Spring MVC는 DispatcherServlet의 등장으로 web.xml의 역할이 축소되었습니다. 이전에는 서블릿을 URL로 활용하기 위해서는 반드시 web.xml에 등록해야 했지만, 이제는 DispatcherServlet이 해당 어플리케이션으로 들어오는 요청을 모두 핸들링 해주기 때문입니다.
web.xml의 역할이 축소되었지만, <servlet>으로 DispatcherServlet을 등록해줘야 하며, 이 객체의 URL 적용범위 또한 web.xml에 설정해야 합니다. 또한 encoding과 관련된 <filter>나 <listener>를 등록하기 위해서 web.xml은 필요합니다.
그러나 web.xml에서 중요하게 사용되었던 <servlet> 매핑은 이제 DispatcherServlet이 대신 맡아서 처리하게 되었습니다. web.xml에 DispatcherServlet의 을 ‘/‘로 설정함으로써 동시에 이제 모든 요청은 DispatcherServlet으로 전달됩니다. 물론 DispatcherServlet을 web.xml에 등록해도 계속 서블릿을 web.xml에 매핑해서 사용할 수 있지만, 이런 옛 방식을 버리고 DispatcherServlet을 이용해 웹 개발을 한다면 앞으로 서블릿 파일을 만들 필요도 없어지고 동시에 놀라운 @MVC의 혜택을 얻을 수 있습니다.
DispatcherServlet을 이용한다는 것은 스프링에서 제공하는 @MVC를 이용하겠단 뜻입니다. @MVC는 그동안 추상적으로 알아오고 발전했던 MVC(Model, View, Controller) 설계 영역을 노골적으로 분할하여 사용자가 무조건 MVC로 어플리케이션을 설계하게끔 유도하는 방식입니다. 즉, @MVC를 이용해 어플리케이션을 개발한다면 MVC 설계의 원칙대로 웹 어플리케이션을 제작할 수 있게 된다는 뜻입니다.
그럼 간단하게 DispatcherServlet이 담당하는 역할이 무엇인지 알아봅시다. 먼저 DispatcherServlet에 대해 간단히 정의해보자면, 각각 분리하여 만든 Model, View, Controller를 조합하여 브라우저로 출력해주는 역할을 수행합니다.
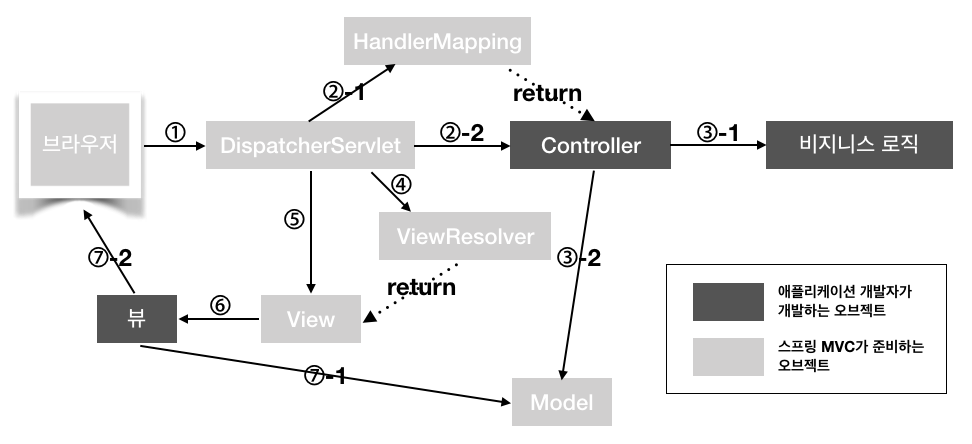
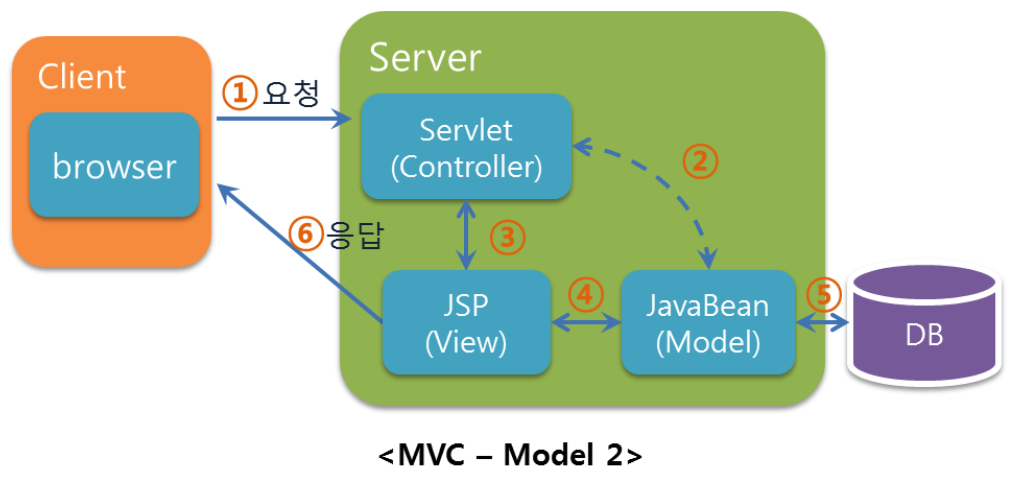
Spring MVC 구조
등장 요소
DispatcherServlet : 프런트 컨트롤러 담당, 모든 HTTP 요청을 받아들여 그 밖의 오브젝트 사이의 흐름을 제어, 기본적으로 스프링 MVC의 DispatcherServlet 클래스를 그대로 적용
HandlerMapping : 클라이언트의 요청을 바탕으로 어느 컨트롤러를 실행할지 결정
Model : 컨트롤러에서 뷰로 넘겨줄 오브젝트를 저장하기 위한 오브젝트, HttpServletRequest와 HttpSession처럼 String 형 키와 오브젝트를 연결해서 오브젝트를 유지
ViewResolver : View 이름을 바탕으로 View 오브젝트를 결정
View : 뷰에 화명 표시 처리를 의뢰
비즈니스 로직 : 비즈니스 로직을 실행. 애플리케이션 개발자가 비즈니스 처리 사양에 맞게 작성
컨트롤러(Controller) : 클라이언트 요청에 맞는 프레젠테이션 층의 애플리케이션 처리를 실행해야 함. 애플리케이션 개발자가 애플리케이션 처리 사양에 맞게 작성
뷰 / JSP 등 : 클라이언트에 대해 화면 표시 처리. 자바에서는 JSP 등으로 작성하는 일이 많으며, 애플리케이션 개발자가 화면의 사양에 맞게 작성
동작 순서
DispatcherServlet은 브라우저로부터 요청을 받아들입니다.
DispatcherServlet은 요청된 URL을 HandlerMapping 오브젝트에 넘기고 호출 대상의 컨트롤러 오브젝트를 얻어 URL에 해당하는 메서드를 실행합니다.
컨트롤러 오브젝트는 비즈니스 로직으로 처리를 실행하고, 그 결과를 바탕으로 뷰에 전달할 오브젝트를 Model 오브젝트에 저장합니다. 끝으로 컨트롤러 오브젝트는 처리 결과에 맞는 View 이름을 반환합니다.
DispatcherServlet은 컨트롤러에서 반환된 View 이름을 ViewResolver에 전달해서 View 오브젝트를 얻습니다.
DispatcherServlet은 View 오브젝트에 화면 표시를 의뢰합니다.
View 오브젝트는 해당하는 뷰를 호출해서 화면 표시를 의뢰합니다.
뷰는 Model 오브젝트에서 화면 표시에 필요한 오브젝트를 가져와 화면 표시 처리를 실행합니다.
웹 서비스와 RESTful한 방식이 시스템을 구성하는 주요 요소로 자리 잡으면서 웹 시스템간에 XML이나 JSON 등의 형식으로 데이터를 주고 받는 경우가 증가했습니다.
이에 따라 스프링 MVC도 **클라이언트에서 전송한 XML 데이터나 JSON 또는 기타 데이터를 컨트롤러에서 DOM 객체나 자바 객체로 변환해서 받을 수있는 기능(수신)**을 제공하고 있으며, 비슷하게 **자바 객체를 XML이나 JSON 또는 기타 형식으로 변환해서 전송할 수 있는 기능(송신)**을 제공하고 있습니다.
@RequestBody 어노테이션과 @ResponseBody 어노테이션은 각각 HTTP 요청의 body 부분을 자바 객체로 변환하고 자바 객체를 HTTP 응답 body로 변환하는데 사용됩니다.
@RequestBody
Spring MVC 컨트롤러에서 HTTP 요청의 body 부분을 자바 객체로 mapping할 때 @RequestBody 어노테이션을 사용합니다. @RequestBody 어노테이션의 기능은 다음과 같습니다.
@ReuqestBody를 사용하지 않는 경우 : query parameter, form data를 객체에 mapping한다.
@ReuqestBody를 사용하는 경우 : body에 있는 data를 HttpMessageConverter를 이용해 선언한 객체에 mapping한다.
@ResponseBody
@ResponseBody는 @RequestBody와 비슷한 방식으로 동작합니다. @ResponseBody가 메소드 레벨에서 부여되면 메소드가 리턴하는 오브젝트는 ContentNegotiatingViewResolver를 이용해 뷰를 통해 결과를 만들어내는 것이 아닌, message converter를 통해 바로 HTTP 응답의 메시지 본문으로 변환됩니다.
ContentNegotiatingViewResolver는 등록되어 있는 ViewResolver중에서 controller 메소드의 리턴값을 통해 등록된 ViewResolver 중에서 적합한 형태로 처리해서 반환하는 반면, @ResponseBody는 @RequestBody가 선택한 형식으로 결과값을 변환하여 반환한다고 보면 됩니다.
@RestController는 @Controller와 @ResponseBody를 동시에 사용하는 것과 같습니다. @Controller를 사용하는 경우에만 @ResponseBody를 추가하면 됩니다.
HttpMessageConverter를 이용한 변환 처리
AnnotationMethodHandlerAdapter에는 HttpMessageConverter 타입의 메시지 변환기인 message converter가 여러 개 등록되어 있습니다. @RequestBody가 붙은 파라미터가 있으면 HTTP 요청의 미디어 타입과 파라미터의 타입을 먼저 확인하고, message converter 중에서 해당 미디어 타입과 파라미터 타입을 처리할 수 있다면, HTTP 요청의 body 부분을 통째로 변환해서 지정된 메소드 파라미터로 전달해줍니다.
HttpMessageConverter의 종류
AnnotationMethodHandlerAdapter 클래스는 @RequestBody 어노테이션이 적용된 파라미터나 @ResponseBody 어노테이션이 적용된 메서드에 대해 HttpMessageConverter를 사용해서 변환을 처리합니다. 주요 HttpMessageConverter 구현 클래스는 다음과 같습니다.
SourceHttpMessageConverter : HTTP 메시지와 javax.xml.transform.Source 사이 변환을 처리한다. 컨텐츠 타입은 application/xml 또는 text/xml이다.
FormHttpMessageConverter : HTML 폼 데이터를 MultiValueMap으로 전달받을 때 사용된다. 지원하는 컨텐츠 타입은 application-x-www-form-urlencorded이다.
MappingJacksonHttpMessageConverter : Jackson 라이브러리를 이용해서 JSON HTTP 메시지와 객체 사이의 변환을 처리한다. 컨텐츠 타입은 applicaion/json이다.
MarshallingHttpMessageConverter : 스프링의 Marshaller와 unMarshaller를 이용해서 XML HTTP 메시지와 객체 사이의 변환을 처리한다. 컨텐츠 타입은 application/xml 또는 text/xml이다.
Content-Type과 Accept header 기반의 변환 처리
AnnotationMethodHandlerAdapter가 HttpMessageConverter를 이용해서 request의 body 데이터를 @RequestBody 어노테이션이 적용된 자바 객체로 변환할 때에는, HTTP 요청 header의 Content-Type에 명시된 미디어 타입(MIME)을 지원하는 HttpMessageConverter 구현체를 선택합니다. 예를 들어, 요청 미디어 타입이 application/json이고 @RequestBody 어노테이션이 적용된 경우 MappingJacksonHttpMessageConverter가 선택됩니다.
비슷하게 @ResponseBody 어노테이션을 이용해서 리턴한 객체를 HTTP 응답 객체로 변환할 때에는 HTTP 요청 header의 Accept에 명시된 미디어 타입(MIME)을 지원하는 HttpMessageConveter 구현체를 선택합니다. 예를 들어, Accept에 명시된 값이 application/json이고 @ResponseBody 어노테이션이 적용된 메서드의 리턴 타입이 자바 객체인 경우 MappingJacksonHttpMessageConverter가 선택됩니다.
몇 년에 걸쳐 객체지향 프로그래밍(Object Oriented Programming, OOP)은 절차적 프로그래밍 방법론을 거의 완벽히 대체하며 프로그래밍 방법론의 새로운 패러다임으로 떠오르게 되었습니다. 객체지향적 방식의 가장 큰 이점 중 하나는 소프트웨어 시스템이 여러 개의 독립된 클래스들의 집합으로 구성된다는 것입니다. 이들 각각의 클래스들은 잘 정의된 고유 작업을 수행하게 되고, 그 역할 또한 명백히 정의되어 있습니다.
객체지향 어플리케이션에서는 어플리케이션이 목표한 동작을 수행하기 위해 이런 클래스들이 서로 유기적으로 협력합니다. 하지만 시스템의 어떤 기능들은 특정 한 클래스가 도맡아 처리할 수 없습니다. 이들은 시스템 전체에 걸쳐 존재하며 해당 코드들을 여러 클래스들에서 사용합니다. 이런 현상을 횡단적(cross-cutting)이라 표현합니다. 분산 어플리케이션에서의 동기화(locking) 문제, 예외 처리, 로깅 등이 그 예입니다. 물론 필요한 모든 클래스들에 관련 코드를 집어 넣으면 해결될 문제입니다. 하지만 이런 행위는 각각의 클래스는 잘 정의된(well-defined) 역할만을 수행한다는 기본 원칙에 위배됩니다. 이런 상황이 바로 Aspect Oriented Programming (AOP)가 생겨난 원인이 되었습니다.
