오랜만에 포스팅을 하는 것 같습니다. 그간 회사에서 운이 좋게 3주간 보조 강사로 강의를 할 수 있는 기회를 얻어 강의를 하고 있습니다. 신기하게도 제가 졸업한 인천대학교에서 강의를 하고있습니다.
강의 주제는 **라즈베리파이에 음성인식 서비스(STT, TTS)와 GPIO를 활용해 나만의 비서**를 만들기 입니다. 라즈베리파이 같은 경우 이전에 친구들과 스마트미러를 만들며 사용했던 경험이 있었기에 낯설지 않았지만, 강의를 준비하고 강의자료를 만들면서 생각보다 여러가지로 고난을 겪었습니다…
단순히 발표자료가 아닌 누군가에게 지식을 잘 전달할 수 있도록 만들어야 하다보니 생각보다 만드는게 쉽지 않았습니다. 그래도 혹시나 필요하신 분이 있을까 하여 만들었던 강의자료를 공개합니다. 파이썬 관련된 부분은 책을 많이 참고하였기에 생략하고 라즈베리파이와 GPIO, 그리고 음성인식 프레임워크로 사용했던 Jasper에 대한 강의자료를 업로드하겠습니다. 다음은 강의 목차입니다.
- 라즈베리파이 강의 목차 -
라즈베리파이 OS 설치 & 설정
Unix / Linux 소개
사용자 관리, 원격접속 vi 편집기
bash 설정, vim 설정, gist 사용하기
GPIO, LED, BreadBoard
Extra GPIO
Jasper
앞으로 강의에 대한 **간단한 내용정리**와 사용한 **pdf 파일**을 업로드하도록 하겠습니다.
JavaScript **Class**는 ECMAScript 6을 통해 소개되었습니다. ES6의 Class는 기존 prototype 기반의 상속을 보다 명료하게 사용할 수 있도록 문법을 제공합니다. 이를 Syntatic Sugar라고 부르기도 합니다.
Syntatic Sugar : 읽고 표현하는것을 더 쉽게 하기 위해서 고안된 프로그래밍 언어 문법을 말합니다.
JavaScript를 ES6를 통해 처음 접하시는 분들은 알아두셔야할 것이 JavaScript의 Class는 다른 객체지향 언어(C++, C#, Java, Python, Ruby 등…)에서 사용되는 Class 문법과는 다르다는 것입니다. JavaScript에는 Class라는 개념이 없습니다. Class가 없기 때문에 기본적으로 Class 기반의 상속도 불가능합니다. 대신 다른 언어에는 존재하지 않는 프로토타입(Prototype)이라는 것이 존재합니다. JavaScript는 이 prototype을 기반으로 상속을 흉내내도록 구현해 사용합니다. Prototype을 처음 접하시는 분은 “Prototype 이제는 이해하자”를 참고하시면 도움이 될것같습니다.
Class 정의
JavaScript에서 Class는 사실 함수입니다. 함수를 함수 선언과 함수 표현식으로 정의할 수 있듯이 class 문법도 class 선언과 class 표현식 두가지 방법으로 정의가 가능합니다.
JavaScript 엔진은 function 키워드를 만나면 Function 오브젝트를 생성하듯, class 키워드를 만나면 Class 오브젝트를 생성합니다. class는 클래스를 선언하는 키워드이고 Class 오브젝트는 엔진이 class 키워드로 생성한 오브젝트입니다.
Class 선언
함수 선언과 달리 클래스 선언은 호이스팅이 일어나지 않기 때문에, 클래스를 사용하기 위해서는 먼저 선언을 해야합니다. 그렇지 않으면 ReferenceError 가 발생합니다.
say() { console.log('My name is ' + this.name); } }
Class 표현식
Class 표현식은 이름을 가질 수도 있고 갖지 않을 수도 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
const People = classPeople{ constructor(name) { this.name = name; }
say() { console.log('My name is ' + this.name); } }
const People = class{ constructor(name) { this.name = name; }
say() { console.log('My name is ' + this.name); } }
constructor
constructor는 클래스 인스턴스를 생성하고 생성한 인스턴스를 초기화하는 역할을 합니다. new People() 코드를 실행하면 People.prototype.constructor가 호출됩니다. 이를 default constructor라고 하며 constructor가 없으면 인스턴스를 생성할 수 없습니다.
1
const people = new People('KimJongMin');
new People(‘KimJongMin’)을 실행하면 People 클래스에 작성한 constructor가 자동으로 호출되고 파라미터 값으로 ‘KimJongMin’을 넘겨 줍니다.
new 연산자가 인스턴스를 생성하는 것처럼 보이지만, 사실 new 연산자는 constructor를 호출하면서 파라미터를 넘겨주는 역할만 합니다. 호출된 constructor가 인스턴스를 생성하여 반환하면 new 연산자가 받아 new를 실행한 곳으로 반환합니다. 과정은 다음과 같습니다.
new People(‘KimJongMin’)을 실행
new 연산자가 constructor를 호출하면서 파라미터 전달
constructor에 작성한 코드를 실행하기 전에 빈 Object 를 생성
constructor 코드를 실행
생성한 Object(인스턴스)에 property 할당 (인스턴스를 먼저 생성했기 때문에 this로 Object 참조 가능
생성한 Object 반환
다음은 생성된 인스턴스의 구조입니다.
1
console.dir(people);
people 인스턴스의 **_proto_**는 People Class 오브젝트와 함께 생성된 Prototype object를 가리키고 있습니다. 결국 Class 문법을 이용한 코드를 prototype 기반의 코드로 변경하면 다음과 같습니다.
1 2 3 4 5 6 7
functionPeople(name) { this.name = name; }
People.prototype.say = function () { console.log('My name is ' + this.name); };
Prototype 기반 상속(ES5)과 Class 기반 상속(ES6) 비교
먼저 ES5에서 Prototype을 사용하여 상속을 구현하는 방법을 살펴보고, 그 후 ES6에서 Class로 상속을 구현하는 형태를 보겠습니다.
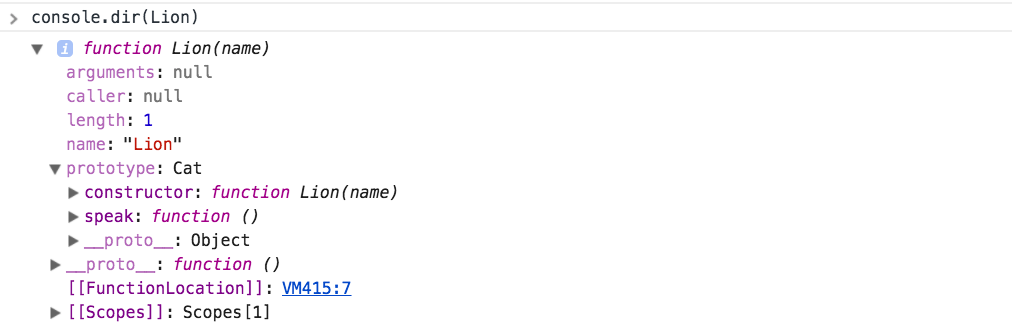
new Lion()을 실행하면 Lion()이 호출되고, default constructor를 호출합니다. 그래서 Lion()을 생성자(constructor) 함수라고 합니다.
생성자 함수가 있으면 Cat.prototype.speak와 같이 prototype에 메서드를 연결한 코드가 있습니다. 이와 같이 prototype에 작성하지 않으면 각각의 인스턴스에 메서드가 생성되게 됩니다. 이 형태가 ES5에서 인스턴스를 구현하는 기본 형태 입니다.
Object.create()를 통해 Cat.prototype에 연결된 메서드를 Lion.prototype.__proto__에 첨부합니다. Lion.prototype에는 constructor가 연결되어 있는데 prototype을 재 할당했기 때문에 지워진 constructor를 다시 할당해 줍니다.
ES6에서는 extends 키워드로 상속을 구현합니다. Cat 클래스를 상속받은 Lion 클래스의 구조는 다음과 같습니다.
위의 prototype을 통해 상속을 구현한 Lion 생성자 함수의 구조와 비교했을때 일치합니다. 추가적으로 new Lion(‘Samba’) 를 실행하면 다음의 과정을 거치게됩니다.
Lion 클래스의 constructor를 호출
Lion 클래스에 constructor를 작성하지 않았기 때문에 슈퍼 클래스의(Cat) constructor가 호출됨 (내부적으로 프로토타입 체인으로 인해)
슈퍼 클래스의 constructor에서 this는 현재의 인스턴스를 참조하므로 인스턴스의 name 프로퍼티에 파라미터로 전달받은 값을 설정
생성한 인스턴스를 lion에 할당
super 키워드
서브 클래스와 슈퍼 클래스에 같은 이름의 메서드가 존재하면 슈퍼 클래스의 메서드는 호출되지 않습니다. 이때 super 키워드를 사용해서 슈퍼 클래스의 메서드를 호출할 수 있습니다. (서브 클래스의 constructor에 super()를 작성하면 슈퍼 클래스의 constructor가 호출됩니다.)
static 키워드
static 키워드는 클래스를 위한 정적(static) 메소드를 정의합니다. 정적 메소드는 prototype에 연결되지 않고 클래스에 직접 연결되기 때문에 클래스의 인스턴스화(instantiating) 없이 호출되며, 클래스의 인스턴스에서는 호출할 수 없습니다. 동일한 클래스 내의 다른 정적 메서드 내에서 정적 메서드를 호출하는 경우 키워드 this를 사용할 수 있다.
정적 메소드는 어플리케이션(application)을 위한 유틸리티(utility) 함수를 생성하는데 주로 사용됩니다.
마치며
ES6의 Class 문법에 대해 정리해 보았다. JavaScript 언어를 약 1년전 Node.js 를 시작하며 처음 접하게 되었는데 사실 그 당시 Prototype과 상속에 대해 크게 다룰일이 없었다. (어쩌면 너무 무지해서 사용 필요성을 느끼지 못했을 수도…) 그 후 Node.js 버전을 올리고 ES6를 공부하며 Class 문법을 접하게 되었는데 JavaScript의 Prototype에 대한 이해와 지식이 부족하다 보니 이전에 공부했던 C++과 Java의 Class 처럼 이해했던 것 같다. 그래도 그 후 Prototype과 더불이 Class까지 공부하며 지금은 어느정도 이해하게 된것 같다. 결론은… 역시나 JavaScript에서 Prototype을 이해하는건 중요한것 같다.
자바 스크립트에서 함수는 객체이기 때문에 프로퍼티를 가질 수 있습니다. 그리고 언제든지 함수에 사용자 정의 프로퍼티를 추가할 수도 있습니다. 함수에 프로퍼티를 추가하여 결과(반환 값)을 캐시하면 다음 호출 시점에 복잡한 연산을 반복하지 않을 수 있습니다. 이런 활용 방법을 **메모이제이션 패턴**이라고 합니다.
다음 코드에서는 myFunc 함수에 cache 프로퍼티를 생성합니다. 이 프로퍼티는 일반적인 프로퍼티처럼 myFunc.cache와 같은 형태로 접근할 수 있습니다. cache 프로퍼티는 함수로 전달된 param 매개변수를 키로 사용해서 계산의 결과를 값으로 가지는 객체(해시)입니다. 결과 값은 필요에 따라 복잡한 데이터 구조로 저장할 수도 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13
var myFunc = function (param) { if (!myFunc.cache[param]) { var result = {}; // ... // 비용이 많이 드는 수행 후 result에 결과 저장 // ... myFunc.cache[param] = result; } return myFunc.cache[param]; };
// 캐시 저장공간 myFunc.cache = {};
메모이제이션 적용하기
메모이제이션을 공부한 후 현재 진행중인 에밀리(개인 프로젝트)에 적용해 보았습니다. 어느 부분에 적용했는지 적용 전과 적용 후 얼마나 효율이 올라갔는지를 알아보겠습니다.
