode() 호출은 항상 동일한 해시코드를 반환한다. 반면에 Object클래스는 객체의 주소로 해시코드를 만들어 내기 때문에 실행할 때마다 해시코드값이 달라질 수 있다.)
equals메서드를 이용한 비교에 의해서 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해서 얻은 결과는 반드시 같아야 한다.
equals메서드를 호출했을 때 false를 반환하는 두 객체는 hashCode() 호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮지만, 해싱(hashing)을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 int값을 반환하는 것이 좋다.
TreeSet
TreeSet은 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다. 이진 검색 트리는 정렬, 검색, 범위검색(range search)에 노은 성능을 보이는 자료구조이며 TreeSet은 이진 검색 트리의 성능을 향상시킨 ‘레드-블랙 트리(Red-Black tree)’로 구현되어 있다.
Set인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
HashMap과 Hashtable
Hashtable과 HashMap의 관계는 Vector와 ArrayList의 관계와 같아서 Hashtable보다는 새로운 버전인 HashMap을 사용할 것을 권한다.
HashMap은 Map을 구현했으므로 Map의 특징인 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로 저장한다는 특징을 갖는다. 그리고 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
HashMap은 Entry라는 내부 클래스를 다시 정의하고, 다시 Entry타입의 배열을 선언하고 있다. 키(key)와 값(value)은 별개의 값이 아니라 서로 관련된 값이기 때문에 각각의 배열로 선언하기 보다는 하나의 클래스로 정의해서 하나의 배열로 다루는 것이 데이터의 무결성적인 측면에서 더 바람직하기 때문이다.
HashMap은 키와 값을 각각 Object타입으로 저장한다. 즉 어떠한 객체도 저장할 수 있지만 키는 주로 String을 대문자 또는 소문자로 통일해서 사용하곤 한다.
Set entrySet() : HashMap에 저장된 키와 값을 엔트리(키와 값의 결합)의 형태로 Set에 저장해서 반환
Object put(Object key, Object value) : 지정된 키와 값을 HashMap에 저장
Collection values() : HashMap에 저장된 모든 값을 컬렉션의 형태로 반환
해싱과 해시함수
해싱이란 해시함수(hash function)을 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법을 말한다. 해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.
해싱에서 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어 있다.
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하게 된다.
검색하고자 하는 값의 키로 해시함수를 호출한다.
해시함수의 계산결과인 해시코드를 이용해서 해당 값이 저장되어 있는 링크드 리스트를 찾는다.
링크드 리스트에서 검색한 키와 일치하는 데이터를 찾는다.
링크드 리스트는 검색에 불리한 자료구조이기 때문에 링크드 리스트의 크기가 커질수록 검색속도가 떨어지게 된다.
하나의 링크드 리스트에 최소한의 데이터만 저장되려면, 저장될 데이터의 크기를 고려해서 HashMap의 크기를 적절하게 지정해주어야 하고, 해시함수가 서로 다른 키에 대해서 중복된 해시코드의 반환을 최소화해야 한다. 그래야 HashMap에서 빠른 검색시간을 얻을 수 있다.
실제로는 HashMap과 같이 해싱을 구현한 컬렉션 클래스에는 Object클래스에 정의된 hashCode()를 해시함수로 사용한다. Object클래스에 정의된 hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어 내기 때문에 모든 객체에 대헤 hashCode()를 호출한 결과가 서로 다른 좋은 방법이다.
String클래스의 경우 Object로부터 상속받은 hashCode()를 오버라이딩해서 문자열의 내용으로 해시코드를 만들어 낸다. 그래서 서로 다른 String인스턴스일지라도 같은 내용의 문자열을 가졌다면 hashCode()를 호출하면 같은 해시코드를 얻는다.
HashSet과 마찬가지로 HashMap에서도 서로 다른 두 객체에 대해 equals()로 비교한 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식한다. (이미 존재하는 키에 대한 값을 저장하면 기존의 값을 새로운 값으로 덮어쓴다.)
그래서 새로운 클래스를 정의할 때 equals()를 오버라이딩해다 한다면 hashCode()도 같이 오버라이딩해서 equals()의 결과가 true인 두 객체의 해시코드가 항상 같도록 해주어야 한다.
그렇지 않으면 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는 equals()의 호출결과가 true지만 해시코드가 다른 두 객체를 서로 다른 것으로 인식하고 따로 저장할 것이다.
TreeMap
TreeMap은 이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다. 그래서 검색과 정렬에 적합한 컬렉션 클래스이다.
검색에 관한 대부분의 경우에서는 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋다. 다만 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하자.
Properties
Properties는 HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로, Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 비해 Properties는 (String, String)의 형태로 저장하는 보다 단순화된 컬렉션클래스이다.
주로 애플리케이션의 환경설정과 관련된 속성(property)을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다.
Collections
Arrays가 배열과 관련된 메서드를 제공하는 것처럼, Collections는 컬렉션과 관련된 메서드를 제공한다. fill(), copy(), sort(), binarySearch() 등의 메서드는 두 클래스에 포함되어 있으며 같은 기능을 한다.
컬렉션의 동기화
멀티 쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체의 동기화(synchronization)가 필요하다.
Vector와 Hashtable과 같은 구버전(JDK1.2 이전)의 클래스들은 자체적으로 동기화처리가 되어 있는데, 멀티쓰레드 프로그래밍이 아닌 경우에는 불필요한 기능이 되어 성능을 떨어뜨리는 요인이 된다.
그래서 새로 추가된 ArrayList와 HashMap과 같은 컬렉션은 동기화를 자체적으로 처리하지 않고 필요한 경우에만 java.util.Collections클래스의 동기화 메서드를 이용해서 동기화처리가 가능하도록 변경하였다.
1 2 3 4 5 6
static Collection synchronizedCollection(Collection c) static List synchronizedList(List list) static Set synchronizedSet(Set s) static Map synchronizedMap(Map m) static SortedSet synchronizedSortedSet(SortedSet s) static SortedMap synchronizedSortedMap(SortedMap m)
변경불가 컬렉션 만들기
컬렉션에 저장된 데이터를 보호하기 위해서 컬렉션을 변경할 수 없게 읽기전용으로 만들어야 할 때가 있다.
1 2 3 4 5 6
static Collection unmodifiableCollection(Collection c) static List unmodifiableList(List list) static Set unmodifiableSet(Set s) static Map unmodifiableMap(Map m) static SortedSet unmodifiableSortedSet(SortedSet s) static SortedMap unmodifiableSortedMap(SortedMap m)
컬렉션 클래스 정리 & 요약
ArrayList : 배열기반, 데이터의 추가와 삭제에 불리, 순차적인 추가/삭제는 제일 빠름. 임의의 요소에 대한 접근성이 뛰어남.
LinkedList : 연결기반, 데이터의 추가와 삭제에 유리. 임의의 요소에 대한 접근성이 좋지 않다.
HashMap : 배열과 연결이 결합된 형태. 추가, 삭제, 검색, 접근성이 모두 뛰어남. 검색에는 최고성능을 보인다.