AOP에서는 aspect라는 새로운 프로그램 구조를 정의해 사용합니다. 쉽게 class, interface 등과 같이 특정한 용도의 구조라 생각하면 됩니다. Aspect 내에는 프로그램의 여러 모듈들에 흩어져 있는 기능(하나의 기능이 여러 모듈에 흩어져 있음을 뜻함)을 모아 정의하게 됩니다. 전체적으로, 어플리케이션의 각각의 클래스는 자신에게 주어진 기능만을 수행하고, 추가된 각 aspect들이 횡단적인 행위(기능)들을 모아 처리하며 전체 프로그램을 이루는 형태가 만들어집니다.
AOP가 필요한 사례
이해를 돕기 위해 어플리케이션의 여러 스레드들이 하나의 데이터를 공유하는 상황을 가정해봅시다. 공유 데이터는 Data라는 객체(Data 클래스의 인스턴스)로 캡슐화되어 있습니다. 서로 다른 여러 클래스의 인스턴스들이 하나의 Data 객체를 사용하고 있으나, 이 공유 데이터에 접근할 수 있는 객체는 한 번에 하나씩이어야만 합니다. 그렇다면 어떤 형태이건 동기화 메커니즘이 도입되어야 할 것입니다. 즉, 어떤 한 객체가 데이터를 사용중이라면 Data 객체는 잠겨(lock)져야 하며, 사용이 끝났을 때 해제(unlock)되어야 합니다. 전통적인 해결책은 공유 데이터를 사용하는 모든 클래스들이 하나의 공통 부모 클래스(“worker” 라 부르겠습니다)로부터 파생되는 형태로 만드는 것입니다. worker 클래스에는 lock()과 unlock() 메소드를 정의하여 작업의 시작과 끝에 이 메소드를 호출토록 하면 됩니다. 하지만 이런 형태는 다음과 문제들을 파생시킵니다.
공유 데이터를 사용하는 메소드는 상당히 주의해서 작성되어야 합니다. 동기화 코드를 잘못 삽입하면 데드락(dead-lock)이 발생하거나 데이터 영속성이 깨질 수 있습니다. 또한 메소드 내부는 본래의 기능과 관련 없는 동기화 관련 코드들로 더럽혀질 것입니다. Java와 같은 단일 상속 모델에서는 worker를 만든다는 것이 불가능할 수 있습니다. 어떤 클래스들은 이미 다른 클래스들로부터 확장되었을 수도 있기 때문입니다. 이는 특히 클래스 계층 구조 설계가 마무리된 후, 뒤늦게 동기화의 필요성을 깨달았을 때 흔히 발생합니다. 동기화를 신경 쓰지 않은 범용 클래스 라이브러리를 통해 공유 데이터에 접근하려 하는 경우가 한 예가 될 수 있습니다. 앞서 가정한 어플리케이션에서 동기화 개념은 다음과 같은 속성들을 갖습니다.
동기화는 worker 클래스에 할당된 최우선 작업이 아니다.
동기화 메커니즘은 worker 클래스의 최우선 작업과 독립적이다.
한 객체에 대한 동기화 관련 코드가 시스템 전체에 횡단적으로 존재한다. 다수의 클래스와 더 많은 수의 메소드들이 이 동기화 메커니즘에 영향 받는다.
AOP에서는 이런 형태의 문제를 해결하기 위해 새로운 형태의 접근 방법을 제기하고 있습니다. AOP는 새로 도입된 프로그램 구조를 통해 시스템에 횡단되어 있는 기능들을 정의해 처리하도록 했습니다. 이 새로운 구조를 aspect라 부릅니다.
위의 예시에 Lock이라는 aspect를 도입해보겠습니다. Lock aspect에는 다음과 같은 역할이 할당될 것입니다.
Data 객체를 사용하는 클래스들을 위해 lock 및 unlock 메커니즘을 제공한다(lock(), unlock()).
Data 객체를 수정하는 모든 메소드들이 수행 전에 lock()을 호출하고, 수행 후에는 unlock()을 호출함을 보장한다.
이상의 기능을 Data 객체를 사용하는 클래스의 자바 소스를 변경하지 않고 투명하게 수행한다.
Aspect는 또 어떤 일들을 수행할 수 있을까?
특정 메소드(ex. 객체 생성 과정 추적) 호출을 로깅할 경우 aspect가 도움이 될 수 있습니다. 기존 방법대로라면 log() 메소드를 만들어 놓은 후, 자바 소스에서 로깅을 원하는 메소드를 찾아 log()를 호출하는 형태를 취해야할 것입니다. 그러나 여기서 AOP를 사용하면 원본 자바 코드를 수정할 필요 없이 원하는 위치에서 원하는 로깅을 수행할 수 있습니다. 이런 작업 모두는 aspect라는 외부 모듈에 의해 수행됩니다. 또 다른 예로 예외 처리가 있습니다. Aspect를 이용해 여러 클래스들의 산재된 메소드들에 영향을 주는 catch() 조항(clause)을 정의해 어플리케이션 전체에 걸쳐 지속적이고 일관적으로 예외를 처리할 수 있습니다.
AOP 용어
JoinPoint : 메소드 호출이나 특정 예외를 던지는 것과 프로그램이 실행되는 지점을 이야기한다.
Advice : Logging과 같은 횡단관심사의 경우 거의 모든 클래스에 분산되어 있는 것을 볼 수 있다. 이와 같은 횡단관심사를 여러 영역에 분산해 구현하는 것이 아니라 한 곳에 모아서 구현하는 것을 Advice라고 한다. 즉, JoinPoint에서 실행되는 코드를 말한다.
Point-cut : 횡단관심사에 해당하는 기능을 구현한 부분이 Advice라고 했다. 그렇다면 이렇게 구현되어 있는 Advice를 어떤 패턴을 가지는 클래스와 메소드에 적용할지를 결정하는 것이 Point-cut이다. 즉 해당 Advice가 적용되어야 하는 곳을 가리키는 것이 Point-cut이다. Point-cut은 JoinPoin와 Advice의 중간에 있으면서 처리가 JoinPoint에 이르렀을 때 Advice를 호출할지를 결정한다.
Aspect : Aspect는 Advice와 Point-cut을 합쳐서 하나의 Aspect라고 칭한다. Advice와 Point-cut을 이용하여 Logging이라는 관심사를 분리하여 독립적으로 구현할 수 있었다. 이처럼 Advice와 Point-cut을 이용하여 원하는 관심사를 구현하는 것을 하나의 Aspect라고 한다. 지금까지 살펴본 Logging은 Logging Aspect가 될 것이다.
Introduction : 실행되고 있는 클래스에 새로운 인터페이스를 추가하여 원래의 Object가 가지고 있는 속성, 행위 이외의 다른 일이 가능하도록 하게 된다.
Spring AOP의 Advice는 여러개의 Advice를 가집니다. Spring에서 지원하고 있는 Advice는 다음과 같습니다.
Before advice : JoinPoint 앞에서 수행되는 Advice. 하지만 JoinPoint를 위한 수행 흐름 처리(execution flow proceeding)를 막기위한 능력(만약 예외를 던지지 않는다면)을 가지지는 않는다.
After returning advice : JoinPoint가 완전히 정상 종료한 다음 실행되는 Advice. (메소드가 예외를 던지는것 없이 반환된다면 완성된 후에 수행되는 advice.)
Around advice : JoinPoint 앞뒤에서 실행되는 Advice. Around advice는 메소드 호출 전후에 사용자 지정 행위를 수행한다.
Throws advice : JoinPoint에서 예외가 발생했을 때 실행되는 Advice. Spring은 강력한 타입의 Throws advice를 제공한다. 그래서 Throwable 나 Exception으로 부터 형변환 할 필요가 없는 관심가는 예외(그리고 하위클래스)를 처리하는 코드를 쓸 수 있다.
IoC 컨테이너 개념을 이해하기 위하여 이와 같은 컨테이너가 왜 등장하게 되었는지를 먼저 이해하는 것이 중요합니다.
애플리케이션 코드를 작성할 때, 특정 기능이 필요하면 라이브러리 사용하곤 합니다. 이때는 프로그램의 흐름을 제어하는 주체가 애플리케이션 코드입니다. 하지만 프레임워크(Framework) 기반의 개발에서는 프레임워크 자신이 흐름을 제어하는 주체가 되어, 필요 할 때마다 애플리케이션 코드를 호출하여 사용합니다.
프레임워크에서 이 제어권을 가지는 것이 바로 컨테이너(Container)입니다. 객체에 대한 제어권이 개발자로부터 컨테이너에게 넘어가면서 객체의 생성부터 생명주기 관리까지의 모든 것을 컨테이너가 맡아서 하게됩니다. 이를 일반적인 제어권의 흐름이 바뀌었다고 하여 IoC(Inversion of Control : 제어의 역전)라고 합니다.
먼저 지금까지 일반적으로 개발하던 방식에 대해서 생각해보아야 합니다. 모든 인스턴스에 대한 생성 권한은 지금까지 모든 개발자들에게 있었습니다. 즉, 작성하는 코드상에서 개발자가 직접 생성했다는 것입니다. EJB나 IoC 컨테이너를 사용하지 않았던 개발자들은 지금까지 이와 같은 방식을 사용했습니다.
EJB는 각 개발자들이 모든 인스턴스의 생성 권한에 제약을 가하는 첫번째 프레임워크입니다. EJB는 서비스를 위해 생성되는 컴포넌트에 대한 생성 권한을 EJB 컨테이너에게 위임했습니다. 생성된 인스턴스는 EJB 컨테이너가 생명주기를 관리했습니다. EJB가 EJB 컨테이너에 의하여 관리됨으로 인해 큰 장점을 얻을 수 있었습니다. 그러나 장점 이외에 EJB가 가지고 있는 한계에 부딪히게 되었으며, 이 같은 요구사항을 해결하기 위해 EJB의 한계를 극복하기 위한 시도가 발생했습니다.
그래서 등장한 것이 경량(LightWeight) IoC 컨테이너 입니다. 경량 IoC 컨테이너는 EJB 컨테이너가 가지고 있던 단점을 보완하기 위하여 탄생한 컨테이너 개념입니다. Spring 프레임워크에서 지원하는 IoC 컨테이너는 우리들이 흔히 개발하고 사용해왔던 일반 POJO(Plain Old Java Object) 클래스들이 지금까지 EJB를 통하여 실행했던 많은 기능들을 서비스 가능하도록 지원합니다. 또한, EJB 컨테이너가 지원하고 있던 Transaction, Object Pooling, 인스턴스 생명주기 관리등의 기능들을 Spring 컨테이너가 지원하며 부가적으로 테스트의 용이성(애플리케이션 품질의 향상), 개발 생산성을 향상 시킬 수 있습니다.
사용하는 목적
IoC를 사용하는 목적에 대해서는 지금까지의 클래스호출 방식의 변화를 살펴보면 더 쉽게 이해할 수 있습니다.
클래스 호출 방식
클래스내에 선언과 구현이 같이 있기 때문에 다양한 형태로 변화가 불가능합니다.
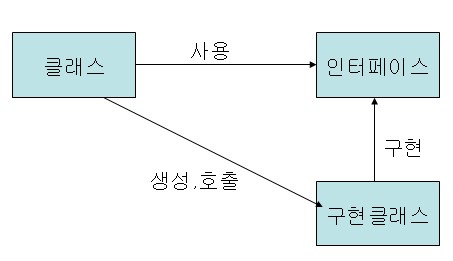
인터페이스 호출 방식
클래스를 인터페이스와 인터페이스를 상속받아 구현하는 클래스로 분리했습니다. 구현클래스 교체가 용이하여 다양한 변화가 가능합니다. 그러나 구현클래스 교체시 호출클래스의 코드에서 수정이 필요합니다. (부분적으로 종속적)
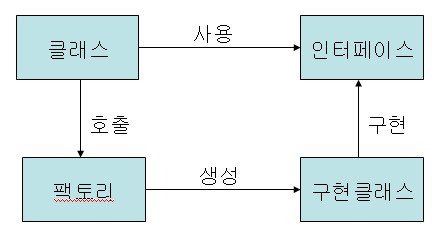
팩토리 호출 방식
팩토리 방식은 팩토리가 구현클래스를 생성하기 때문에 호출클래스는 팩토리를 호출 하는 코드로 충분합니다. 구현클래스 변경시 팩토리만 수정하면 되기 때문에 호출클래스에는 영향을 미치지 않습니다. 그러나 호출클래스에서 팩토리를 호출하는 코드가 들어가야 하는 것 또한 팩토리에 의존함을 의미합니다.
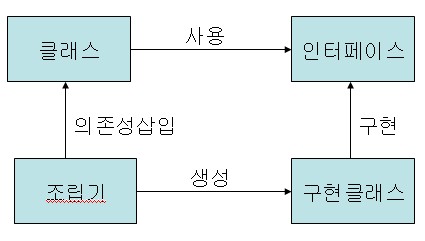
IoC
팩토리 패턴의 장점을 더해 어떠한 것에도 의존하지 않는 형태가 되었습니다. 실행시점에 클래스간의 관계가 형성이 됩니다. 즉, 의존성이 삽입된다는 의미로 IoC를 DI라는 표현으로 사용합니다.