수정할 부분
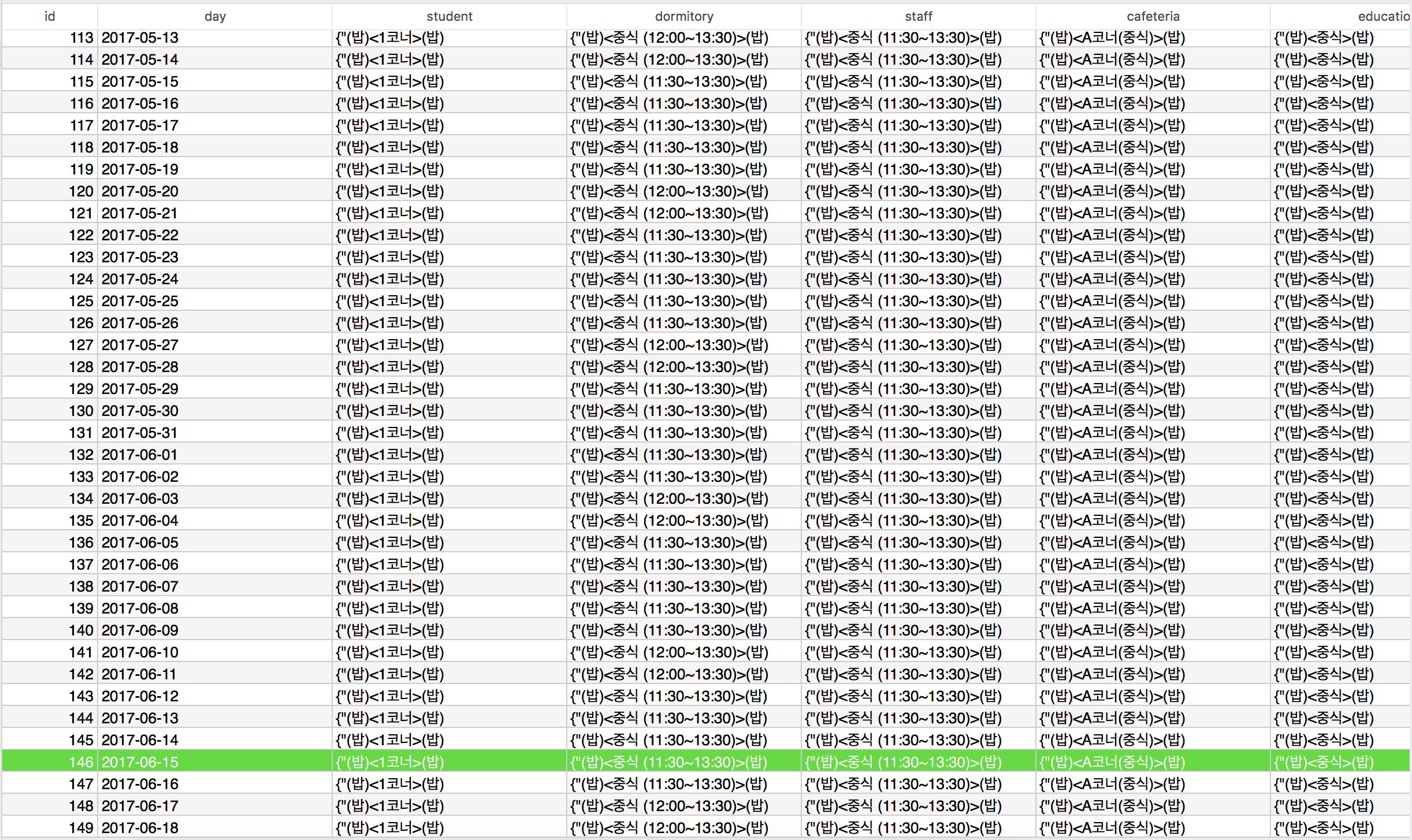
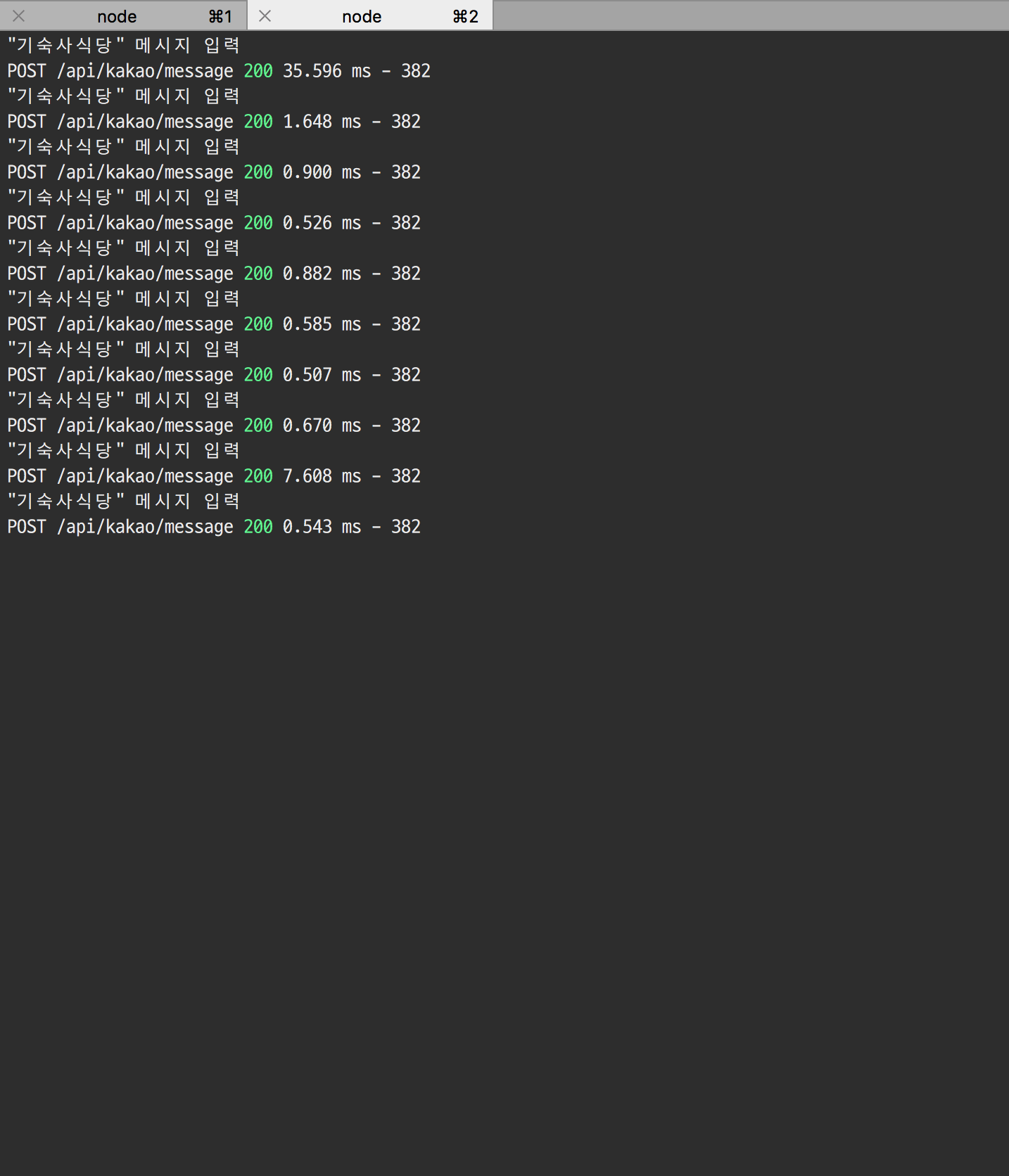
메모이제이션 패턴을 적용할 코드가 현재 하고 있는 기능은 다음과 같습니다. 사용자의 요청(학생식당, 카페테리아, 사범대식당, 기숙사식당, 교직원식당)에 따라 미리 크롤링 후 DB에 저장되어 있는 데이터(메뉴)를 가져와 응답합니다. 메모이제이션 패턴을 사용함으로써 얻을 수 있는 이점은 비용이 많이 드는 결과를 캐싱하고 그 이후에 재사용함으로써 비용을 줄일 수 있다는 것입니다. 현재 코드에서 비용이 많이 드는 작업은 DB를 조회하는 부분입니다. DB에는 다음과 같이 미리 크롤링한 데이터가 날짜별로 저장되어 있습니다.
사용자의 요청에 따라 해당 날짜의 데이터를 조회한 후 사용자가 요청한 식당에 맞는 데이터를 결과로 반환합니다. 그렇기 때문에 해당 날짜의 최초 요청이 이루어진 후 그 하루 동안에는 계속해서 DB에 같은 쿼리를 통해 같은 결과를 얻게 됩니다. 이 부분이 비용이 많이 드는 작업이기 때문에 메모이제이션 패턴을 통해 개선해보았습니다.
메모이제이션 적용 전
먼저 메모이제이션 패턴을 적용하기 전 코드입니다. menuHandler 클래스의 getMenu 함수는 menuService를 통해 DB에서 해당 날짜의 식당 메뉴를 가져와 매개변수로 전달받은 식당의 이름을 사용하여 결과로 반환하는 역할을 합니다.
classmenuHandler{ staticgetMenu(place) { returnnewPromise((_s, _f) => { const today = newDate().yyyymmdd(); let menu = '';
menuService.show(today) .then(menuList => { if (!menuList) { menu = '데이터가 없습니다. 관리자에게 문의해주세요'; }
switch (place) { case'학생식당': menu = menuList.student.join('\n\n'); break; case'카페테리아': menu = menuList.cafeteria.join('\n\n'); break; case'사범대식당': menu = menuList.education.join('\n\n'); break; case'기숙사식당': menu = menuList.dormitory.join('\n\n'); break; case'교직원식당': menu = menuList.staff.join('\n\n'); break; }
_s(menu); }) .catch(err => { _f(err); }); }); } }
module.exports = menuHandler;
3. 메모이제이션 적용 후
메모이제이션 패턴을 적용 한 후 코드입니다. setCache, getCache, pickMenu 함수가 추가되었고, getMenu 함수의 코드도 조금 변경되었습니다. 기존 코드의 getMenu 함수에서는 바로 DB를 조회하여 결과를 반환하였지만, 변경된 코드에서는 getCache 함수를 통해 캐시에 저장된 데이터가 있는지 확인 후 분기하여 처리합니다.
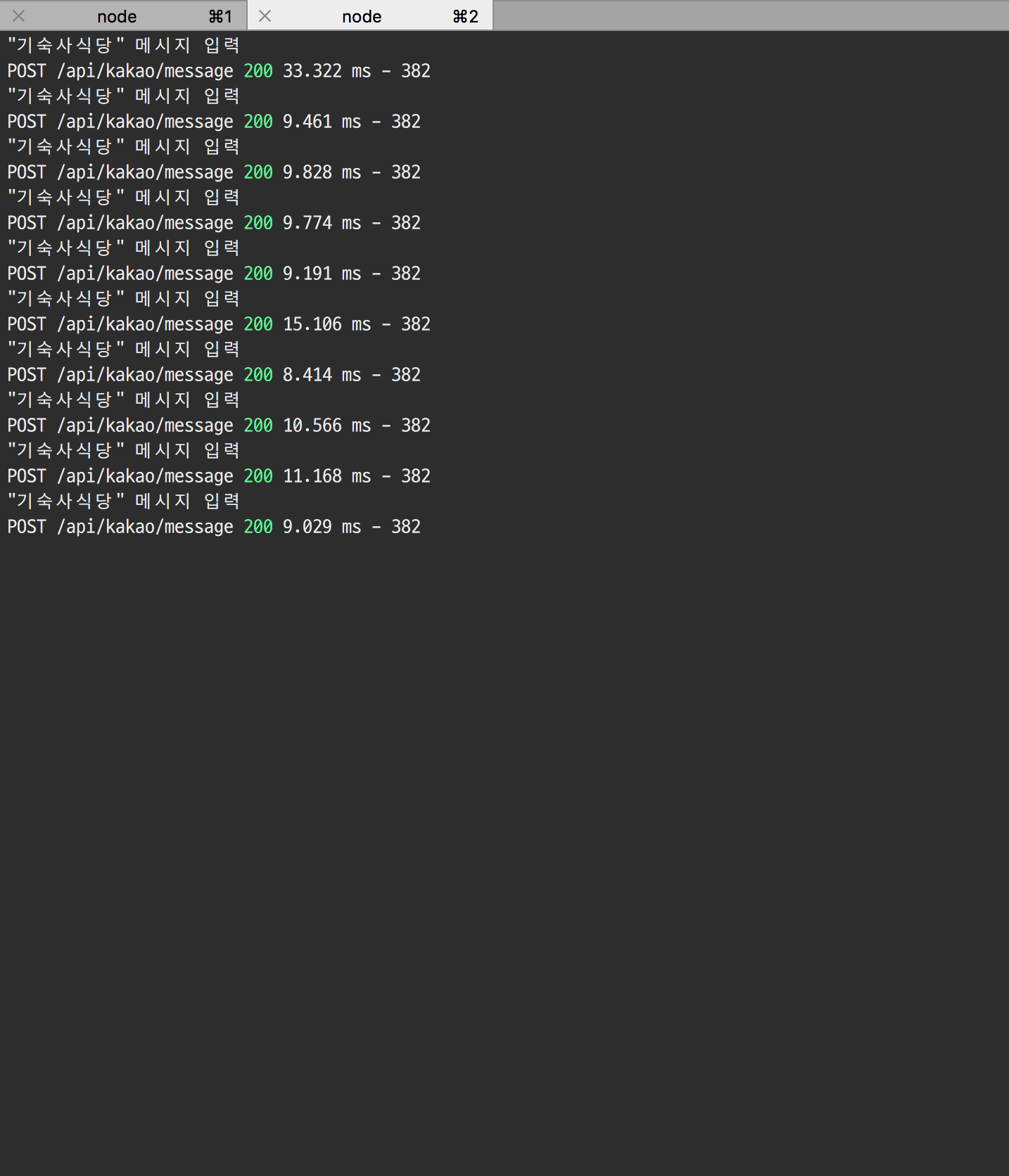
메모이제이션 패턴을 적용하기 전과 적용한 후의 성능 차이는 아래 보이는것처럼 눈에 띄게 차이가 납니다. 메모이제이션 패턴을 적용한 코드는 첫번째 요청(캐싱 하기 전)때는 메모이제이션 패턴 적용 전과 응답속도가 비슷하지만 그 이후의 응답은 캐싱된 데이터를 이용하기 때문에 비교될 정도로 빨라졌습니다.