IoC 용어 정리
bean : 스프링에서 제어권을 가지고 직접 만들어 관계를 부여하는 오브젝트 Java Bean, EJB의 Bean과 비슷한 오브젝트 단위의 애플리케이션 컴포넌트이다. 하지만 스프링을 사용하는 애플리케이션에서 만들어지는 모든 오브젝트가 빈은 아니다. 스프링의 빈은 스프링 컨테이너가 생성하고 관계설정, 사용을 제어해주는 오브젝트를 말한다.
bean factory : 스프링의 IoC를 담당하는 핵심 컨테이너 Bean을 등록/생성/조회/반환/관리 한다. 보통 bean factory를 바로 사용하지 않고 이를 확장한 application context를 이용한다. BeanFactory는 bean factory가 구현하는 interface이다. (getBean()등의 메서드가 정의되어 있다.)
application context : bean factory를 확장한 IoC 컨테이너 Bean의 등록/생성/조회/반환/관리 기능은 bean factory와 같지만, 추가적으로 spring의 각종 부가 서비스를 제공한다. ApplicationContext는 application context가 구현해야 하는 interface이며, BeanFactory를 상속한다.
configuration metadata : application context 혹은 bean factory가 IoC를 적용하기 위해 사용하는 메타정보 스프링의 설정정보는 컨테이너에 어떤 기능을 세팅하거나 조정하는 경우에도 사용하지만 주로 bean을 생성/구성하는 용도로 사용한다.
container (ioC container) : IoC 방식으로 bean을 관리한다는 의미에서 bean factory나 application context를 가리킨다. application context는 그 자체로 ApplicationContext 인터페이스를 구현한 오브젝트를 말하기도 하는데, 하나의 애플리케이션에 보통 여러개의 ApplicationContext 객체가 만들어진다. 이를 통칭해서 spring container라고 부를 수 있다.
스프링을 사용하지 않을 때 일어날 수 있는 문제
스프링의 특징을 알아보기 앞서 스프링을 사용하지 않을 때 어떤 문제가 일어날 수 있는지 알아보겠습니다.
오브젝트의 생명 주기 문제
부품화 문제
기술 은닉과 부적절한 기술 은닉 문제
이러한 문제를 해결하지 않는 한 웹 애플리케이션은 리소스를 잘 이용하지 못하고, 테스트하기 어려우며, 확장이나 변경 또한 어려울 것입니다. 스프링은 이러한 문제를 해결하기 위해 만들어진 컨테이너라고도 할 수 있습니다. 스프링은 위의 문제를 다음과 같이 해결합니다.
오브젝트의 생명 주기 문제는 DI 컨테이너로 해결
부품화 문제는 DI 컨테이너로 해결
기술 은닉과 부적절한 기술 은닉 문제는 AOP로 해결
DI
IoC는 직관적이지 못하기 때문에 DI(Dependency Injection)라고도 부릅니다. DI는 오브젝트를 생성하고 오브젝트끼리의 관계를 생성해 소프트웨어의 부품화 및 설계를 가능하게 합니다. DI를 이용하면 인터페이스 기반의 컴포넌트를 쉽게 구현할 수 있습니다. DI를 우리말로 옮기면 의존 관계의 주입입니다. 쉽게 말하면 오브젝트 사이의 의존 관계를 만드는 것입니다. 어떤 오브젝트의 프로퍼티(인스턴스 변수)에 오브젝트가 이용할 오브젝트를 설정한다는 의미입니다. 이를 학술적으로 말하면, 어떤 오브젝트가 의존(이용)할 오브젝트를 주입 혹은 인젝션(프로퍼티에 설정)한다는 것입니다. DI를 구현하는 컨테이너는 단순한 인젝션 외에도 클래스의 인스턴스화 등의 생명 주기 관리 기능이 있는 경우가 많습니다.
클래스에서 new 연산자가 사라졌다는 사실이 중요합니다. 클래스에서 new 연산자가 사라짐으로써 개발자가 팩토리 메서드 같은 디자인 패턴을 구사하지 않아도 DI 컨테이너가 건내주는 인스턴스를 인터페이스로 받아서 인터페이스 기반의 컴포넌트화를 구현할 수 있게 됐습니다.
DI 컨테이너의 구상 클래스 인스턴스화는(디폴트로는) 1회만 실행합니다. 생성된 인스턴스는 필요한 곳에서 사용합니다. 이렇게 하는 것으로 서비스와 DAO처럼 Singleton으로 만들고 싶은 컴포넌트를 특별히 Singleton으로 만들지 않아도 간단히 실현되게 해줍니다.
스프링에는 크게 (1)XML로 작성된 Bean 정의 파일을 이용한 DI, (2)어노테이션을 이용한 DI, (3)JavaConfig에 의한 DI가 있습니다. 이번 포스팅에서는 어노테이션을 이용한 DI에 대해 알아보겠습니다.
@Autowired와 @Component
인스턴스 변수 앞에 @Autowired를 붙이면 DI 컨테이너가 그 인스턴스 변수의 형에 대입할 수 있는 클래스를 @Component가 붙은 클래스 중에서 찾아내 그 인스턴스를 인젝션해줍니다(정확히는 Bean 정의에서 클래스를 스캔할 범위를 정해야 합니다). 인스턴스 변수로의 인젝션은 접근 제어자가 private라도 인젝션 할 수 있으므로 Setter 메서드를 만들 필요는 없습니다. (과거에 캡슐화의 정보 은닉에 반하는 것이 아니냐는 논의가 있었지만, 현재는 편리함에 밀려 그런 논의를 보기 힘들어졌습니다.)
만약 @Component가 붙은 클래스가 여러 개 있어도 형이 다르면 @Autowired가 붙은 인스턴스 변수에 인젝션되지 않습니다. 이렇게 형을 보고 인젝션하는 방법을 byType이라고 합니다.
@Autowired
@Autowired는 인스턴스 변수 앞에 붙이는 것 외에도, 다음과 같이 적당한 메서드 선언 앞에도 붙일 수 있습니다.
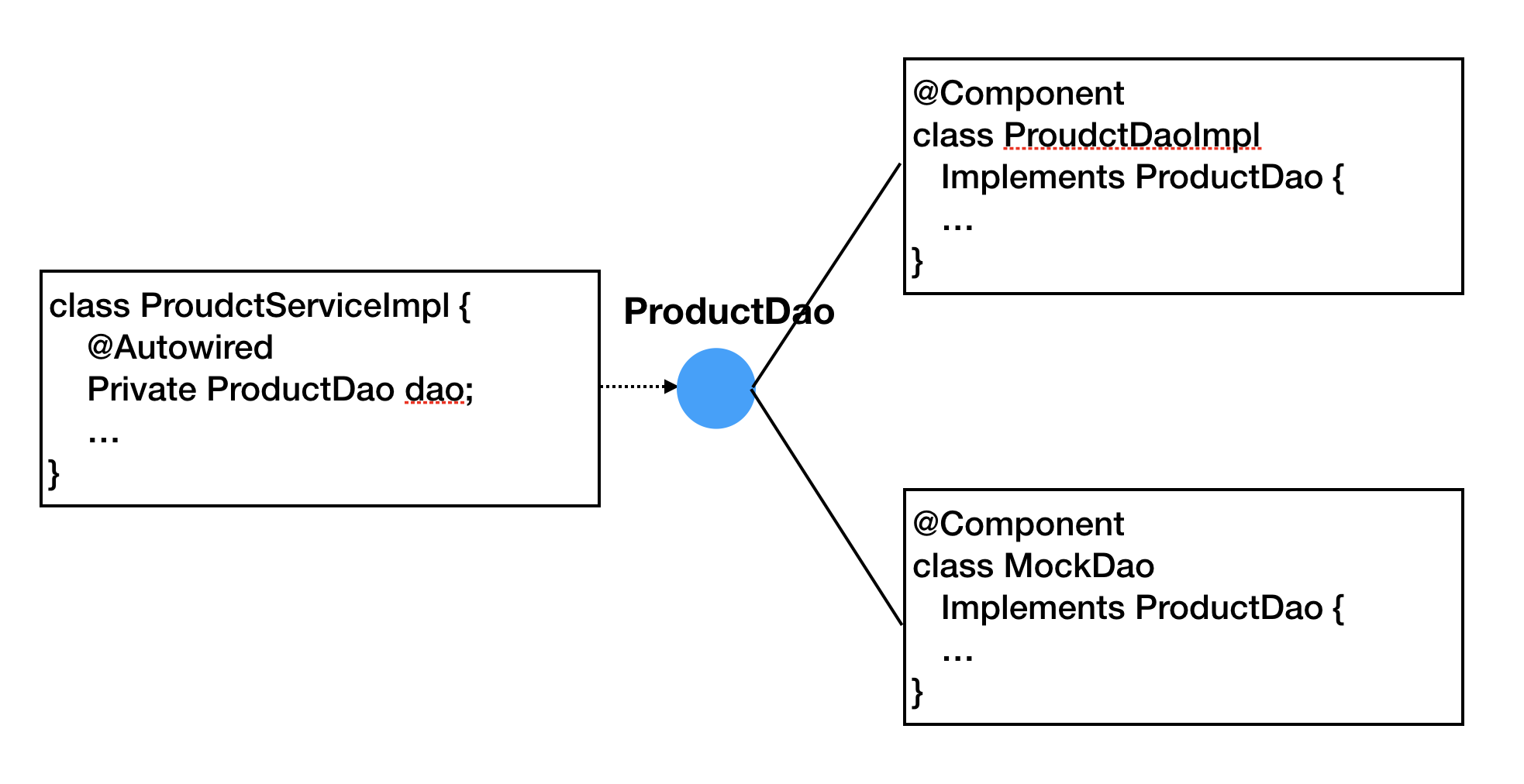
그런데 위의 사진과 같이 인터페이스에 구현 클래스가 2개여서 @Autowired로 인젝션할 수 있는 클래스의 형이 2개 존재한다면 에러가 발생합니다. 인젝션할 수 있는 클래스의 형은 반드시 하나로 해야합니다. 하지만 이래서는 인터페이스의 구현 클래스를 테스트용 클래스 등 다른 클래스로 바꿀 경우에 불편합니다. 그래서 이를 회피하는 세 가지 방법에 대해 알아보겠습니다.
우선할 디폴트 Bean을 설정하는 @Primary를 @Bean이나 @Component에 부여하는 방법 (Bean 정의 파일에서는 )
@Autowired와 병행해서 @Qualifier를 하는 방법 단, 이 경우는 @Component에도 이름을 같이 지정해야 한다. 이렇게 인젝션할 클래스를 형이 아닌 이름으로 찾아주는 방법을 byName이라고 한다. (물론 @Component에 같은 이름이 붙은 클래스가 중복되면 오류가 발생한다.)
Bean 정의 파일인 context:component-scan을 이용하는 방법 (context:component-scan을 어느 정도 크기의 컴포넌트마다 기술해두고, 만약 어떤 컴포넌트를 테스트용으로 바꾸고자 할 때는 그 컴포넌트 부분의 정의만 테스트용 부품을 스캔하게 수정하는 방법이다.)
확장된 @Component
@Component에는 확장된 어노테이션이 있습니다. 웹 애플리케이션 개발에는 @Component를 이용할 것이 아니라 클래스가 어느 레이어에 배치될지 고려해서 배치될 레이어에 있는 @Component 확장 어노테이션을 사용하는 것이 좋습니다. 예를 들어 ProductServiceImpl은 @Component가 아니라 @Service로 바꾸는 편이 좋고, ProductDaoImpl 클래스도 @Component가 아니라 @Repository로 바꾸는 편이 좋습니다.
@Controller : 프레젠테이션 층 스프링 MVC용 어노테이션
@Service : 비즈니스 로직 층 Service용 어노테이션, @Component와 동일
@Repository : 데이터 엑세스 층의 DAO용 어노테이션
@Configuration : Bean 정의를 자바 프로그램에서 실행하는 JavaConfig용 어노테이션
@Component와 함께 사용하는 어노테이션의 하나로 @Scope가 있습니다. @Scope 뒤에 Value 속성을 지정하면 인스턴스화와 소멸을 제어할 수 있습니다. @Scope를 생략하면 해당 클래스는 싱글턴이 됩니다.
스프링 DI 컨테이너에는 인스턴스의 생성과 소멸 타이밍에 호출되는 메서드를 설정할 수 있는 @PosetConstruct와 @PreDestroy라는 2개의 어노테이션이 있습니다.
@PostConstruct : 초기 처리를 하는 메서드 선언. 메서드 이름은 임의로 지정할 수 있다. 단, 메서드 인수 없이 반환형은 void 형으로 해야한다.
@PreDestroy : 종료 처리를 하는 메서드 선언. 메서드 이름은 임의로 지정할 수 있다. 단, 메서드 인수 없이 반환형은 void 형으로 해야한다.
@PostConstruct는 DI 컨테이너에 의해 인스턴스 변수에 무언가 인젝션된 다음에 호출됩니다. 따라서 인젝션 된 값으로 초기 처리를 할 때 사용합니다. (생성자에서도 초기 처리를 할 수 있습니다.) @PreDestroy는 소멸자가 없는 자바에서 종료 처리를 하기 위해 사용합니다.
Javascript를 이용한 Node.js로 서버프로그래밍을 하다가 최근 Java를 이용한 Spring Framework를 사용하게 되면서 JavaEE, Servlet, JSP, Tomcat, MVC, WAS와 같은 용어들을 마주하게 되었습니다. 이번 포스팅을 통해서 Java를 이용한 웹 개발의 히스토리와 여러 용어들을 정리해보고자 합니다.
시작은 JavaEE
기존에는 기업용 서버 소프트웨어 개발이라는 것이 C나 C++을 사용해서 다양한 회사의 미들웨어(middleware) 제품들을 사용해서 개발하는 방식이었습니다. 그러나 이 경우 개발자들은 운영체제와 사용하는 미들웨어 제품에 종속될 수 밖에 없는데, 자바의 플랫폼 독립적 특성을 활용해서 미들웨어에 필요한 공통 API를 제공하면 그런 문제를 해결할 수 있을 것이라는 생각을 했습니다. 그래서 서버 개발에 필요한 기능을 모아서 J2EE라는 표준을 만들었습니다. 그리고 이 J2EE는 버전 5.0 이후로 Java EE로 개칭됩니다.
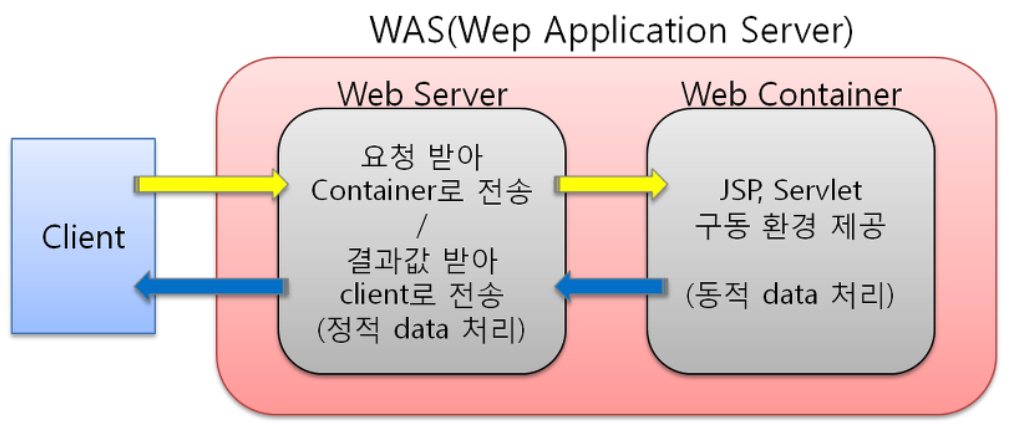
자바 플랫폼, 엔터프라이즈 에디션(Java Platform, Enterprise Edition; Java EE)은 자바를 이용한 서버측 개발을 위한 플랫폼입니다. Java EE 플랫폼은 PC에서 동작하는 표준 플랫폼인 Java SE에 부가하여, 웹 애플리케이션 서버에서 동작하는 장애복구 및 분산 멀티티어를 제공하는 자바 소프트웨어의 기능을 추가한 서버를 위한 플랫폼입니다. 이러한 Java EE 스펙에 따라 제품으로 구현한 것을 웹 애플리케이션 서버 또는 WAS라 부릅니다.
WAS란? 인터넷 상에서 HTTP를 통해 사용자 컴퓨터나 장치에 애플리케이션을 수행해 주는 미들웨어(소프트웨어 엔진)이다. 웹 애플리케이션 서버는 동적 서버 콘텐츠를 수행하는 것으로 일반적인 웹 서버와 구별이 되며, 주로 데이터베이스 서버와 같이 수행이 된다. < 사용자 요청(웹 브라우저) -> 웹 서버 -> WAS(동적 처리) -> 웹 서버 -> 사용자 응답 메세지(웹 브라우저) > 예로, 웹 서버에서 JSP를 요청하면 톰캣에서는 JSP 파일을 서블릿으로 변환하여 컴파일을 수행하고, 서블릿의 수행결과를 웹 서버에서 전달하게 된다.
그렇게 시작된 자바EE는 출발부터 많은 관심을 받았고, 특히 웹 개발을 위해 자바EE 표준에 포함된 **서블릿(Servlet)**과 JSP는 당시 막 유행하던 PHP나 ASP와 함께 CGI를 몰아내며 자바 언어가 인기를 얻는데 한 몫을 담당했습니다.
CGI란? (인용 - http://www.terms.co.kr/CGI.htm) CGI는 웹서버에 있어 사용자의 요구를 응용프로그램에 전달하고 그 결과를 사용자에게 되돌려주기 위한 표준적인 방법이다. 사용자가 하이퍼링크를 클릭 하거나 웹사이트의 주소를 입력함으로써 웹 페이지를 요청하면, 서버는 요청된 페이지를 보내준다. 그러나, 사용자가 웹페이지의 양식에 내용을 기재하여 보냈을 때, 그것은 보통 응용프로그램에 의해 처리될 필요가 있다. 웹 서버는 그 양식 정보를 조그만 응용프로그램에 전달하는데, 이 프로그램은 데이터를 처리하고 필요에 따라 확인 메시지를 보내주기도 한다. 이렇게 서버와 응용 프로그램간에 데이터를 주고받기 위한 방법이나 규약들을 CGI라고 부른다. 이것은 웹의 HTTP 프로토콜의 일부이다. 만약 웹사이트를 만들 때 어떠한 제어를 위해 CGI 프로그램을 사용하기 원하면, HTML 파일 내에 있는 URL 내에 그 프로그램의 이름을 기술하면 된다. 만약 폼을 만들려고 할 때, 이 URL은 FORMS 태그의 일부로서 기술될 수 있는데, 예를 들어 아래와 같이 쓸 수 있을 것이다. 이 태그의 결과로서 mybiz.com에 있는 서버는 입력된 데이터를 저장하기 위해 제어권을 “formprog.pl”이라는 CGI 프로그램에 넘기고, 확인 메시지를 되돌려준다 (여기서 .pl은 Perl로 작성된 프로그램이라는 것을 가리키지만, CGI는 다른 언어로도 작성될 수 있다).
자바EE의 핵심은 EJB(Enterprise Java Beans)라는 기술이었습니다. EJB는 자바EE가 대체하는 미들웨어에서 구동되던 기업의 핵심 서비스를 만들기 위한 분산처리 및 트랜잭션, 보안 등을 지원하는 컴포넌트 모델을 제공하는 기술입니다. 이러한 EJB는 주목을 받으며 널리 쓰이게 되었지만 시간이 지남에 따라 몇 가지 심각한 문제들로 비판을 받게 되었고, 이러한 문제점을 개선하기 위해 Spring Framework가 처음 개발되었습니다. 특히 고가의 풀스택 자바EE 서버가 아닌 톰캣과 같은 일반 서블릿 컨테이너에서도 구동된다는 것이 큰 강점으로 작용했습니다.
다시 말하면, 이는 Spring을 통해 비싼 자바EE 서버를 구매하지 않아도 EJB보다 훨씬 간편한 방식으로 EJB가 제공하던 선언적 트랜잭션 및 보안 처리, 분산 환경 지원 등 주요 기능을 모두 사용할 수 있게 되었음을 뜻하며, 무엇보다 이제는 더 이상 각 자바EE 서버 제품에 특화된 설정을 따로 공부하거나 서버 제품을 바꿀 때마다 포팅 작업이 필요없이 Spring만 이용하면 톰캣이든 레진(Resin)이든 기존의 풀스택 자바EE 서버이든 관계없이 간단하게 배포가 가능하다는 뜻입니다.
Servlet
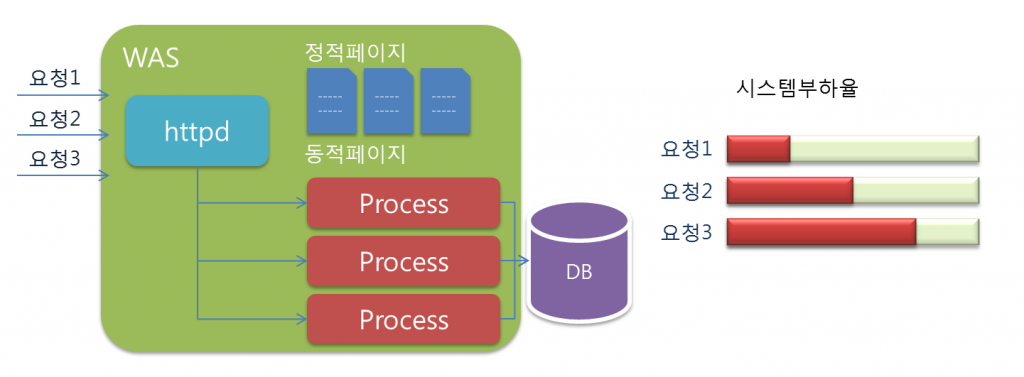
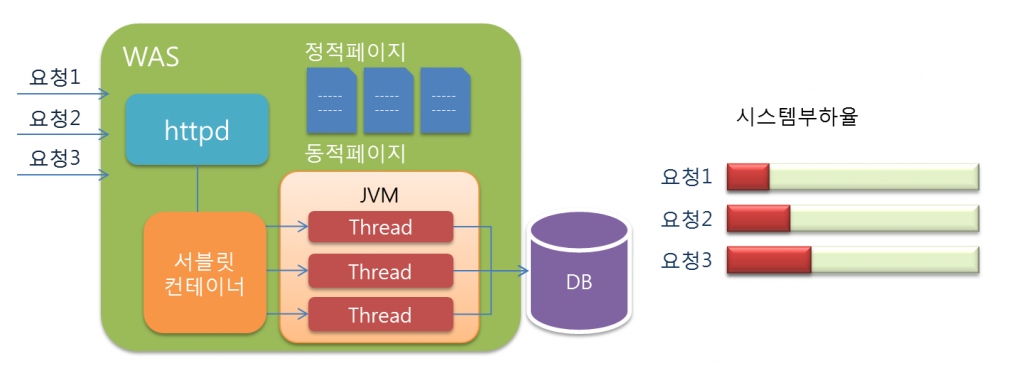
Servlet은 Java 기반의 확장된 CGI로서 동일하게 동적인 웹 애플리케이션을 작성할 수 있는 기술입니다. CGI와 비슷하게 클라이언트의 요청을 받아 해당하는 프로그램을 실행시켜주지만 CGI와는 조금 다른 동작 형태를 보입니다. Servlet은 CGI와 달리 효율적입니다. CGI의 멀티 프로세스 동작이 아닌 멀티 스레드 방식의 동작으로 서블릿이 생성되면 서버가 종료되지 않는 이상 메모리로 남게 됩니다. 따라서 이후에 오는 요청에 대해서는 서블릿을 새로 생성하지 않고 동작을 이어갈 수 있기 때문에 시스템 자원(메모리)에서 큰 이점이 있습니다. 그로인해 Servlet은 CGI 보다 적은 시스템 자원으로 많은 요청을 처리할 수 있는 구조를 가지고 있습니다.
멀티 프로세스 동작 방식
클라이언트의 요청을 받아 웹 애플리케이션을 직접 실행하는 구조로 각각의 요청에 대해 프로세스를 생성하고 응답한 뒤 종료하는 형태이다. 이는 각각의 많은 요청이 들어오는 경우 프로세스를 계속 생성하므로(프로세스를 생성하는 작업은 필요이상의 부담을 주게 된다) 시스템 부하가 커지게 되 안정적인 서비스가 힘들다.
멀티 스레드 동작 방식
클라이언트의 요청을 받으면 웹 애플리케이션을 거치지 않고 웹 컨테이너로 요청이 전달된다. 그리고 웹 컨테이너가 요청을 처리할 스레드를 생성하는 형태이다. 멀티스레드 방식은 최초 요청 시 웹 애플리케이션을 실행한 후 종료하지 않은 상태에서 같은 요청이 여러 번 오는 경우, 실행되고 있는 웹 애플리케이션의 스레드를 생성해 요청을 처리하는 방법이다. CGI에서 사용하는 멀티프로세스 방식보다 시스템 부하를 줄여 안정적인 서비스를 제공할 수 있다.
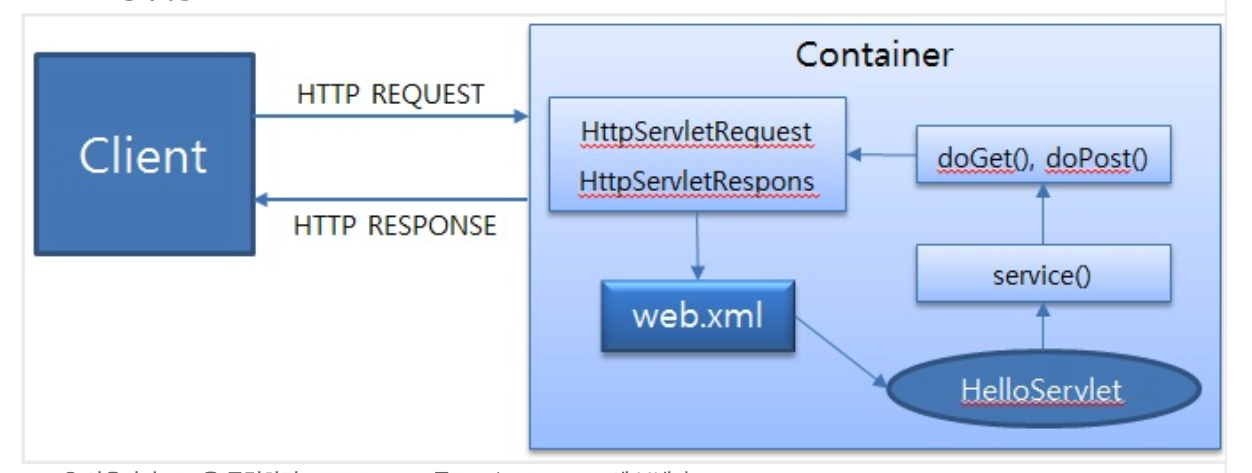
컨테이너란? (인용 - 컨테이너란?? 무엇일까?) 컨테이너는 Servlet을 실행하고 관리하는 역할을 합니다. 개발자가 해야하는 역할을 대신 함으로써, 개발자가 해야하는 일을 대폭 줄여줍니다. 컨테이너는 개발자가 웹서버와 통신하기 위하여 소켓을 생성하고, 특정 포트에 리스닝하고, 스트림을 생성하는 등의 복잡한 일들을 대신합니다. 또한 Servlet의 생성부터 소멸까지 일련의 과정을 관리하며, 요청이 들어올 때마다 새로운 자바 스레드를 하나 생성합니다. 톰캣을 예로 들면 아파치와 같은 웹서버가 사용자로부터 Servlet에 대한 요청을 받으면 이것을 바로 호출하는 것이 아니라 컨테이너에게 이 요청을 넘겨주고 이 컨테이너는 request와 response 객체를 생성하고 해당하는 Servlet의 스레드를 생성하여 앞의 두 객체를 인자로 넘깁니다. 스레드 생성 후 이 스레드의 service() 메소드를 호출하고 처음에 사용자로부터 요청받은 방식이 get인지 post인지에 따라 doGet()과 doPost() 메소드 중 선택 생성합니다. 만약 doPost가 생성되었다고 가정하면, 이 doPost() 메소드는 독 페이지를 생성하고, 이것을 처음 받은 response 객체에 실어서 컨테이너에게 보냅니다. 컨테이너는 이 객체를 HTTPResponse로 변환하여 클라이언트에게 보냅니다. 그런 다음 처음에 생성한 객체 Request와 Response를 소멸시킵니다.