마치며
메모이제이션을 적용하기 전과 후 모두 같은 기능을 결과를 만들어내는 코드이지만 코드를 작성하는 방법에 따라 더욱 더 빠른 효율적인 서비스를 만들 수 있다는 것을 느끼게 되었습니다. 현재 제 상황에서는 캐싱된 데이터도 하루가 지나게되면 쓰이지 않고 계속 메모리에 남아있게 되는데 그 부분에 대한 처리를 추가해야할것 같습니다. 이번에 적용한 코드 뿐만 아니라 아직 프로잭트 내에 메모이제이션 패턴을 적용할 수 있는 부분이 더 있습니다. 앞으로 디자인패턴 공부를 계속하여 새로운 패턴들을 적용시키며 리팩토링을 해야겠습니다.
자바스크립트에서는 비동기 프로그래밍 해결을 위해 하나의 패턴으로 콜백을 사용했다. 그러나 콜백 패턴은 비동기 처리 중 발생한 오류를 예외 처리하기 힘들고 여러 개의 비동기 로직을 한꺼번에 처리하는 데도 한계가 있다. 즉 콜백 패턴은 그다지 유용한 패턴이 아니다. 이때 비동기 프로그래밍을 위한 또 다른 패턴으로 Promise가 등장했다.
**Promise**는 비동기 처리 로직을 추상화한 객체와 그것을 조작하는 방식을 말한다. Promise를 지원하는 함수는 비동기 처리 로직을 추상화한 promise 객체를 반환 한다. 그리고 객체를 변수에 대입하고 성공 시 동작할 함수와 실패 시 동작할 함수 를 등록해 사용한다.
함수를 작성하는 방법은 promise 객체의 인터페이스에 의존 한다. 즉, promise 객체에서 제공하는 메서드만 사용해야 하므로 전통적인 콜백 패턴처럼 인자가 자유롭게 결정되는 게 아니라 같은 방식으로 통일된다. Promise 라고 부르는 하나의 인터페이스를 이용해 다양한 비동기 처리 문제를 해결할 수 있다. 복잡한 비동기 처리를 쉽게 패턴화할 수 있다는 뜻이다. 이것이 Promise의 역할이며 Promise를 사용하는 많은 이유 중 하나다.
Promise 사용법
Promise는 new 연산자를 선언하여 Promise 인스턴스 객체를 생성한다.
1 2 3
const promise = newPromise(function(resolve, reject) { // 비동기 처리 로직 후 resolve 또는 reject를 호출 });
new 연산자로 생성된 Promise 인스턴스 객체에는 성공(resolve), 실패(reject)했을 때 호출될 콜백 함수를 등록할 수 있는 Promise.then()이라고 하는 인스턴스 메서드가 있다.
1
promise.then(onFulfilled, onRejected)
성공했을 때는 onFulfilled가 호출되고 실패했을 때는 onRejected가 호출된다. promise.then()으로 성공 혹은 실패 시의 동작을 동시에 등록할 수 있다. 만약 오류 처리만 한다면 promise.then(undefined, onRejected)와 같은 의미인 promise.catch(onRejected)를 사용하면 된다.
1
promise.catch(onRejected)
Promise 상태
생성자 함수를 new 연산하여 생성된 Promise 인스턴스 객체에는 3가지 상태가 존재한다. promise 객체는 Pending 상태로 시작해 Fulfilled나 Rejected 상태가 되면 다시는 변화하지 않는다. (Event 리스너와는 다르게 then()으로 등록된 콜백함수는 한 번만 호출된다.)
Pending : 성공도 실패도 아닌 상태, Promise 인스턴스 객체가 생성된 초기상태
Fulfilled : 성공(resolve)했을 때의 상태, onFulfilled가 호출된다.
Rejected : 실패(reject))했을 때의 상태, onRejected 호출된다.
Promise.resolve, Promise.reject
Promise의 정적 메서드인 **Promise.resolve()**를 사용하면 new Promise() 구문을 단축해 표기할 수 있다. Promise.resolve()는 Fulfilled 상태인 promise 객체를 반환한다. 또한, Promise. resolve()는 thenable 객체를 promise 객체로 변환할 수 있다. 이것은 Promise.resolve()의 중요한 특징 중 하나다.
thenable은 ES6 Promises 사양에 정의된 개념이다. then()을 가진 객체 즉, 유사 promise 객체를 의미한다. length 프로퍼티를 갖고 있지만, 배열이 아닌 유사 배열 객체 Array-like Object와 같다. Promise.resolve()는 thenable 객체의 then() 이 Promise의 then()과 같은 동작을 할 것이라 기대하고 promise 객체로 변환한다.
**Promise.reject()**도 promise 객체를 반환한다. 따라서 에러 객체와 함께 catch()를 이용해 등록한 콜백 함수가 호출된다.
Promise.prototype.then
Promise에서는 메서드를 체인하여 코드를 작성할 수 있다. then()은 콜백 함수를 동록하기만 하는것이 아니라 콜백에서 반환된 값을 기준으로 새로운 promise 객체를 생성하여 전달하는 기능도 갖고 있다.
Promise.all, Promise.race
**Promise.all()**은 Promise 객체를 배열로 전달받고 객체의 상태가 모두 Fulfilled 됐을 때 then()으로 등록한 함수를 호출한다. **Promise.race()**는 Promise.all()과 마찬가지로 promise 객체를 배열로 전달한다. Promise.all()과 달리 전달한 객체의 상태가 모두 Fulfilled가 될 때까지 기다리지 않고 전달한 객체 중 하나만 완료(Fulfilled, Rejected)되어도 다음 동작으로 넘어간다. Promise.race는 먼저 완료된 promise 객체가 있더라도 다른 promise 객체를 취소하지 않는다. (ES6 Promise 사양에는 취소라는 개념이 없다.)
Promise 특징
Promise는 항상 비동기로 처리된다.
Promise.resolve()나 resolve()를 사용하면 promise 객체는 바로 Fulfilled 상태가 되기 때문에 then()으로 등록한 콜백 함수가 동기적으로 호출될 것이라 생각할 수 있다. 하지만 실제로는 then()으로 등록한 콜백 함수는 비동기적으로 호출된다. 동기적으로 처리 가능한 상황에서도 비동기적으로 처리하는 이유는 동기와 비동기가 혼재될때 발생하는 문제를 막기 위함이다.
새로운 promise 객체를 반환하는 then
promise.then(), catch()는 최초의 promise 객체에 메서드를 체인하는 것처럼 보이지만 실제로는 then()과 catch()는 새로운 promise 객체를 생성해 반환한다. Promise.all()과 Promise.race() 또한 새로운 promise 객체를 생성해 반환한다.
콜백-헬과 무관한 Promise
Promise는 callback-hell 을 해결할수는 없고 완화할 수 있을 뿐이다. 완화할 수 있는 이유는 단일 인터페이스와 명확한 비동기 시점 표현, 강력한 에러 처리 메커니즘 때문이다. 이는 비동기 처리 자체를 손쉽게 다룰 수 있도록 하는 것이므로 callback-hell 을 해결하는 방법으로 여기는건 바람직하지 않다.
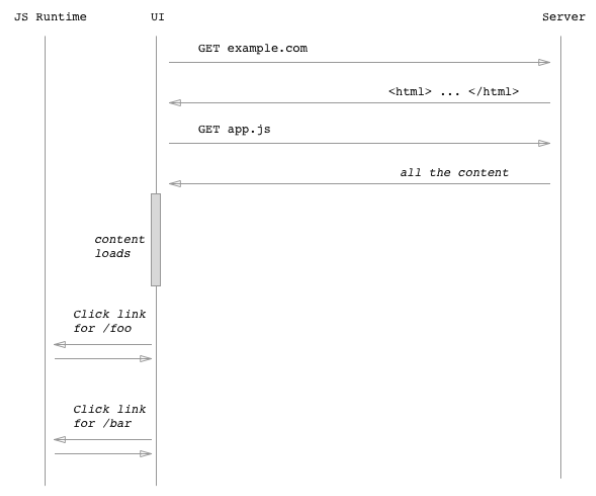
그런 다음 페이지가 로드되면 프레임워크는 URL 표시줄을 보고 [ ‘/‘] 페이지에서 문자열을 가져 와서 div class = "container"> </ div>에 삽입합니다. 또한 링크를 클릭하면 프레임워크가 이벤트를 가로 채고 컨테이너에 새 문자열 (예 : 페이지 [ ‘/ foo’])을 삽입하고 브라우저가 정상적으로하는 것처럼 HTTP 요청을 실행하지 못하게 합니다.
검색 엔진 최적화(SEO)
웹 크롤러가 reddit.com 을 요청하기 시작했다고 가정해봅시다.
1 2 3 4 5 6 7 8 9 10
var request = require('request'); request.get('reddit.com', function (error, response, body) { // body looks something like this: // <html> // <head> ... </head> // <body> // <a href="espn.com">ESPN</a> // <a href="news.ycombinator.com">Hacker News</a> // ... other <a> tags ... });
그러면 크롤러는 응답 본문에있는 <a href> 항목을 사용해서 새 요청을 생성합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13
var request = require('request'); request.get('reddit.com', function (error, response, body) { // body looks something like this: // <html> // <head> ... </head> // <body> // <a href="espn.com">ESPN</a> // <a href="news.ycombinator.com">Hacker News</a> // ... other <a> tags ... request.get('espn.com', function () { ... }); request.get('news.ycombinator.com', function () { ... }); });
그 후 크롤러는 espn.com 및 _news.ycombinator.com_의 링크를 사용하여 크롤링을 계속함으로써 프로세스를 계속 진행합니다.
결국 다음과 같은 재귀 코드처럼 동작합니다.
1 2 3 4 5 6 7 8 9 10
var request = require('request'); functioncrawlUrl(url) { request.get(url, function (error, response, body) { var linkUrls = getLinkUrls(body); linkUrls.forEach(function (linkUrl) { crawlUrl(linkUrl); }); }); } crawlUrl('reddit.com');
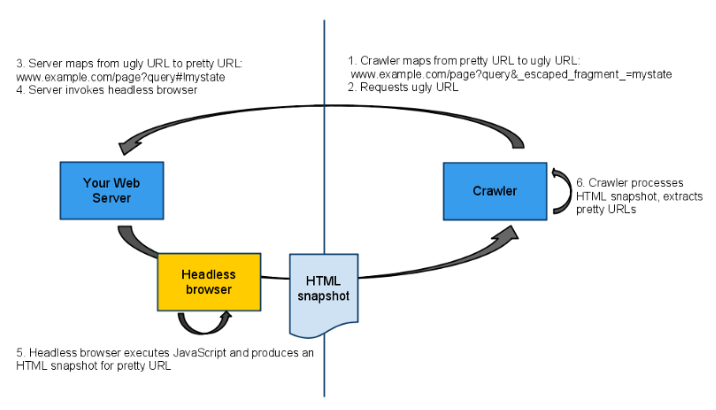
크롤러가 www.example.com/page?query#!mystate 를 방문하면 www.example.com/page?query&_escaped_fragment_=mystate 로 변환됩니다. 이렇게하면 서버가 _escaped_fragment_를 사용하여 요청을 받으면 사람이 아닌 크롤러에서 요청을 받는다는 것을 알 수 있습니다.