Servlet 동작 방식
사용자가 URL을 클릭하면 HTTP Request를 Servlet Container에 보낸다.
Servlet Container는 HttpServletRequest, HttpServletResponse 두 객체를 생성한다.
사용자가 요청한 URL을 분석하여 어느 서블릿에 대한 요청인지 찾는다. (DD를 참조하여 분석)
컨테이너는 서블릿 service() 메소드를 호출하며, POST, GET여부에 따라 doGet() 또는 doPost()가 호출된다.
doGet() or doPost() 메소드는 동적인 페이지를 생성한 후 HttpServletResponse객체에 응답을 보낸다.
응답이 완료되면 HttpServletRequest, HttpServletResponse 두 객체를 소멸시킨다.
DD (배포서술자, Deployment Descriptor) = web.xml
Servlet, Error Page, Listener, Fillter, 보안 설정등 Web Application의 설정 파일이다.
URL과 실제 서블릿의 매핑 정보도 담고 있다.
하나의 웹 어플리케이션에 하나만 존재한다.
보통 Web Document Root 디렉토리에 WEB-INF 폴더 아래 web.xml 파일로 존재한다.
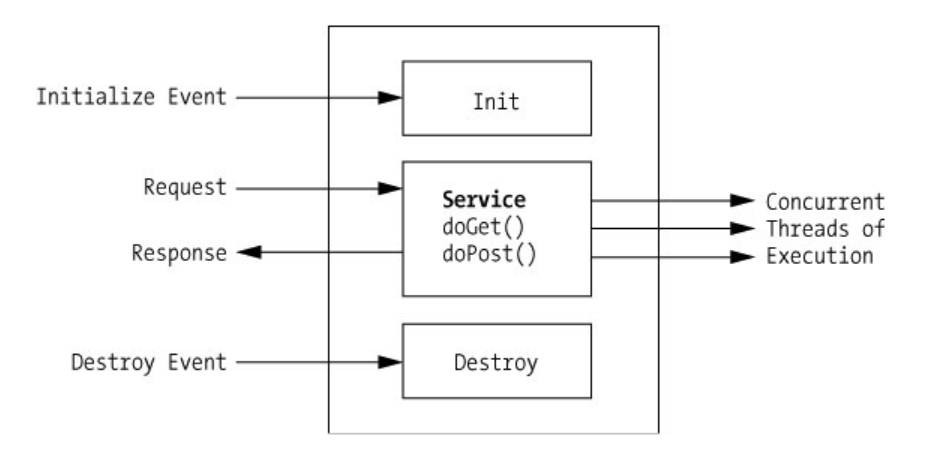
한마디로 정리하자면 톰캣과 같은 WAS 가 java 파일을 컴파일해서 Class로 만들고 메모리에 올려 Servlet 객체를 만들게 되고 이 Servlet 객체는 doPost, doGet을 통해 요청에 응답합니다. 초기화 과정을 더 자세히 보면 다음과 같습니다. init, Service, destory 이런 콜백이 각 시점에 불리는걸 볼 수 있습니다. init은 Servlet이 메모리에 로드 될때 실행됩니다. destory는 마찬가지로 언로드되기 전에 수행되는 콜백입니다. service 메소드는 HTTP Method 타입에 따라 doGet 혹은 doPost를 호출합니다. 기억해야 할 점은, 초기화된 Servlet이 클라이언트의 요청이 있을 때 마다 Thread를 생성해서 병렬적으로 service를 수행한다는 것. 서블릿 객체는 여러개 생성되지 않습니다.
Servlet 예시 코드
다음은 Servlet의 예시 코드입니다. 자바 코드 안에 HTML을 넣기 굉장히 불편합니다.
HTML을 넣기 불편한 구조로 인해 JSP가 등장하게 됬습니다. Servlet의 확장된 기술로 브라우저에 표현하기 위한 HTML 코드에 JAVA 코드를 혼용하여 사용할 수 있게 합니다. 이로써 디자인과 로직 개발을 분업화시켜 효율적인 코드를 생산해 낼 수 있게됩니다.
JSP 동작 방식
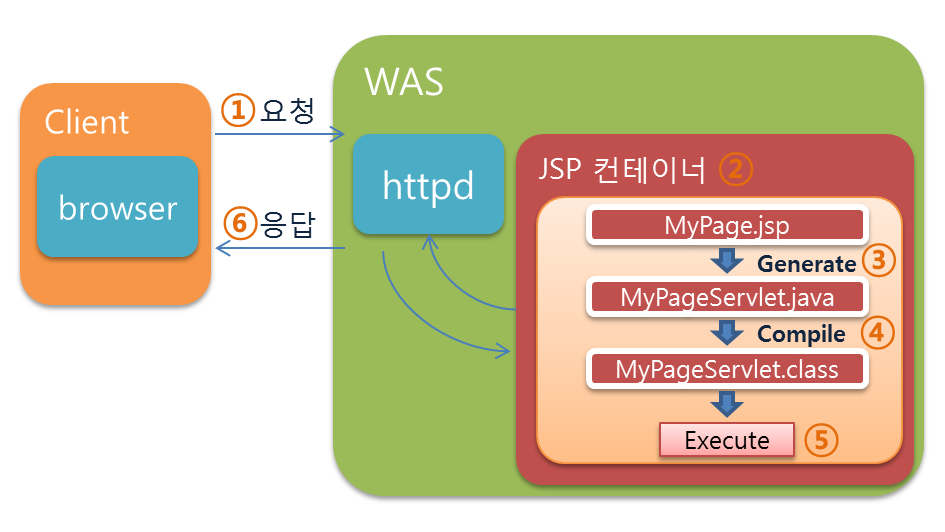
JSP 라는 새로운 개발 방법이 나왔지만, 사실 이 JSP 도 내부적으로는 아래 그림 처럼 Tomcat이 Servlet으로 바꾸어서 돌립니다.
클라이언트가 브라우저를 통해 서버에 HTTP 프로토콜로 요청한다.
서버는 컨테이너에게 처리를 요청하고 컨테이너는 해당 파일을 찾는다.
찾은 파일을 서블릿으로 변환한다. 만약 이미 변환 되어있는 파일이 있다면 그 파일을 바로 실행⑤한다.
서블릿 파일을 실행가능한 class파일로 컴파일 한다.
컴파일된 class파일을 메모리에 적재하고 실행한 결과를 웹서버에 넘겨준다.
웹서버는 브라우저가 인식할수 있는 정적페이지를 구성하여 클라이언트에게 응답한다.
JSP 예시 코드
HTML 내부에 Java 코드가 있어 HTML 코드를 작성하기 쉽습니다. 그러나 로직과 디자인이 한 파일내에 섞여있어 유지보수가 어렵습니다. 하나가 편한대신, 다른 불편한 점들이 생긴것 입니다. 그래서 이를 해결하기 위해 MVC Model이 등장하였습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
<%@pageimport="java.util.Calendar" %> <%@ page contentType="text/html; charset=UTF-8"%> <% String str=String.format("%tF",Calendar.getInstance()); %> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN""http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>Insert title here</title> </head> <body> 오늘은 <%=str%><br/> </body> </html>
MVC Model 1
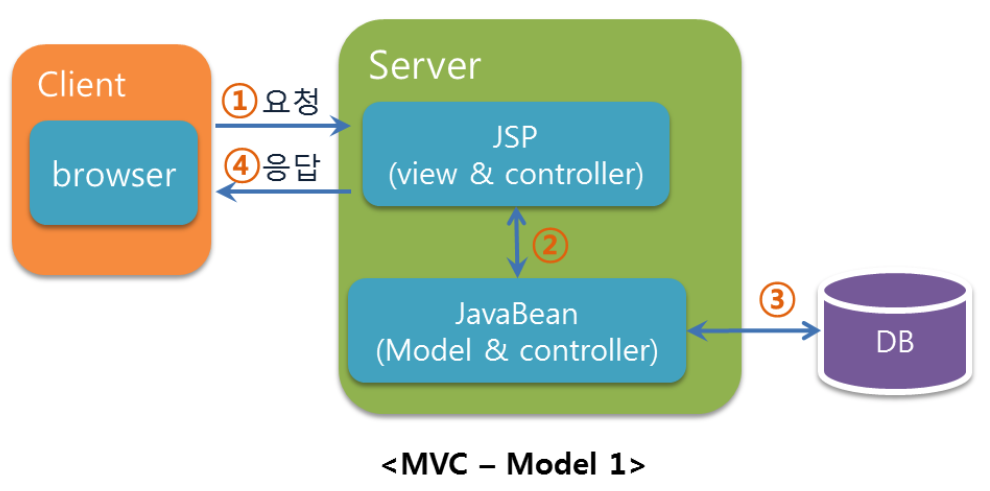
Model1 방식은 사용자로부터 요청을 JSP가 받아(더 정확히는 JSP 에서 사용자가 요청을 합니다.) Java Bean(DTO, DAO)을 호출해 처리합니다. 이 방식은 개발 속도가 빠르고 배우기 쉽지만 프레젠테이션 로직과 비즈니스 로직이 혼재하기 때문에 JSP 코드가 복잡해져 유지 보수가 어려워진다는 단점이 있습니다.
MVC Model 2
단순히 JSP만 사용하거나, Servlet만 사용하는 것이 아니라 두개의 장단점을 모두 취해 View 는 JSP로, Controller는 Servlet을 사용한 것이 Model2 입니다. 보여지는 부분은 HTML이 중심이 되는 JSP, 다른 자바 클래스에게 데이터를 넘겨주는 부분은 Java 코드가 중심이 되는 Servlet이 담당하게 됩니다. 그리고 Model 영역 에서는 DTO, DAO를 통해 Mysql 과 같은 데이터베이스에 접근합니다.
Spring은 J2EE나 JEE로 알려진 자바 엔터프라이즈 에디션을 경량화하기 위해 시작되었다. 스프링은 무거운 엔터프라이즈 자바 빈(EJB)로 컴포넌트를 개발하지 않았다. 그 대신 의존성 주입(DI)과 관점 지향 프로그래밍(AOP)을 활용해서 EJB의 기능을 평범한 자바 객체(POJO)로 구현할 수 있게 하여 간단하게 엔터프라이즈 자바 개발에 접근할 수 있도록 했다. 컴포넌트 코드 작성은 가벼워졌지만, Spring Framework 기반의 웹 프로젝트를 진행하게되면 최초 개발 구성(설정)하는 부분에 많은 시간이 소모되었다. 결국 애플리케이션 로직 작성이 아닌 프로젝트 구성 작업에 쓰는 시간이 많이 Gk소모되는 것이다. SpringBoot는 Spring의 복잡한 설정을 최소화하여 빠르게 프로젝트 개발을 시작할 수 있게 해준다. 이 포스팅에서는 IntelliJ에서 SpringBoot로 웹 프로젝트를 시작하는 방법을 소개하며 SpringBoot의 특징을 소개한다.
IntelliJ에서 SpringBoot 프로젝트 생성
Spring Initializr는 SpringBoot 프로젝트 구조를 만드는 웹 애플리케이션이다. 기본적인 프로젝트 구조와 코드를 빌드하는 데 필요한 maven이나 gradle 빌드 명세를 만들어준다. 그러므로 Spring Initializr가 만든 프젝트에 애플리케이션 코드만 작성하면 된다. Spring Initializr는 웹 기반 인터페이스, Spring Tool Suite(STS), IntelliJ IDE, SpringBoot CLI로 사용할 수 있다. 그 중 IntelliJ를 사용해 프로젝트를 생성해보자.
IntelliJ를 시작하여 Create New Project를 선택하고 새로운 프로젝트 다이얼로그를 연다. New Project 다이얼로그에서 Spring Initializr 프로젝트를 선택하고 자바 SDK를 설정한 후 Next 버튼을 누른다.
두 번째 화면에서는 프로젝트 이름, 빌드할 때 maven과 gradle 중 어느 것을 사용할지, 자바 버전 등 프로젝트의 기본적인 사항을 물어본다. 프로젝트 정보를 입력하고 Next 버튼을 누른다.
세 번째 화면에서는 프로젝트에서 필요한 종류의 의존성을 추가한다. Web, Thymeleaf, JPA, H2를 선택한 후 Next 버튼을 누른다.
다음으로 프로젝트가 저장되는 경로를 지정한다.
Gradle 설정을 지정한다.
코드 작성
도메인 정의 (Diary.java)
src/main/java/com.example.demo/Diary.java 파일을 작성한다. 일기를 나타내는 엔티티 정의한다. 간단하게 id, title, ocntent 필드를 갖고 있는 POJO 객체로 만든다. @Entity 어노테이션을 붙여 클래스를 JPA 엔티티로 지정했고, id 필드에는 @Id와 @GeneratedValue 어노테이션을 붙여 엔티티의 유일성을 식별하고 자동으로 값을 제공하는 필드로 지정했다.
src/main/java/com.example.demo/DiaryListRepository.java 파일을 작성한다. 데이터베이스에 Diary 객체를 저장할 수 있는 레파지토리를 선언한다. 스프링 JPA를 사용하므로 스프링 데이터 JAP의 인터페이스를 상속하여 인터페이스를 만든다. JpaRepository 인터페이스는 타입 매개변수 두 개를 받는다. 첫 번째는 레파지토리가 사용할 도메인 타입, 두번 째는 클래스의 ID 프로퍼티 타입이다. 지정한 유저의 이름으로 도서 목록을 검색하는 findByUser() 메서드를 추가했다. DiaryListRepository는 JpaRepository 인터페이스를 상속받아 18개의 메서드를 구현해야 한다. 그러나 스프링 데이터는 레파지토리를 인터페이스로 정의만 해도 잘 작동할 수 있게 런타임 시에 자동으로 구현해준다.
일기 목록 애플리케이션의 스프링 MVC 컨트롤러 (DiaryListController.java)
src/main/java/com.example.demo/DiaryListController.java 파일을 작성한다. 클래스에 @Controller 어노테이션을 추가하면, 자동 컴포넌트 검색으로 DiaryListController를 발견해 자동으로 스프링 애플리케이션 컨텍스트에 빈으로 등록한다. 요청을 처리하는 모든 메서드를 기본 URL 경로인 /로 매핑하기 위해 @RequestMapping 어노테이션을 붙였다. usersDiarys() 메서드는 “diaryList”를 논리적 뷰 이름으로 반환한다. 그러므로 이 뷰도 만들어야 한다.
SpringBoot를 이용해 간단한 애플리케이션을 만들어 보았다. 이 애플리케이션을 바탕으로 SpringBoot의 특징을 알아보자.
스타터 의존성
처음 프로젝트를 생성하며 Spring Initializr에서 필요한 Dependencies들(Web, Thymeleaf, JPA, H2)을 쉽게 추가했었다. 만약 이런 스타터 의존성이 없었다면, 애플리케이션을 개발하기도 전에 build.gradle 또는 pom.xml에서 필요한 Dependencies를 직접 추가해야했을 것이다. (또햔, 여러 의존성들 사이에 잘 호환이 되는지도 확인해야 한다.)
Spring Initializr에서 체크했던 의존성들이 gradle에 추가되어 있는것을 볼 수 있다. 또한 각 라이브러리의 버전이 명시되어 있지 않은데, 이는 SpringBoot 버전에 따라 스타터 의존성 버전이 결정되기 때문이다. 즉, 사용자는 스타터 의존성만 지정하면 어떤 라이브러리와 어떤 버전을 사용해야 하는지 걱정없이 구성에서 자유로워질 수 있는 것이다.
자동 구성
SpringBoot Auto-configuration은 스프링 구성을 적용해야 할지 말지를 결정하는 요인들을 판단하는 런타임 과정이다. 애플리케이션이 시작될 때마다 스프링 부트는 보안, 통합, 데이터 저장, 웹 개발 영역 등을 커버하기 위해 자도성에서 대략 200가지 정도 결정을 내린다. 이 자동 구성 덕분에 필요한 상황이 아니면 명시적으로 구성을 작성하지 않아도 된다.
Retrofit은 기본적인 네트워크 타임아웃 시간 설정을 사용하고 있습니다. 그러나 여러 상황으로 인해 기본적으로 설정된 타임아웃 시간을 변경할 필요가 생기기도 합니다. 이번 포스팅에서는 3가지의 네트워크 타임아웃 시간 설정에 대해 알아보고 변경해보겠습니다.
타임아웃 시간 설정
Retrofit에서는 기본적으로 다음의 3가지 타임아웃 시간 설정 값을 갖고 있습니다.
Connection timeout : 10초
Read timeout : 10초
Write timeout : 10초
Connection Timeout
요청을 시작한 후 서버와의 TCP handshake가 완료되기까지 지속되는 시간이다. 즉, Retrofit이 설정된 연결 시간 제한 내에서 서버에 연결할 수없는 경우 해당 요청을 실패한 것으로 계산한다. 따라서 사용자의 인터넷 연결 상태가 좋지 않을때 기본 시간 제한인 10초를 더 높은 값으로 설정하면 좋다.
Read Timeout
읽기 시간 초과는 연결이 설정되면 모든 바이트가 전송되는 속도를 감시한다. 서버로부터의 응답까지의 시간이 읽기 시간 초과보다 크면 요청이 실패로 계산된다. LongPolling을 위해 변경해 주어야 하는 설정값이다.
Write Timeout
쓰기 타임 아웃은 읽기 타임 아웃의 반대 방향이다. 얼마나 빨리 서버에 바이트를 보낼 수 있는지 확인한다.
신입사원 프로젝트로 간만에 안드로이드 개발을 하게됐습니다. 서버와 통신하기위해 Square에서 만든 Retrofit 라이브러리를 사용했는데, 기존에 사용하던 버전(1.x)과 변경된 부분이 많아 새롭게 사용법을 알아보고자 합니다. Retrofit 테스트는 API 테스트 사이트를 통해서 Fake data를 가져오는 실습을 해보겠습니다. 해당 글의 대부분은 Retrofit 2.0 Example을 참고했습니다.
@SerializedName("page") public Integer page; @SerializedName("per_page") public Integer perPage; @SerializedName("total") public Integer total; @SerializedName("total_pages") public Integer totalPages; @SerializedName("data") public List<Datum> data = null;
publicclassDatum{
@SerializedName("id") public Integer id; @SerializedName("name") public String name; @SerializedName("year") public Integer year; @SerializedName("pantone_value") public String pantoneValue;
} }
@SerializedName 어노테이션은 JSON 응답에서 각각의 필드를 구분하기 위해 사용합니다.
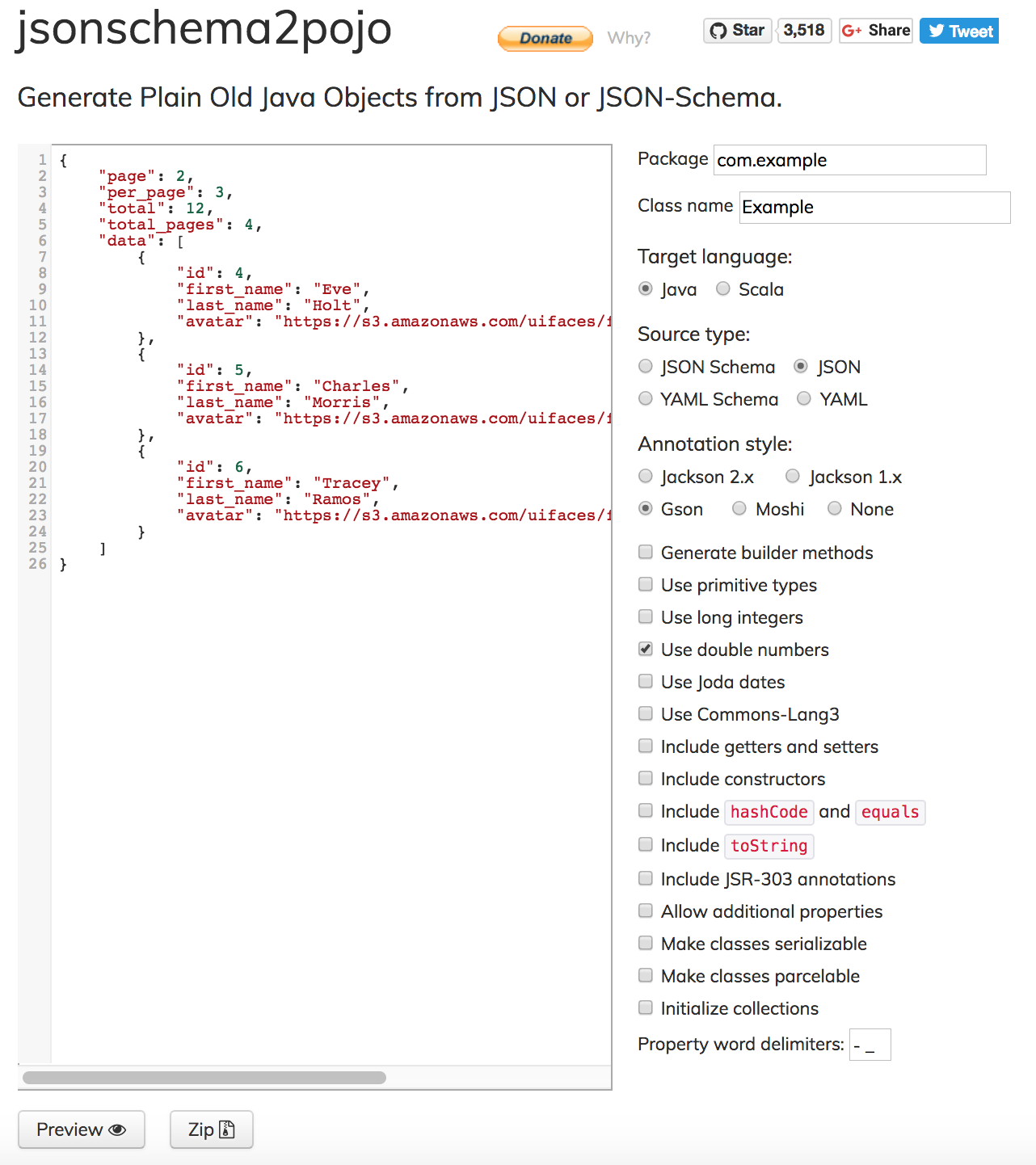
# Tip)jsonschema2pojo 에서 json 응답의 구조를 바탕으로 해당 응답에 대한 POJO 클래스를 쉽게 만들 수 있습니다.
@SerializedName("name") public String name; @SerializedName("job") public String job; @SerializedName("id") public String id; @SerializedName("createdAt") public String createdAt;
@SerializedName("page") public Integer page; @SerializedName("per_page") public Integer perPage; @SerializedName("total") public Integer total; @SerializedName("total_pages") public Integer totalPages; @SerializedName("data") public List<Datum> data = new ArrayList();
publicclassDatum{
@SerializedName("id") public Integer id; @SerializedName("first_name") public String first_name; @SerializedName("last_name") public String last_name; @SerializedName("avatar") public String avatar;
@SerializedName("name") public String name; @SerializedName("job") public String job; @SerializedName("id") public String id; @SerializedName("createdAt") public String createdAt; }
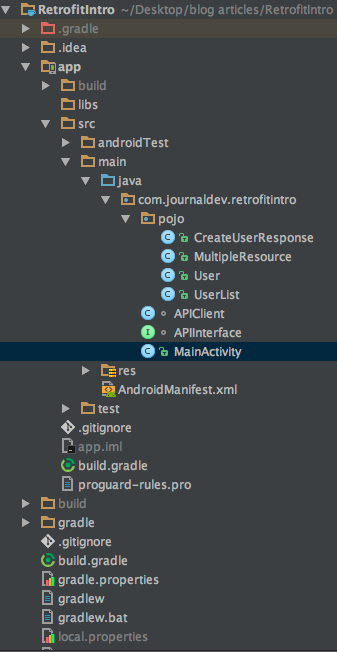
MainActivity.java
**MainActivity.java**는 Interface 클래스에 정의된 각각의 API를 호출하고 그 결과를 Toast와 TextView를 통해 표시하고 있습니다.
/** Create new user **/ User user = new User("morpheus", "leader"); Call<User> call1 = apiInterface.createUser(user); call1.enqueue(new Callback<User>() { @Override publicvoidonResponse(Call<User> call, Response<User> response){ User user1 = response.body();
apiInterface = APIClient.getClient().create(APIInterface.class);는 APIClient를 인스턴스화 하기위해 사용됩니다. API 응답에 Model 클래스를 매핑하기 위해서는 다음과 같이 사용합니다. MultipleResource resource = response.body();
안드로이드에서 <네이버 아이디로 로그인> 기능을 구현하며 OAuth 2.0에 대해 알아보고, 라이브러리를 적용하는 방법에 대해 알아보겠습니다.
OAuth 2.0
OAuth는 **인증(Authentication)과 허가(Authorization)**을 위한 표준 프로토콜로, 사용자가 Facebook이나 트위터 같은 인터넷 서비스의 기능을 다른 애플리케이션(데스크톱, 웹, 모바일 등)에서도 사용할 수 있게 한 것입니다.
Facebook이나 트위터의 기능을 이용하기 위해 사용자가 반드시 Facebook이나 트위터에 로그인해야 하는 것이 아니라, 별도의 인증 절차를 거치면 다른 서비스에서 Facebook과 트위터의 기능을 이용할 수 있게 됩니다. 이런 방식은 Facebook이나 트위터 같은 서비스 제공자뿐만 아니라 사용자와 여러 인터넷 서비스 업체 모두에 이익이 되는 생태계를 구축하는데 기여했습니다. 이 방식에서 사용하는 **인증 절차가 OAuth**입니다.
OAuth를 이용하면 이 인증을 공유하는 애플리케이션끼리는 별도의 인증이 필요없습니다. 따라서 여러 애플리케이션을 통합하여 사용하는 것이 가능하게 됩니다.
OAuth 2.0은 authorization(허가, 승인)을 위한 산업 표준 프로토콜입니다. OAuth 2.0 전에 OAuth 1.0이 만들어져 사용되었지만 웹, 데스크탑, 모바일 등의 어플리케이션의 authorization flow(권한 흐름)을 보다 단순화 하는데 초점이 맞춰졌습니다. (OAuth 1.0에서는 Acess Token을 받으면 계속 사용이 가능했습니다. 그러나 OAuth 2.0에서는 보안 강화를 위해 Access Token의 Life-time을 지정할 수 있게됐고, Life-time이 만료되면 Refresh Token을 통해 Access Token을 재발급을 받아야 합니다.)