그렇기때문에 요청이 크롤러에서 온 경우 <div class = "container"> ... </ div>를 제공할 수 있습니다. 일반적인 요청 인 경우 <div class = "container"> </ div>를 제공하고 JavaScript가 내용을 내부에 삽입하도록 할 수 있습니다.
그러나 문제가 있습니다. 서버가 <div class = "container"> </ div>안에 무엇이 들어가는지 알지 못하기 때문입니다. 내부에 무엇이 들어가는지 파악하려면 JavaScript를 실행하고 DOM을 만들고 DOM을 조작해야합니다. 전통적인 웹 서버는 이를 수행하는 방법을 모르기 때문에 Headless Browser로 알려진 서비스를 사용합니다.
더 똑똑해진 크롤러
6년 후, Google은 크롤러가 한층 더 똑똑해 졌다고 발표했습니다. Crawler 2.0에서 <script> 태그를 볼 때 웹 브라우저처럼 실제로 요청을하고 코드를 실행하고 DOM을 조작한다는 것입니다.
그래서 다음과 같은 코드가
1
<divclass="container"></div>
이제는 이렇게 보이는 것입니다.
1 2 3 4 5 6 7
<divclass="container"> ... ... ... ... ... </div>
Fetch as Google를 사용하여 Google 크롤러가 특정 URL을 방문했을 때 어떤 내용을 볼지 결정할 수 있습니다.
관련된 발표문의 내용 일부를 첨부합니다.
당시 우리 시스템은 자바 스크립트를 사용하여 사용자에게 콘텐츠를 제공하는 페이지를 렌더링하고 이해할 수 없었습니다. 크롤러는 동적으로 생성 된 콘텐츠를 볼 수 없었기 때문에 웹 마스터가 AJAX 기반 애플리케이션을 검색 엔진으로 인덱싱 할 수 있도록 일련의 방법을 제안했습니다.
시대가 바뀌 었습니다. 현재 Googlebot이 자바 스크립트 또는 CSS 파일을 크롤링하는 것을 차단하지 않는 한 일반적으로 최신 브라우저와 같이 웹 페이지를 렌더링하고 이해할 수 있습니다.
덜 똑똑한 크롤러
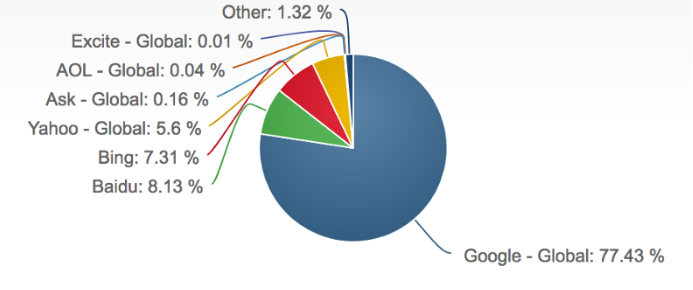
불행히도 Google 만이 유일한 검색 엔진이 아닙니다. Bing, Yahho, Duck Duck Go, Baidu 등도 있으며 실제로 사람들은 이러한 검색 엔진도 빈번하게 사용합니다.
두 세계(서버 측 렌더링, 클라이언트 측 렌더링)의 장점을 최대한 활용하려면 다음의 방법이 있습니다.
첫 번째 페이지 로드에는 서버 측 렌더링을 사용.
그 후 모든 후속 페이지 로드에는 클라이언트 측 렌더링을 사용.
이것이 의미하는 바를 생각해보세요.
첫 번째 페이지 로드의 경우 사용자가 콘텐츠를 보기 전에 두 번 왕복하지 않습니다.
후속 페이지 로드가 빨라집니다.
크롤러는 간단한 HTML을 얻습니다. 옛날처럼 JavaScript를 실행하거나 _escaped_fragment_를 처리할 필요가 없습니다.
그러나 이를 위한 설정을 하기위해서는 서버에서 약간의 작업이 필요합니다. Angular, React 및 Ember 모두 이 접근 방식으로 변경했습니다.
토론
먼저 고려해야 할 몇 가지 사항은 다음과 같습니다.
약 2%의 사용자가 JavaScript를 사용할 수 없게 설정되어 있는 경우 클라이언트 측 렌더링이 전혀 작동하지 않습니다.
웹 검색의 약 1/4은 Google 이외의 엔진으로 수행됩니다.
모두가 빠른 인터넷 연결을 사용하는 것은 아닙니다.
휴대 전화 사용자는 대개 빠른 인터넷 연결이 필요하지 않습니다.
너무 빠른 UI는 혼란 스러울 수 있습니다. 사용자가 링크를 클릭한다고 가정 해보세요. 앱에서 새로운 뷰로 이동합니다. 그러나 새로운 뷰는 이전의 뷰와 미묘하게 다릅니다. 그리고 변경 사항은 즉시 발생했습니다 (클라이언트 측 렌더링의 장점). 새로운 뷰가 실제로 로드 된 것을 사용자가 알지 못할 수도 있습니다. 또는 사용자가 주의를 기울 였지만 상대적으로 미묘하기 때문에 사용자는 전환이 실제로 발생했는지 여부를 감지하기 위해 약간의 노력을 기울여야합니다. 때로는 약간의 로딩 스피너와 전체 페이지 재 렌더링을 하는 것이 좋습니다.
캐싱이 중요합니다. 따라서 서버 측 렌더링을 사용하면 실제로 사용자가 실제로 모든 것을 서버로 가져갈 필요가 없습니다. 때로는 바다 건너편의 “공식”서버가 아닌 근처의 서버에 가면됩니다.
실제로 성과와 관련하여 때로는 중요하지 않습니다. 때로는 속도가 좋고 속도가 약간 올라가더라도 삶이 더 좋아지지는 않습니다.
대부분의 사용자는 인터넷 연결 상태가 좋으며 충분히 빠릅니다. 특히 Macbook Pro로 yuppies를 타겟팅하는 경우. 초기로드 시간이 너무 길어서 사용자를 잃을 염려가 없습니다. 사용자가 링크를 클릭 할 때 실제로 새 페이지가 로드된다는 사실을 사용자가 알지 못하는 사용성 문제에 대해 걱정할 필요가 없습니다.
그러나 초기 페이지 로드시 서버 측 렌더링을 사용하는 클라이언트 측 렌더링을위한 사용 사례는 확실합니다. 큰 회사의 경우 #perfMatters, 인터넷 연결 속도가 느린 사용자가 있고 최적화에 충분한 시간을 할애 할 수있는 충분한 엔지니어링 팀이있는 경우가 종종 있습니다.
앞으로 이 같은 형태의 웹 프레임 워크 (초기 페이지 로드시 서버 쪽 렌더링을 사용하고 후에는 클라이언트 측 렌더링을 수행)가 보다 안정되고 사용하기 쉬워지기를 기대합니다. 이 시점에서 추가 된 복잡성은 최소화 될 것입니다. 그러나 오늘날,이 모든 것은 매우 새롭고, 많은 추상화가있을 것으로 기대합니다. 앞으로 더 나아가 클라이언트 측 렌더링이 필요하지 않은 곳에 인터넷 연결이 충분해지기 때문에 추세가 다시 서버 측 렌더링으로 되돌아 갈 것으로 예상됩니다.
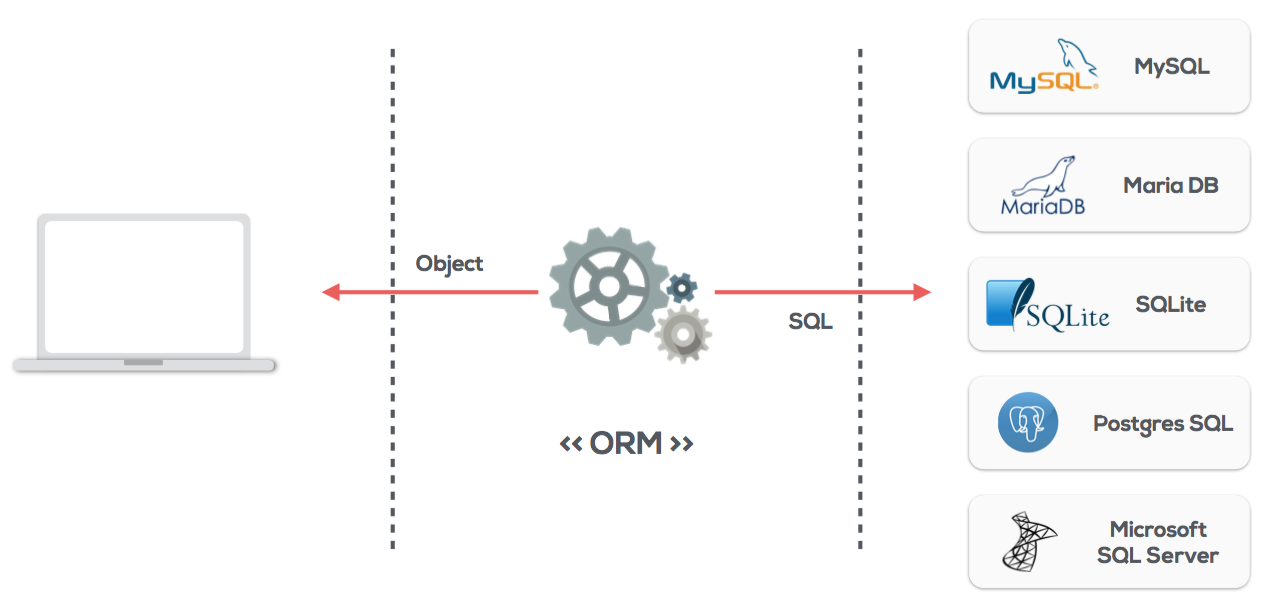
**관계형 데이터베이스(RDB)**를 사용할때 데이터베이스의 데이터 조작(CRUD)를 위해서는 SQL 문을 작성해야합니다. SQL 문은 비즈니스 로직을 구성하고 있는 코드와 함께 작성하게 되는데 이는 코드의 가독성을 떨어뜨릴뿐만 아니라, 사용하는 관계형 데이터베이스에 따라 조금씩의 차이가 존재하기 때문에 문제가 발생할 수 있습니다. 이를 해결하기 위해 ORM을 사용합니다.
**ORM(Object Relational Mapping)**은 객체(Object)와 관계(Relation)를 맵핑(Mapping)하여 비즈니스 로직에 집중할 수 있도록 데이터 처리 로직을 추상화시킵니다.
객체와 관계를 매핑한다는 것은 데이터베이스에 저장된 레코드를 객체로 바꿔표현한다는 의미하며, 비즈니스 로직에 집중할 수 있도록 데이터 처리 로직을 추상화한다는 것은 쿼리를 사용하지 않고도 데이터베이스를 사용할 수 있음을 뜻합니다.
ORM을 사용할 경우 특정 DBMS에 종속되지 않으며 생산성, 독립성, 가독성(SQL문이 코드에 들어가지 않기때문) 및 유지보수 측면에서의 장점이 있지만 반대로 RAW query에 비해 퍼포먼스가 떨어지고, query가 복잡해 질수록 오히려 생산성이 저하될 수 있다는 단점도 존재합니다.
RDS로 PostgresSQL, MySQL, MariaDB, SQLite, MSSQL을 지원하고 transaction, read replication등 다양한 기능을 제공하고 있으며. 또한 Promise를 기본으로 동작하기 때문에 비동기 코드를 보기좋게 작성할 수 있습니다.
실습을 위해 express-generator를 통해 Express 프로젝트를 생성후 sequelize와 mysql module을 설치합니다. (Express 프로젝트를 생성하는 부분은 생략합니다.)
sequelize cli를 통해 생성한 config/sequelize.json파일에 데이터베이스에 관련된 설정 값을 입력합니다.
NODE_ENV 에 따라 각기 다른 값을 사용하기 때문에 상황에 맞게 설정할 수 있습니다. NODE_ENV에 대해 잘 알지 못한다면 이곳을 참고하세요.
데이터베이스를 사용한 프로젝트 경험이 있다면 대부분의 config 값은 입력할 수 있습니다. config 값중 dialect에는 사용하는 RDB 이름을 입력해야 합니다. diaect에 사용 가능한 값은 sequelize docs를 참고하세요. 현재 사용 가능한 RDB 로는 ‘mysql’, ‘sqlite’, ‘postgress’, ‘mariadb’가 있습니다.
추가적으로 커넥션 풀과 로깅 기능을 사용한다면 해당 값을 추가합니다. 추가적으로 필요한 옵션은 docs를 참고하세요.