주의사항
로그인과 OAuth는 반드시 분리해서 이해해야 합니다. 아래의 예시를 통해 그 이유를 생각해봅시다.
사원증을 이용해 출입할 수 있는 회사를 생각해 보자. 그런데 외부 손님이 그 회사에 방문할 일이 있다. 회사 사원이 건물에 출입하는 것이 로그인이라면 OAuth는 방문증을 수령한 후 회사에 출입하는 것에 비유할 수 있다. 방문증이란 사전에 정해진 곳만 다닐 수 있도록 하는 것이니, ‘방문증’을 가진 사람이 출입할 수 있는 곳과 ‘사원증’을 가진 사람이 출입할 수 있는 곳은 다르다. 역시 직접 서비스에 로그인한 사용자와 OAuth를 이용해 권한을 인증받은 사용자는 할 수 있는 일이 다르다.
구성요소
사용자(Resource Owner) : Service Provider에 계정을 가지고 있으면서, Client를 이용하려는 사용자
소비자(Client) : OAuth 인증을 사용해 Service Provider의 기능을 사용하려는 애플리케이션이나 웹 서비스
API 서버(Resource Server) : OAuth를 사용하는 Open API를 제공하는 서비스
권한 (Authroization Server) : OAuth 인증 서버
접근 토큰(Access Token) : 인증 후 Client가 Resource Server의 자원에 접근하기 위한 키를 포함한 값
갱신 토큰(Refresh Token) : 유효기간이 지난 Access Token을 갱신하기 위해 사용되는 값
인증과정
네이버 아이디로 로그인
<네이버 아이디로 로그인>은 OAuth 2.0 기반의 사용자 인증 기능을 제공해 네이버가 아닌 다른 서비스에서 네이버의 사용자 인증 기능을 이용할 수 있게 하는 서비스입니다. 별도의 아이디나 비밀번호를 기억할 필요 없이 네이버 아이디로 간편하고 안전하게 서비스에 로그인할 수 있어, 가입이 귀찮거나 가입한 계정이 생각나지 않아 서비스를 이탈하는 사용자를 잡을 수 있습니다.
이에 서버에서 **In-App Purchase Validation(앱내 구매 유효성 검사)**을 하는 코드를 추가했고 위의 문제를 해결할 수 있었습니다. 이번 포스팅에서는 In-App Purchase Validation에 대해서 알아보겠습니다. (In-App 결제 구현에 대한 내용은 다루지 않습니다!)
어떤 문제가 발생했는가?
어느날 이상한일이 벌어졌다. 분명 Admin을 통해 앱에서 결제한 내용을 확인했을때는 상당한 내역이 있었는데, Google Play Console의 주문 관리를 통해 확인했을 때는 결제 내역이 없는 것이다.
결제 관련된 부분에서 버그가 발생했기에 무척이나 마음이 심란했다. 반복되는 테스트에서도 재현할 수 없는 현상에 라이브 채팅을 통해 Google에 문의하였지만 돌아오는 답변은 사용자의 결제 관련 설정(예를들면 카드)이 잘못되어 있을 것이라는 말뿐, 정확한 해결 방법을 알려주지 않았다.
그러던 도중 결제 관련 DB를 살펴보다가 이상한 부분을 발견했다.
**한명의 사람이 말도 안되는 짧은 시간에 한 품목을 여러변 결제한 것이다. 그리고 이 결제 관련 내용은 Google Play Console의 주문 관리에서도 확인이 불가능했다. (기록이 남지 않았다.) **
결국 글의 도입부에서 말씀드렸던 것처럼 결제 해킹 문제임을 알게되었고 In-App Purchase Validation에 대해 알아보게 되었습니다.
Subscriptions and In-App Purchases API
Google에서는 **Subscriptions and In-App Purchases API**를 제공하고 있습니다. (전에는 이 API를 “Purchase Status API” 라고 불렀습니다.)
Document를 참고하면 해당 API를 인앱 상품과 구독으로 구성된 앱의 카탈로그를 관리할 수 있으며, 개별 구매에 대한 정보, 구매와 구독의 만료 확인 등, 여러 가지 용도로 사용할 수 있음을 알 수 있습니다.
따라서 실제 결제가 이루어졌고, Google Play Console의 주문 관리에 그 내역이 있는지 확인이 가능한 것입니다. 해당 API는 Google Play Developer API로서 허용되는 사용 할당량이 매일 200,000개의 요청으로 제한됩니다. 이 정도면 충분한 구독, 결제 유효성 검사 요구를 충족시킬 수 있으며, 만약 더 많은 요청이 필요하다면 Google Developer Console에서 요청할 수 있다고 합니다.
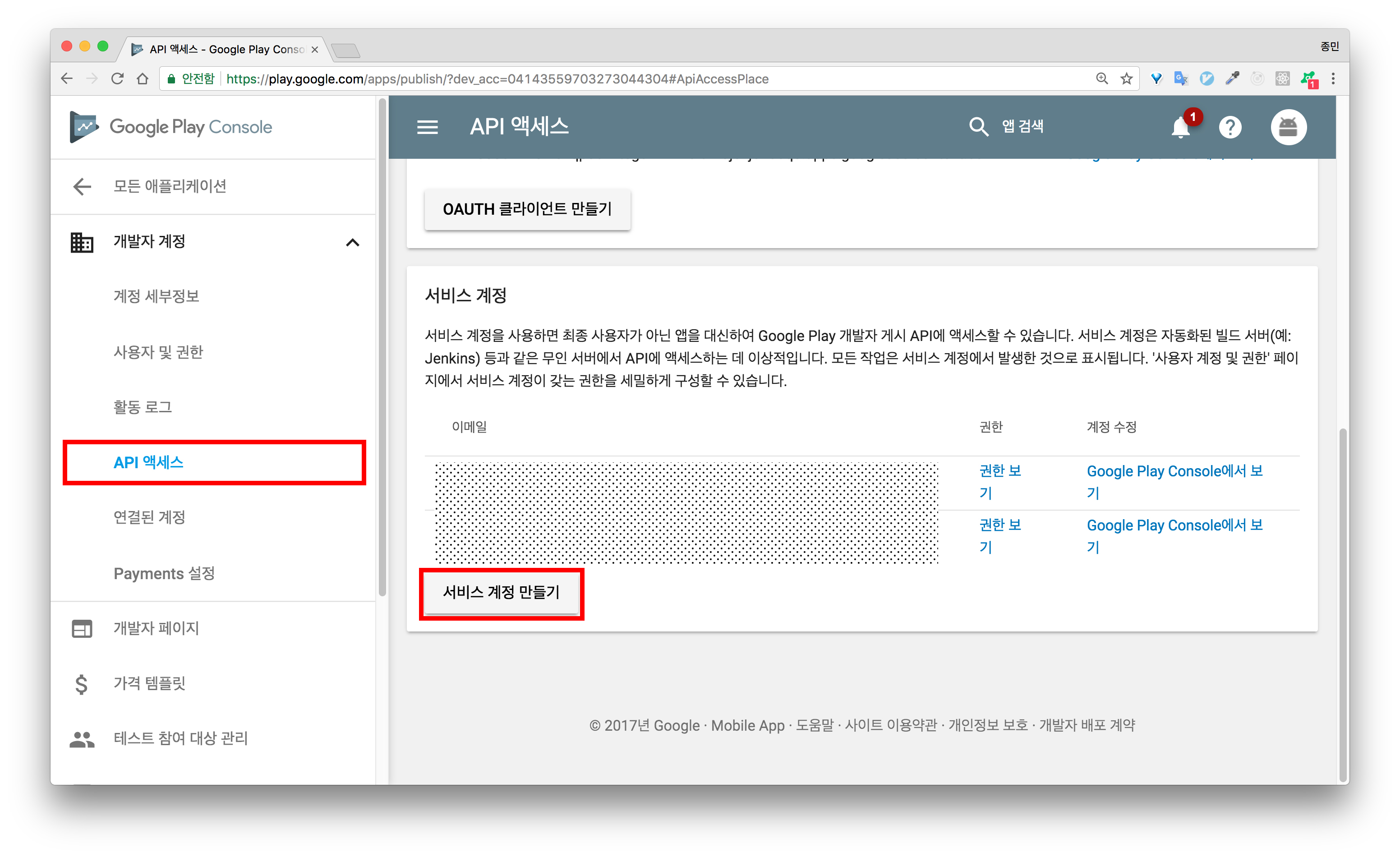
API 사용을 위한 서비스 계정 연결
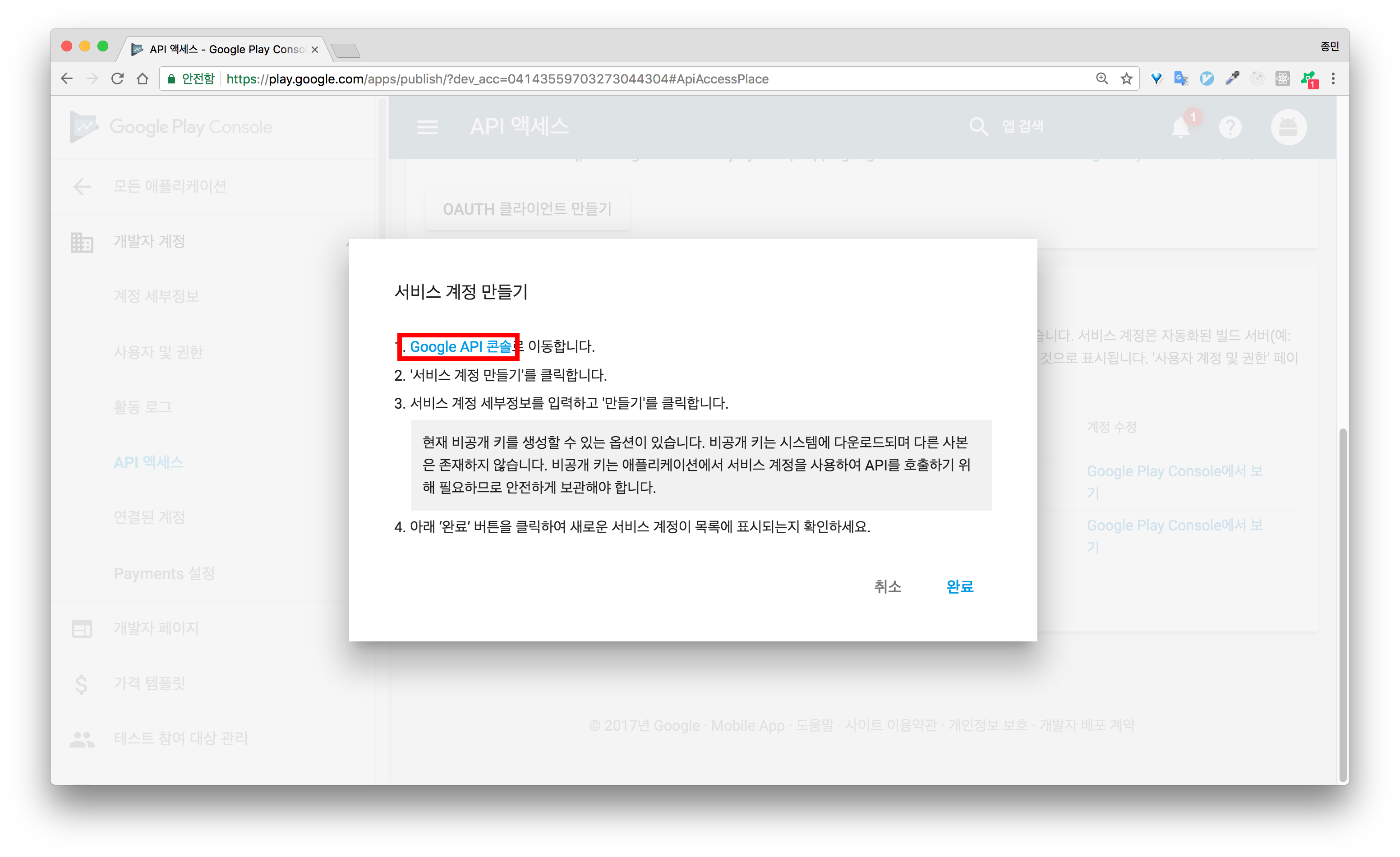
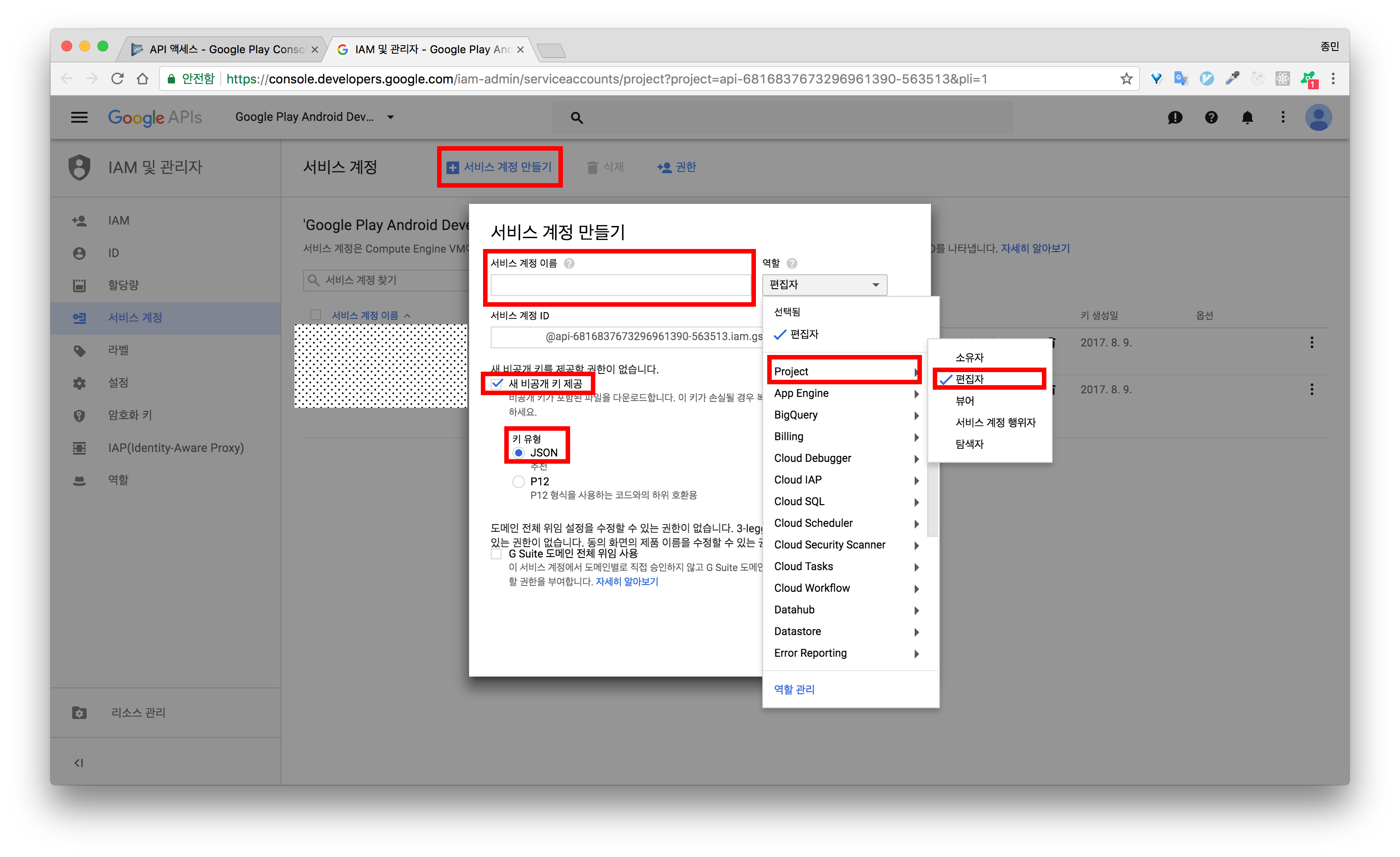
API를 사용하기 위해서는 Google Developer Console에서 서비스 계정을 생성한 후 API 엑세스 권한을 부여해주어야 합니다. 몇가지 단계를 거쳐야 하는데 같이 해보겠습니다.