Model을 생성하기 전 sequelize cli를 통해 생성한 models/index.js파일을 살펴보겠습니다. index.js 의 역할은 config/sequelize.json의 설정값을 읽어 sequelize를 생성한 후 models 폴더 아래에 정의한 model 관련 js 파일을 모두 로딩하여 db 객체에 Model을 정의한 후 반환합니다.
sequelize config 관련 파일을 sequelize.json으로 생성하였다면 config 파일을 불러오는 require 부분의 경로를 수정해주어야 합니다.
이제 models 폴더 아래에 간단한 모델을 정의해 보겠습니다. **user.js**를 생성 후 다음의 코드를 입력합니다.
module.exports = function (sequelize, DataTypes) { const user = sequelize.define('User', { userID: { field: 'user_id', type: DataTypes.STRING(50), unique: true, allowNull: false }, password: { field: 'password', type: DataTypes.STRING(30), allowNull: false }, }, { // don't use camelcase for automatically added attributes but underscore style // so updatedAt will be updated_at underscored: true,
// disable the modification of tablenames; By default, sequelize will automatically // transform all passed model names (first parameter of define) into plural. // if you don't want that, set the following freezeTableName: true,
// define the table's name tableName: 'user' });
return user; };
/* Sequelize 참고 DataTypes => http://docs.sequelizejs.com/en/v3/api/datatypes/ Associations => http://docs.sequelizejs.com/en/v3/api/associations/ Model Function => http://docs.sequelizejs.com/en/v3/api/model/ */
Model을 생성하며 사용된 옵션은 주석과 docs를 참고합니다. 이제 모델에 대한 정의가 끝났습니다. 데이터베이스에 user라는 테이블은 User라는 Object로 매핑되었고 user_id, password라는 칼럼은 User Object의 속성으로 매핑되었습니다.
Sequelize Sync 사용하기
Sequeliz에서는 **입력(INSERT), 수정(UPDATE), 조회(SELECT), 삭제(DELETE)**의 **데이터 조작(DML: Data Manipulation Language)**뿐만 아니라 데이터베이스의 스키마 객체를 생성(CREATE), 변경(ALERT), 제거(DROP) 할 수 있는 **데이터 정의(DDL: Data Definition Language)**도 지원합니다. 따라서 이미 만들어진 데이터베이스 테이블에 모델을 매핑할 수 있을 뿐만 아니라, 정의한 모델을 바탕으로 테이블을 생성할 수도 있습니다.(동기화)
해당 기능을 사용하기 위해서는 Sequelize의 sync 메서드를 사용합니다. **app.js**에 다음의 코드를 추가합니다.
1 2 3 4 5 6 7 8 9 10 11 12
// connect To DB const models = require('./models'); models.sequelize.sync() .then(() => { console.log('✓ DB connection success.'); console.log(' Press CTRL-C to stop\n'); }) .catch(err => { console.error(err); console.log('✗ DB connection error. Please make sure DB is running.'; process.exit(); });
sync 메서드를 호출하여 실패했을 경우에는 에러 메시지를 출력 후 프로세스를 종료합니다.
sync 메서드는 모델에서 정의한 이름의 테이블이 존재하지 않을 경우에만 동작합니다. 이미 테이블이 존재할 경우에는 models.sequelize.sync({force: true}) 과 같이 force 옵션을 주어 강제적으로 테이블을 제거 후 다시 생성이 가능하지만 매우 위험한 옵션이므로 주의를 기울여 사용해야 합니다.
Sequelize 예제 (SELECT)
이제 Sequelize를 사용하여 SELECT를 사용해보겠습니다. 유저 리스트를 가져오는 query는 다음과 같습니다.
User 테이블에 있는 모든 row를 가져오는 query입니다. Sequelize는 결과를 Promise로 리턴하기 때문에 findAll 메서드 역시 Promise를 리턴합니다. 따라서 query의 결과는 then에서 받고, catch문에서 상황에 맞게 error 처리(handling)를 하면됩니다.
C++, Java와 같은 클래스 기반 객체지향 언어와 달리 자바스크립트는 프로토타입 기반 객체지향 언어입니다. 프로토타입을 사용하여 객체지향을 추구하기 때문에 자바스크립트를 사용함에 있어 프로토타입을 이해하는 것은 중요합니다. 최근 ECMA6 표준에서 Class 문법이 추가되었지만 C++, Java에서 말하는 클래스가 아닌 프로토타입을 기반으로 하여 만들어진 문법입니다.
자바스크립트의 프로토타입을 처음 공부하면서 prototype, [[prototype]], _proto_, 객체, 함수, prototype chain 과 같은 용어들을 접하게 되는데 공부할수록 서로 뒤엉켜지고, 모르는 것도 아닌 그렇다고 제대로 알고 있는것도 아닌 어중간한 상태가 됩니다.
자바스크립트를 사용한 경험이 있으시다면 아래의 코드와 같은 형태를 경험한적이 있으실겁니다. 지금부터 아래의 코드가 어떤 원리로 동작하게 되는지 알아보겠습니다.
먼저 프로토타입에 대해 이해하기 위해서는 객체(object)는 함수(function)로부터 시작된다라는 것을 알아야 합니다. 이는 prototype을 이해하는데 많은 도움을 줍니다.
객체(object)는 함수(function)로부터 시작된다
자바스크립트에서 primitive를 제외하고는 모두 객체(object)입니다. 앞으로 등장하는 Object와 Function은 function(즉, 생성자)입니다. object는 객체를 의미합니다.
다음의 코드를 분석하기 전 객체(object)는 함수(function)로부터 시작된다라는걸 다시한번 기억하겠습니다.
1 2
functionBook() { } // 함수 var jsBook = new Book(); // 객체 생성
위의 코드에서 Book이라는 함수를 통해서 jsBook이라는 객체를 생성했습니다. 이때 Book 함수를 생성자라고 합니다. 생성자는 새로 생성된 객체를 초기화하는 역할을 합니다. 코어 자바스크립트는 기본 타입에 대한 생성자를 내장하고 있는데 이는 다음 코드를 통해 확인이 가능합니다.
1
var cssBook = {}; // 생성자 선언 없이 객체 생성
위에서는 리터럴 방식을 사용하여 객체를 생성하였습니다. 리터럴 방식 또한 결과적으로는 함수를 통하여 객체를 생성하게 됩니다. 자바스크립트 엔진이 해당 리터럴을 다음과 같이 해석합니다.
1
var cssBook = newObject(); // 객체 생성
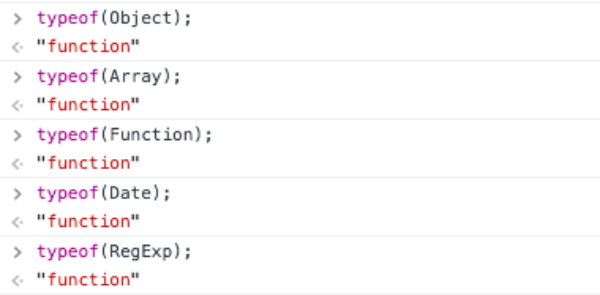
따라서 결과적으로는 리터럴 방식으로 객체를 생성할때도 Object라는 함수(생성자)를 통해서 객체를 생성하게 됩니다. Object 뿐만 아니라 Array, Function, Date, RegExp 모두 함수입니다.
배열도 객체이기 때문에(자바스크립트 배열은 객체의 특별한 형태입니다. 프로퍼티 이름이 정수로 사용되며, length 프로퍼티를 가집니다.) 객체를 생성할때와 마찬가지로 배열(객체)의 생성에도 함수가 관여하게 됩니다. 따라서 무심코 사용했던 배열의 리터럴 표현도 결국에는 자바스크립트 엔진이 다음과 같이 해석합니다.
1 2 3
var books = ['html', 'css', 'js']; // 배열(객체) 생성 // 엔진이 다음과 같이 해석합니다. var books = newArray('html', 'css', 'js'); // 배열(객체) 생성
이제 객체(object)는 함수(function)로부터 시작된다라는 것을 알 수 있습니다.
함수(function) 생성시 발생하는 일
객체(object)는 함수(function)로부터 시작되기 때문에 사용자가 객체를 생성하기 위해 먼저 함수를 정의하게 됩니다. 이때 발생하는 일에 대해 알아보겠습니다. 여기서는 2가지를 기억해야 합니다.
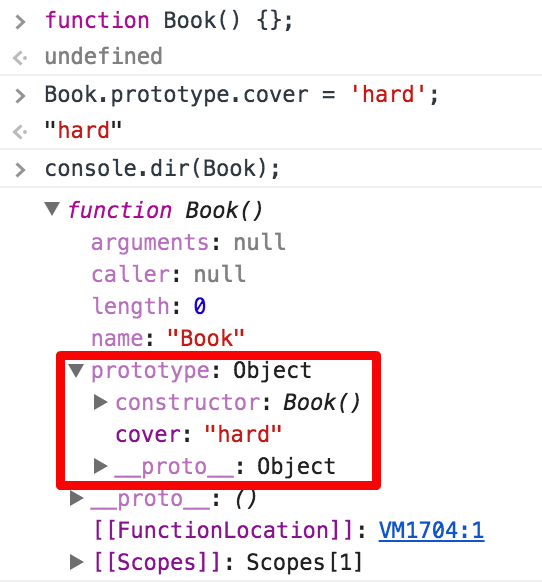
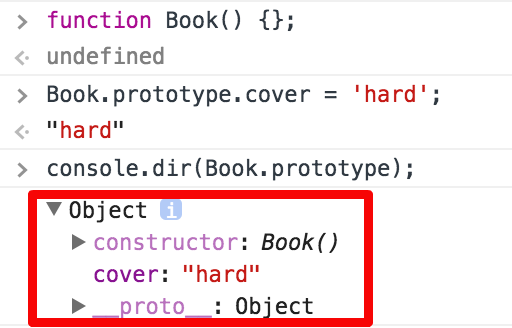
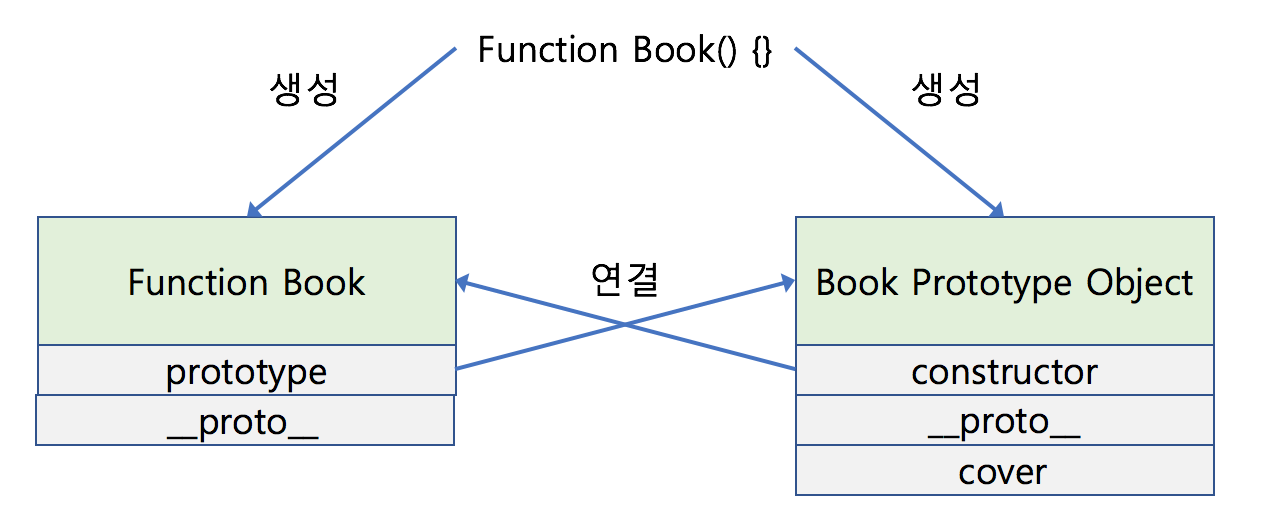
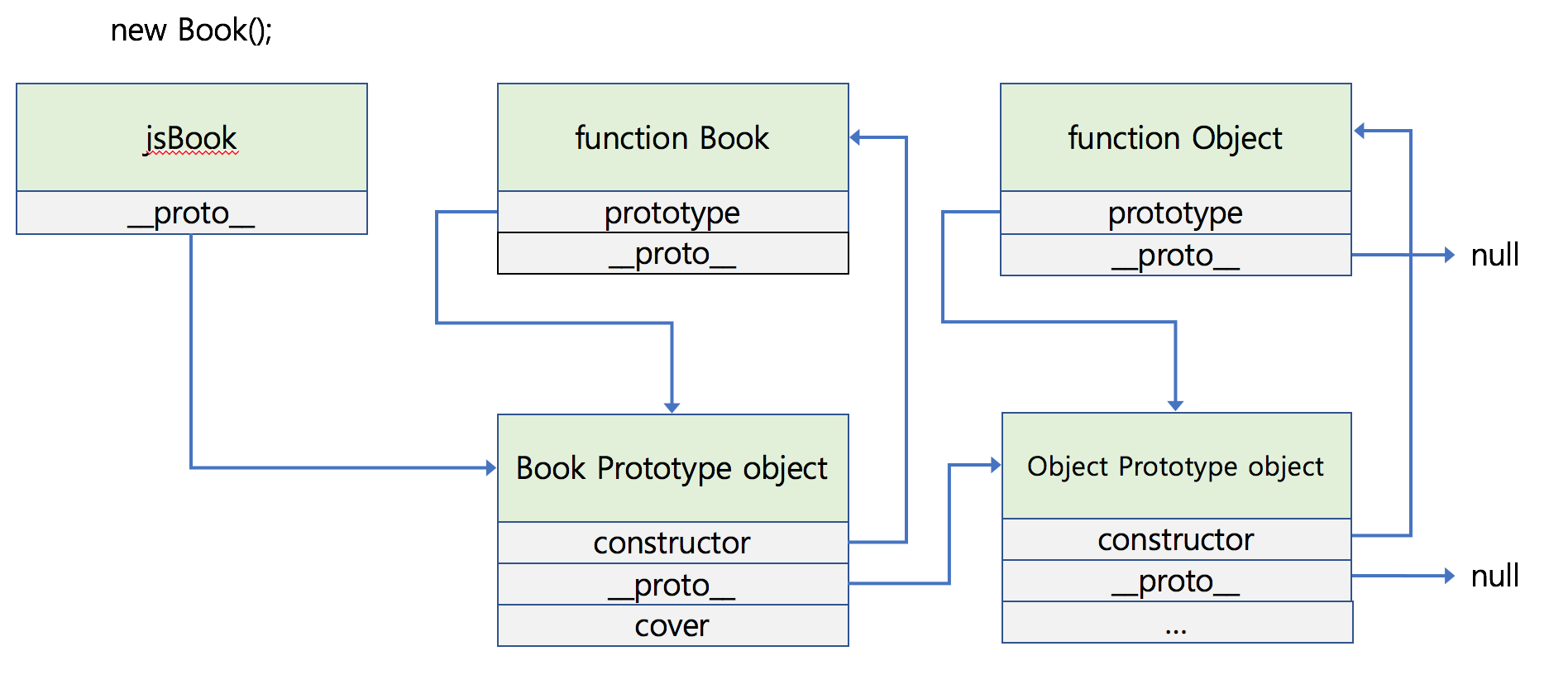
1.함수를 정의하면 함수가 생성되며 Prototype object가 같이 생성 됩니다. 생성된 Prototype object는 함수의 prototype 속성을 통해 접근할 수 있습니다. (Prototype object같은 경우 함수 생성시에만 됩니다. 일반 객체 생성시에는 생성되지 않습니다.)