6.서비스 계정을 생성하면 자동으로 .json 파일이 다운로드 됩니다. .json 파일에는 API 호출을 위한 인증 정보가 포함되어 있습니다. 관리 및 백업이 필요합니다.
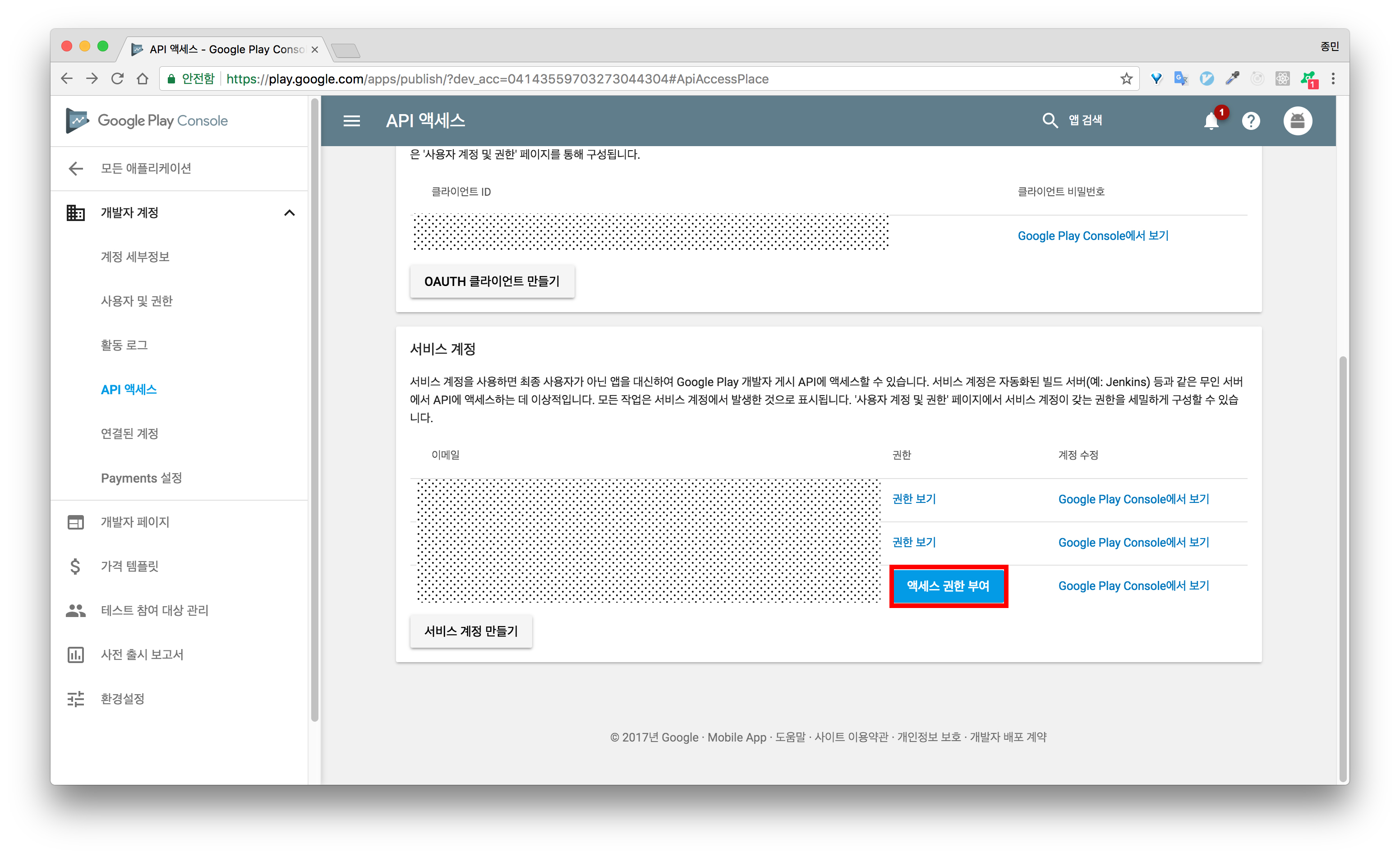
7.Google Play Console로 돌아와, 완료 버튼을 클릭한 후 서비스 계정이 생성되었는지 확인합니다.
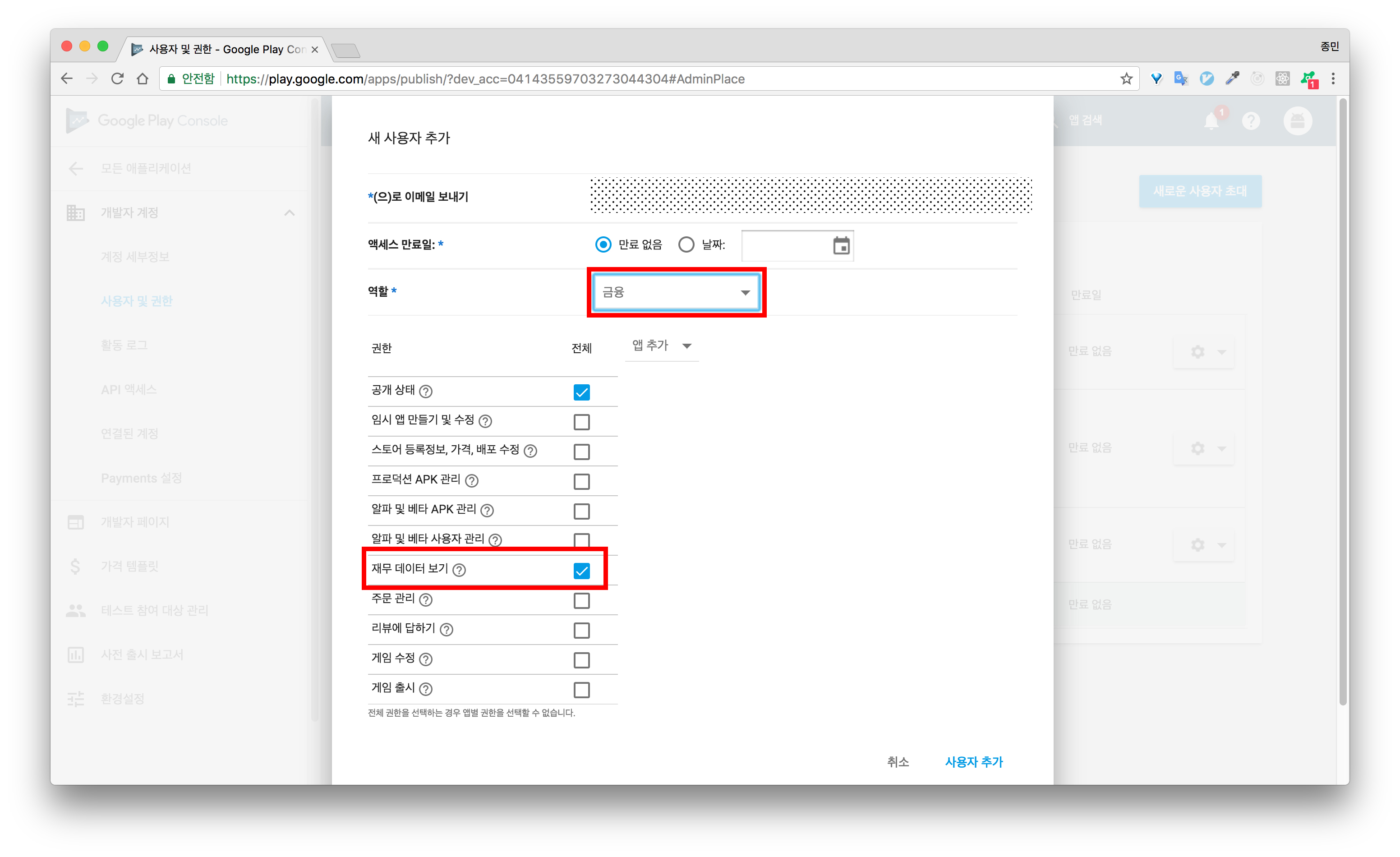
8.엑세스 권한 부여를 클릭합니다.
9.역할을 금융으로 선택한 후, 재무 데이터 보기 권한을 설정합니다. (구매내역 및 영수증 검증을 하기 위해서는 재무 보고서 보기 권한이 필요합니다 . 역할을 금융으로 선택해 주면 해당 권한이 자동으로 선택됩니다. 영수증 검증을 위해서는 금융 역할을 갖는 서비스 계정이 필요합니다.)
API 사용하기 (With node-iap)
복잡하게 토큰을 관리하며 HTTP/REST API를 사용할것 없이 Google은 다양한 언어에 맞게 Client 라이브러리를 제공하고 있습니다. Access Google APIs more easily를 통해서 다양한 언어의 라이브러리를 찾아 사용할 수 있습니다.
let platform = 'google'; let payment = { receipt: 'receipt data', // always required (purchaseToken) productId: 'abc', packageName: 'my.app', keyObject: '', // always required (user auth key) subscription: false, // optional, if google play subscription };
iap.verifyPayment(platform, payment, function (error, response) { /* your code */ });
node-iap는 google과 apple에서 모두 사용가능하기 때문에 platform을 명시해야 합니다. payment에는 확인하고자 하는 인앱결제 내역을 넣습니다.
Android In-App 결제를 하고나면 **purchaseToken**과 **productId**를 알 수 있습니다. payment의 receipt에는 purchaseToken 값을 넣습니다. productId와 packageName을 넣고 **KeyObject**에는 좀전에 사용자 계정을 추가하면서 다운로드 받았던 .json 파일의 값을 넣어주면 됩니다. (require 혹은 import하여 그대로 넣어주면 됩니다.)
Android 단말을 통해 테스트 결제 후 iap를 통해 purchase validation을 하면 다음과 같은 response를 얻을 수 있습니다.
여기서 중요한 부분은 **purchaseState**의 값이 **0**이면 결제가 완료된 상태를 뜻하며 **1**이면 환불이 완료된 상태를 의미합니다.
만약 사용자가 제대로 된 결제를 하지 않는다면 purchaseToken 값은 유효하지 않아 purchase validation 과정에서 err가 발생할 것입니다.
마치며
굉장히 큰 문제라고 생각했지만 생각보다 조치하는 과정에 있어서 큰 어려움은 없었습니다. 아직 제가 더 생각하지 못한 부분이 있을수도 있을거라 생각합니다. 혹시나 더 추가해야 하는 부분이 있다면 알려주세요!
저는 추가적으로 가짜 결제를 시도하는 유저들의 로그를 DB에 남기고 자동으로 block 처리를 해 게임을 못하도록 막았습니다. purchase validation 구현 후 바로 다음날 다시 또 가짜 결제가 이루어졌는데 유효성 검사가 제대로 이루어지는 것을 보고 정말 다행이라 생각했습니다.
제가 지금까지 회사에서 일하며 발생했던 가장 크리티컬했던 부분이라고 생각하는데 혹시나 이 글을 읽으시는 분중 아직 purchase validation을 하지 않고 계시다면 지금이라도 꼭 코드를 추가하셨으면 합니다.