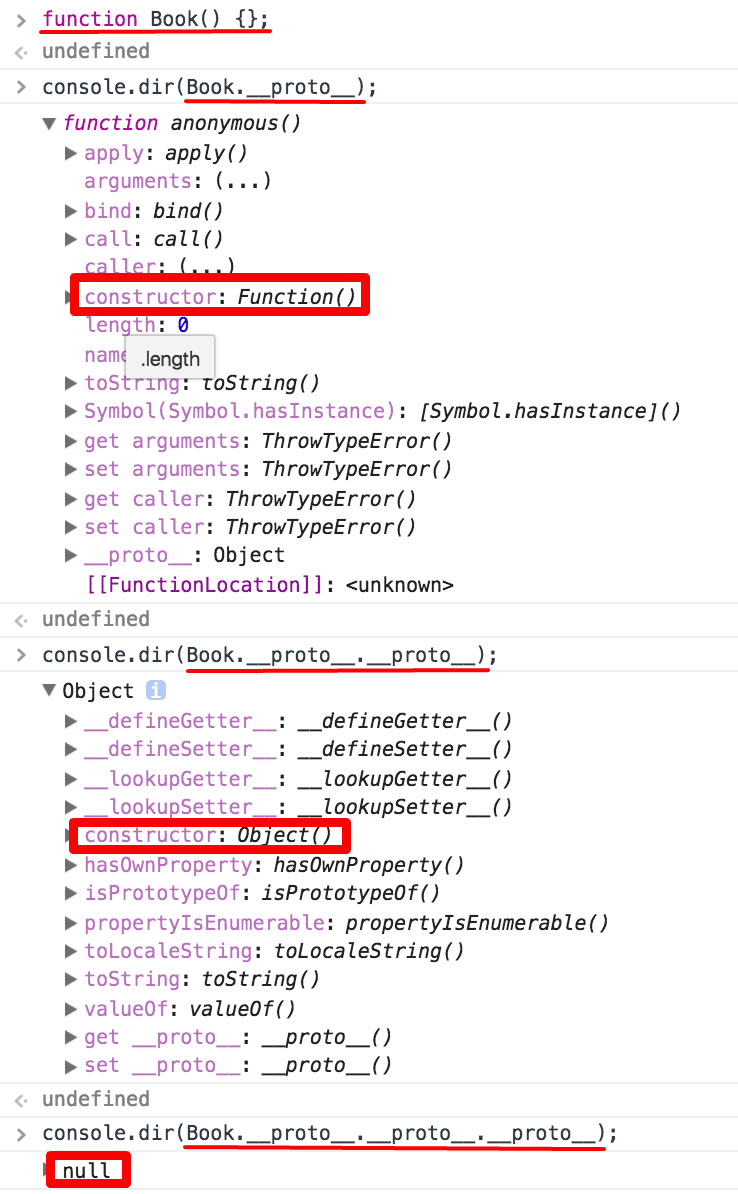
2.함수의 생성과 함께 생성된 Prototype object는 constructor와 __proto__를 갖고 있습니다. (cover property를 추가한것 처럼 사용자 임의로 추가 가능합니다.) constructor는 생성된 함수를 가리키며(여기서는 function Book을 가리킵니다.) **_proto_**는 Prototype Link로서 객체가 생성될 때 사용된 생성자(함수)의 Prototype object를 가리킵니다. Prototype Link는 뒤에서 자세하게 알아보겠습니다.
다이어그램을 통해 확인하면 다음과 같습니다.
객체(object) 생성시 발생하는 일
이번에는 객체 생성시 발생하는 일에 대해 알아보겠습니다. 조금 전에 정의한 Book 함수(생성자)를 사용하여 jsBook이라는 객체를 생성해 보겠습니다.
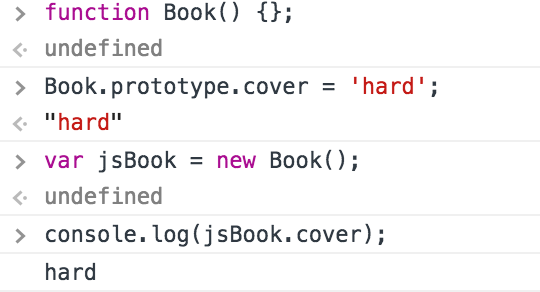
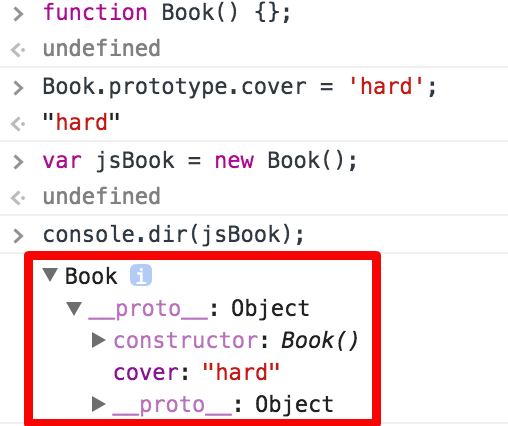
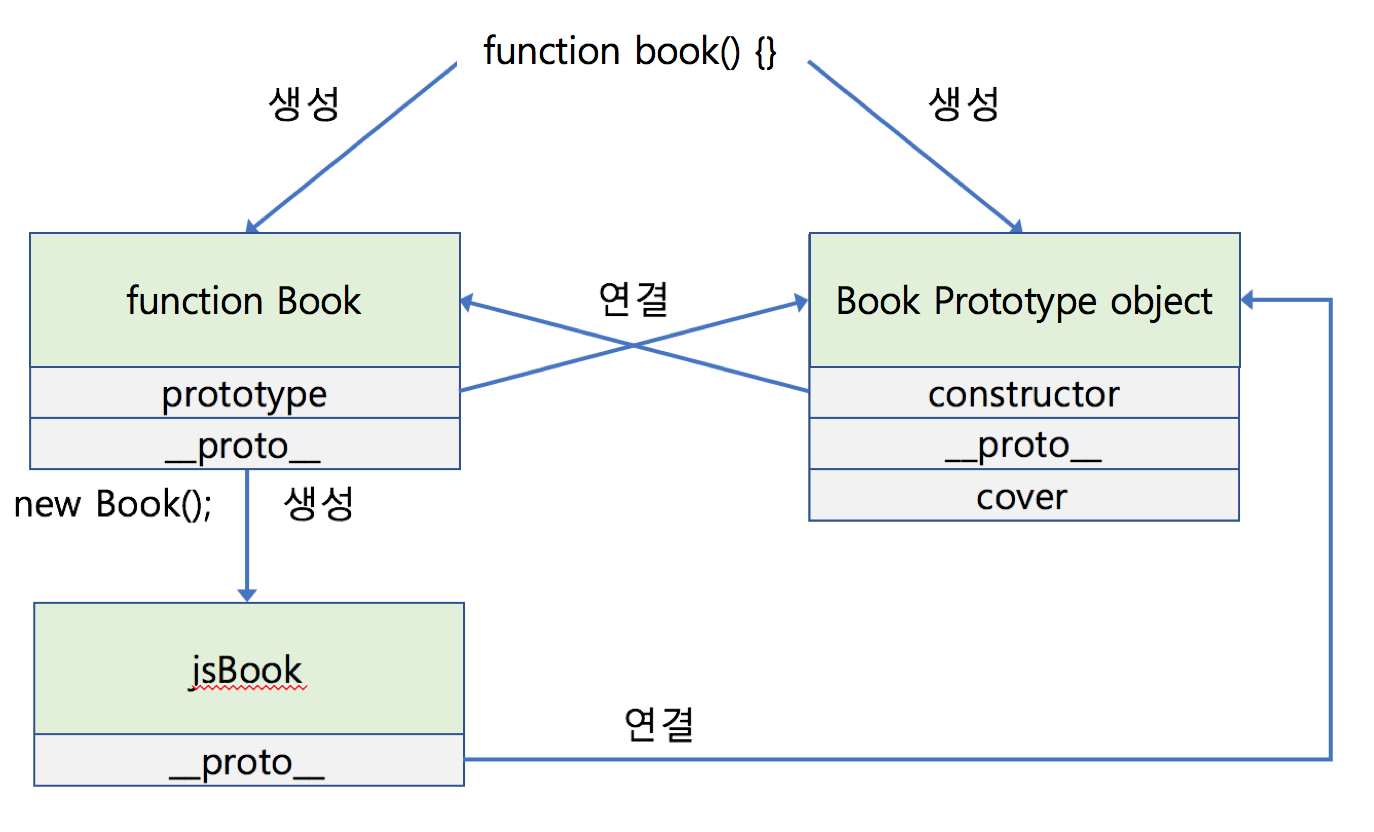
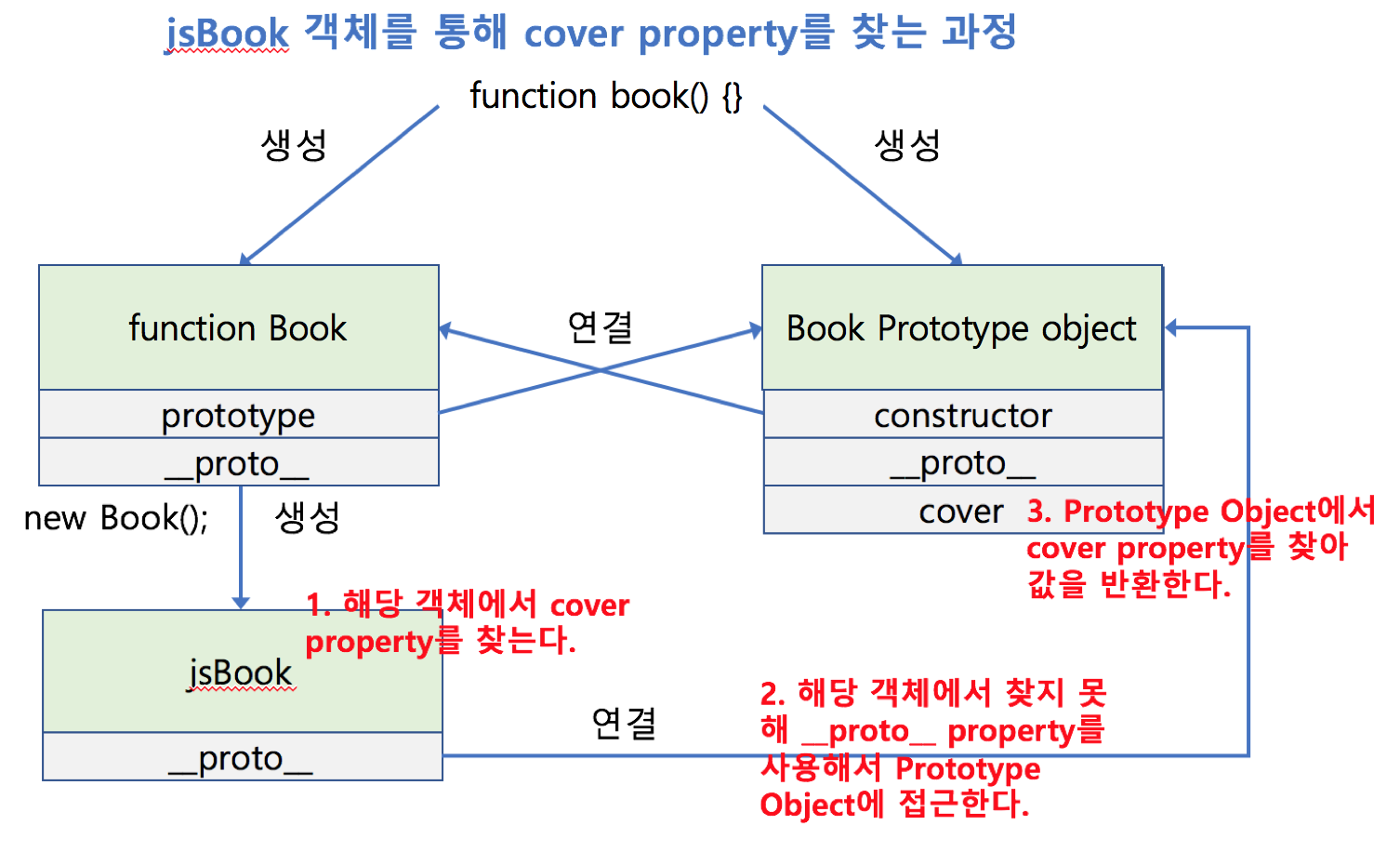
생성자(함수)의 몸체 부분에 어떠한 코드도 작성하지 않았는데 이를 통해 생성한 jsBook 객체가 __proto__라는 프로퍼티를 갖고있습니다.
여기서 _proto_ 는 Prototype Link로서 **객체의 생성에 쓰인 생성자 함수의 Prototype object**를 가리키고 있습니다. 그렇기 때문에 Book 생성자 함수와 함께 생성된 Prototype object에 추가한 cover라는 프로퍼티가 보이는것을 확인할 수 있습니다.
조금 더 이해하기 쉽게 다이어그램으로 확인하면 다음과 같습니다.
다이어그램에서도 확인할 수 있다시피 prototype property(함수 생성시 함께 생성된 Prototype object를 가리킴)는 함수객체만 가지며 __proto__는 객체라면 모두 갖고 있습니다.
이제 프로토타입 체인(Prototype Chain)에 대해 이해할 수 있는 준비가 되었습니다.
프로토타입 체인(Prototype Chain)
결론부터 말씀드리면 프로토타입 체인은 객체의 property를 사용할때 해당 property가 없다면, __proto__ property를 이용해 자신의 생성에 관여한 함수(생성자 함수)의 Prototype object에서 property를 찾습니다. 만약 Prototype object에도 해당 property가 없다면 다시 Prototype object의 _proto_ property를 이용해 Prototype object에서 property를 찾습니다. 이렇게 계속 반복이 이루어지며 해당 property를 찾게 된다면 값을 반환하고 찾지 못한다면 undefined를 반환합니다. 이렇게 __proto__ property를 통해 상위 프로토타입과 연결되어 있는 형태를 프로토타입 체인(Chain)이라고 합니다.
프로토타입 체인에 대해 알게되었으니 다시한번 처음 코드를 살펴보겠습니다.
이제 어떻게 jsBook에 cover라는 property를 추가하지 않았는데도 결과가 출력되는지 이해할 수 있습니다. 다음과 같이 동작할 것입니다.
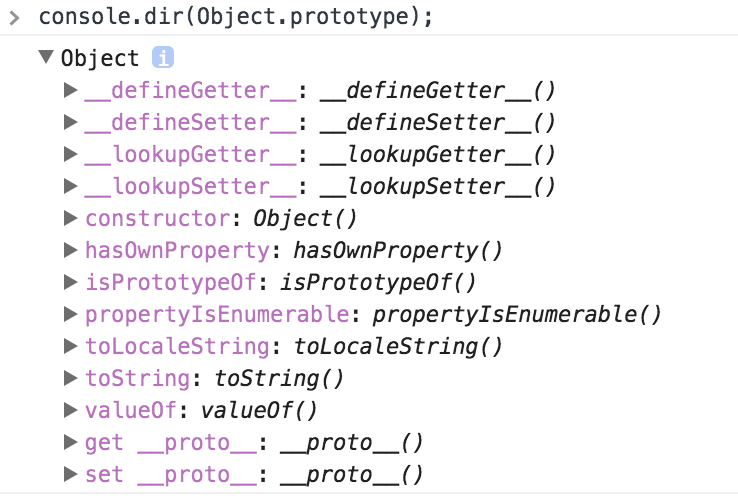
또한 다음과 같이 프로토타입 체인의 최상위는 Object이기 때문에 Object.prototype의 property들을 모두 사용할 수 있습니다. 자주 사용하는 toString()과 valueOf() 모두 Object.prototype에 선언되어 있습니다. (Book Prototype object는 객체이기 때문에 Object 생성자가 사용될 것입니다. 따라서 Book Prototype object의 **_proto_**는 Object Prototype object를 가리키게 됩니다.)
Prototype object와 __proto__ 그리고 프로토타입 체인에 대해 이해하였으니 다음과 같은 코드도 이해할 수 있습니다. 잘 이해가 되지 않는다면 위의 다이어그램을 참고해보시기 바랍니다.
번외
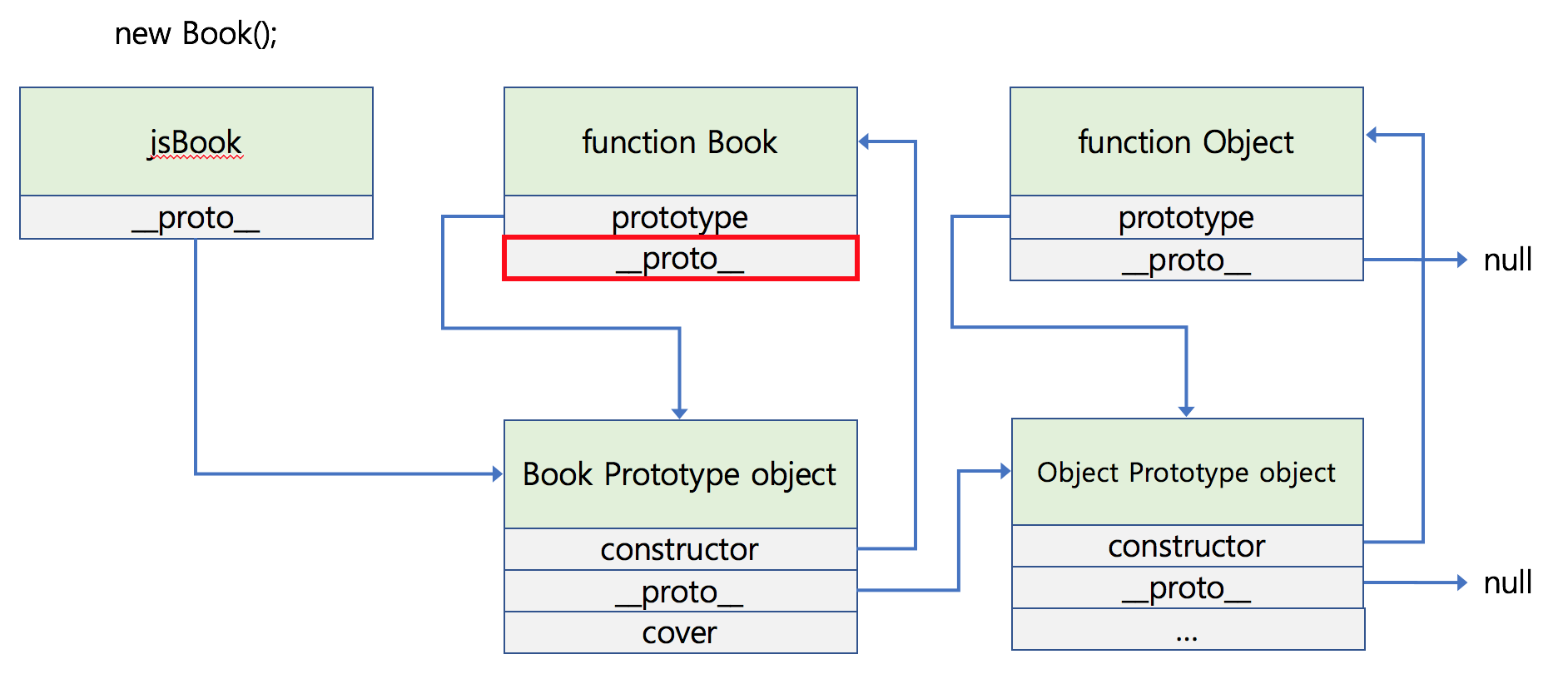
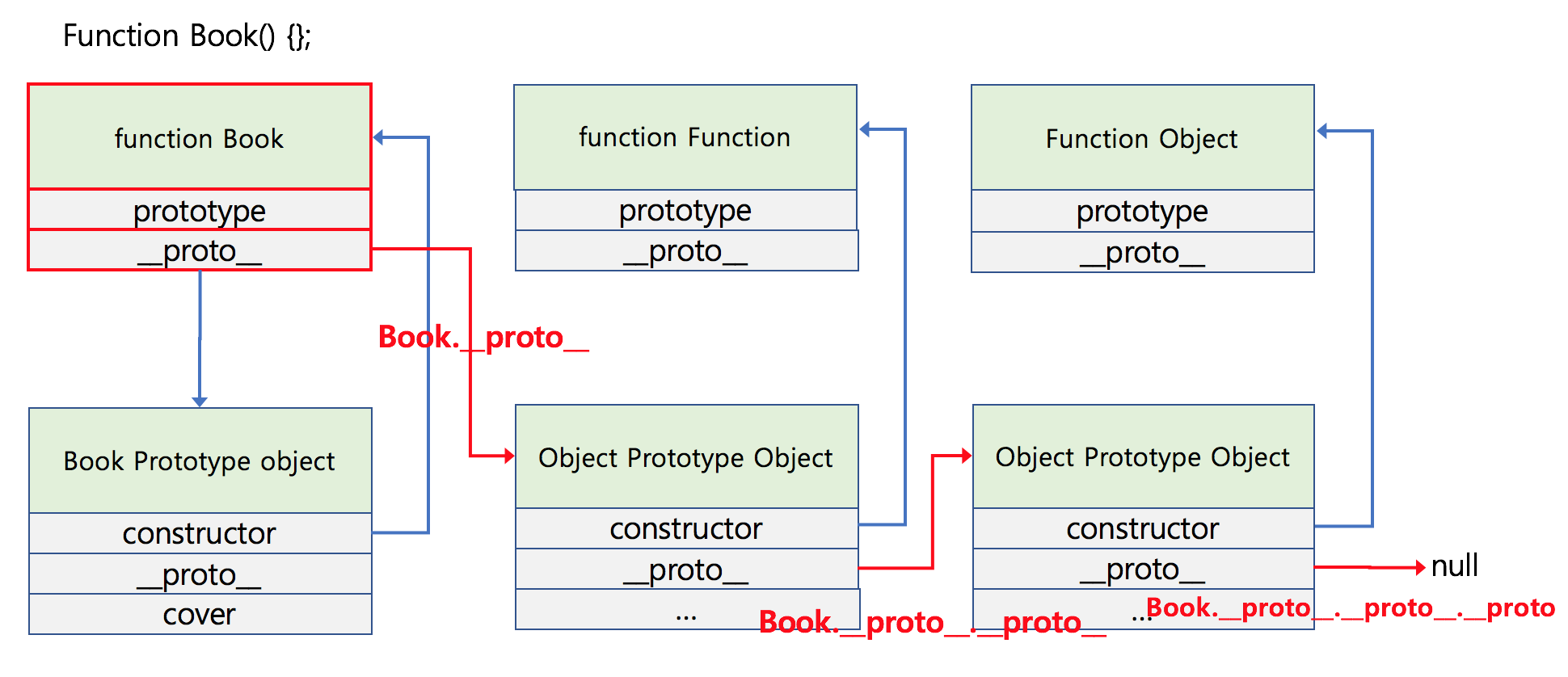
혹시 다이어그램을 보면서 function Book의 _proto_ 는 무엇을 가리키고 있는지 궁금해 하셨을 분들을 위해 추적해보았습니다.
다음 코드를 도식화 하면 다음과 같은 다이어그램이 나오게 됩니다.
간단하게 포스팅을 하려했는데 주제가 주제인지라 길어졌습니다. 저도 프로토타입을 처음 공부하면서 어려움을 많이 겪었는데 조금이나마 도움이 되었으면 좋겠습니다.
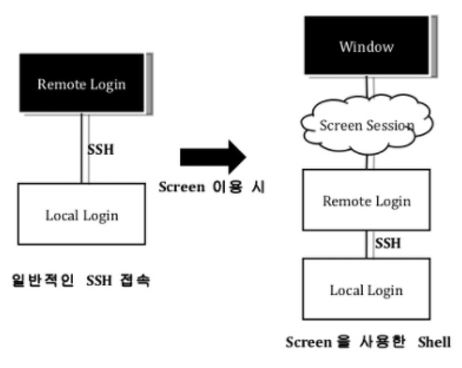
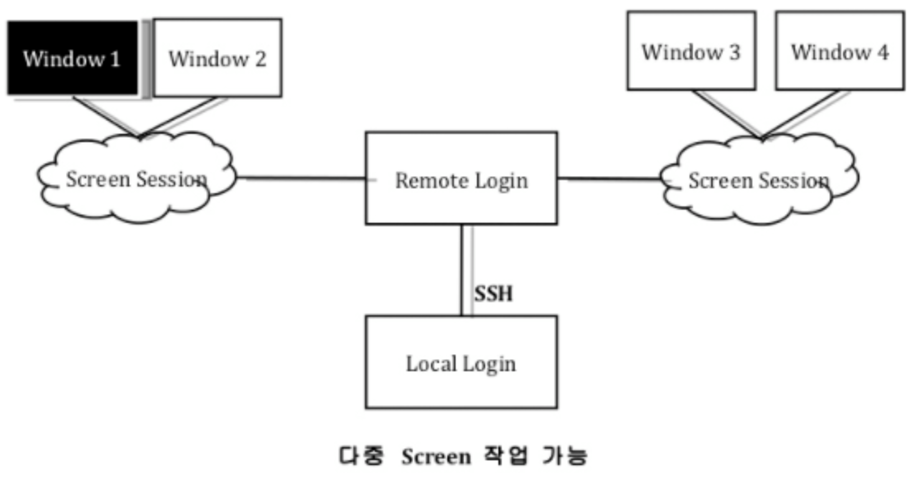
terminal 또는 putty를 이용해 원격에서 작업하다 보면 여러개의 창을 띄우고 싶을 때가 많습니다. 이럴때 보통 여러개의 terminal을 띄워서 작업합니다. (저는 screen을 알기 전까지 그랬습니다…) 그런데 창을 하나, 둘 여러개 띄우고 작업을 하다보면 어느 창에서 어떤 작업을 하고 있었는지도 헷갈리기 시작하면서 관리의 어려움이 생기게 됩니다.
**screen**은 한 terminal로 한번만 로그인 한 후에 여러 쉘과 프로그램을 사용할 수 있습니다. 또한 **세션관리 기능**도 지원합니다. 세션관리 기능은 상당히 유용합니다. 예를 들면, 터미널을 통해 원격 서버에 접속하여 작업을 하다가 네트워크 장애로 연결이 끊어진다면 매우 난감할 수 있습니다. 이때 screen을 사용해서 작업중이 였다면 **세션을 유지**할 수 있기 때문에 해당 작업은 로컬에서 계속 진행되고 있으며 언제든지 다시 해당 세션을 통해 작업을 계속 할 수 있습니다. 더불어 하나의 서버에 여러명의 사용자가 접속하여 **해당 스크린을 공유**하여 같은 화면을 공유할 수도 있습니다.
screen은 하나의 프로세스 입니다. 따라서 무분별하게 생성하기 보다는 필요한 용도에 맞게 적당한 개수를 유지하며 사용하는것이 중요합니다.
Screen 실행 명령어
screen 관련 명령어에 대해 알아보겠습니다.
1 2
// screen 을 시작하는 기본 명령어 입니다. 기본 세션명으로 시작합니다. $ screen
1 2
// 해당 세션명으로 스크린을 시작합니다. $ screen -S 세션명
1 2
// 이전에 작업 했던 screen 목록을 불러와 세션명과 함께 보여 줍니다. $ screen -list
1 2 3
// 이전에 작업 했던 세션이 있을 경우 해당 세션을 불러옵니다. // 세션명을 주지 않았을 경우에는 이전 세션이 한개일 경우 그 작업을 불러오고, 여러개 일 경우에는 작업 리스트를 보여 줍니다. $ screen -R 세션명
1 2
// 스크린을 삭제합니다. $ screen -S 세션명 -X quit
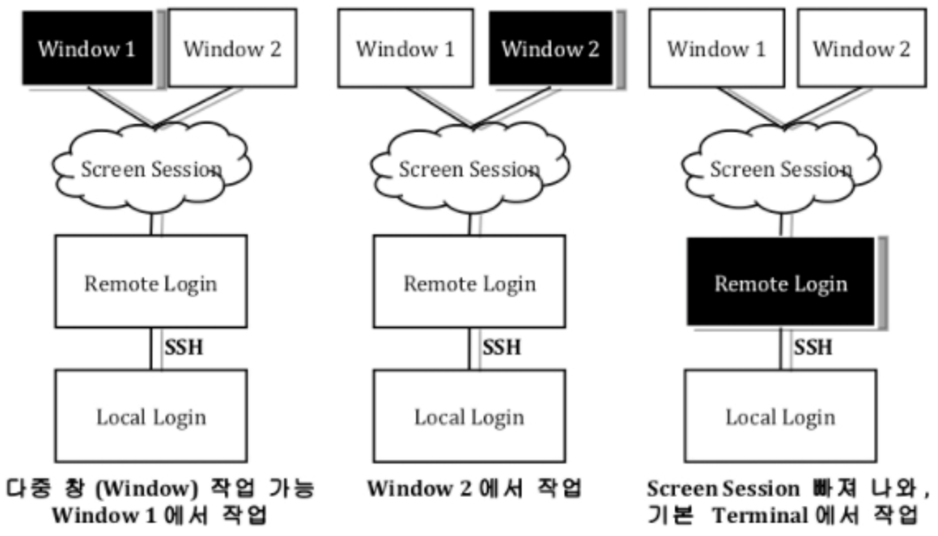
Screen 실행 후 명렁어
Screen 실행 후의 명령어는 **Ctrl-a로 시작**합니다.
1 2
// 새로운 쉘을 생성(create) 하여 그 쉘로 이동합니다. $ Ctrl-a, c
1 2
// 바로 전(previous) 창으로 이동합니다. $ Ctrl-a, p
1 2
// 바로 다음(next) 창으로 이동합니다. $ Ctrl-a, n
1 2
// 숫자에 해당하는 창으로 이동합니다. $ Ctrl-a, 숫자
1 2
// 창번호 또는 창이름으로 이동합니다. (' => 싱글 쿼테이션) $ Ctrl-a, '
1 2
// 창목록을 보여 줍니다. (방향키와 Enter를 통해 창 선택 후 이동가능, " => 더블 쿼테이션) $ Ctrl-a, "
1 2
// 현재 창의 title을 수정합니다. $ Ctrl-a, A
1 2
// screen의 명령행 모드로 전환합니다. (: => 콜론) $ Ctrl-a, :
1 2
// 현재 작업을 유지하면서 screen 세션에서 빠져나옵니다.(detach) 세션이 종료 되지 않습니다. $ Ctrl-a, d
1 2
// 해당 스크린을 삭제합니다. $ Ctrl-a, k
1 2
// 해당 스크린에 lock을 겁니다. (해당 유저의 비밀번호를 입력해야 해제할 수 있다.) $ Ctrl-a, x
공부하고 반복해서 복습하고 마지막에는 스스로 정리해보는 시간을 갖는것이 스스로에게 많은 도움이 되는것 같습니다. 그래서 이번에는 **ReactNative에서 Redux를 사용하기**라는 주제로 포스팅을 하려합니다. Flux에서 Redux 그리고 ReactNative까지 정말 자세하고 친절하게 설명해주신 분들이 많습니다. 제가 공부하며 참고했던 좋은 글들과 강의는 React Native 글 모음에 따로 정리를 하였습니다. 이 글에서는 제가 그동안 Redux 공부하며 이해가 잘 되지 않았던 부분들에 중점을 맞춰서 정리해보고 React Native에 Redux를 적용시키는 것으로 마무리하려 합니다. 아직은 Redux에 대해 잘 안다고 말할 수 없지만, 이번 기회로 정리하며 다시 다잡으려 합니다. 혹시나 제가 잘못이하거나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Flux와 Redux
Redux의 시작은 Flux
Redux는 페이스북에서 MVC 패턴의 단점을 보완하고자 만든 아키텍처인 Flux의 구현체중 하나입니다. Flux의 구현체는 Redux 외에도 Reflux, rx-flux 등… 여러 구현체가 있지만 그중 Redux가 가장 널리 사용되고 있습니다.
저는 Redux를 처음 접했을때 Flux와 많이 혼동했습니다. Redux와 Flux의 구성 요소와 역할에 대해 혼란스러웠고 정리가 잘 되지 않았는데 이는 Redux와 Flux의 다른점에 대해 집중하지 않았기 때문입니다. Redux는 Flux와 마찬가지로 애플리케이션의 상태를 예측 가능하게 합니다. 그러나 Redux는 Flux와 다른 특징이 있습니다. 바로 **핫 리로딩(hot reloading)**과 **시간 여행 디버깅(time travel debugging)**입니다. 이 두가지의 특징으로 인해 Redux는 Flux의 구성요소에는 없는 리듀서(reducer)가 생겨나고, 스토어(Store)의 역할이 조금 변하게 됩니다.
리듀서(Reducer)
Flux에서 스토어는 (1) 상태 변환을 위한 로직, (2) 현재 애플리케이션의 상태를 포함하고 있습니다. 스토어가 이 두 가지를 모두 갖고 있기 때문에 핫 리로딩시 문제가 발생합니다. 상태 변환을 위한 로직을 수정하기 위해 스토어 객체를 리로딩하면 스토어에 저장된 기존의 상태와 뷰를 비롯한 나머지 시스템과의 이벤트 구독이 사라지게 되어 문제가되기 때문입니다. 이를 해결하기 위해 Redux에서는 리듀서(reducer)가 새로운 구성요소로 추가됩니다.
리듀서는 스토어가 갖고 있던 상태 변환을 위한 로직을 대신 갖게됩니다. 따라서 스토어는 액션이 발생했을 때 어떤 상태 변화를 만들어야 하는지 알기위해 리듀서에게 요청합니다. 이렇게 기존 스토어에서 상태 변환을 위한 로직이 분리되었기 때문에 이제 핫 리로딩이 가능하게 됩니다.
리듀서는 첫 번째 인수로 기존 상태의 값 두 번째 인수로는 액션을 가집니다. 리듀서를 작성할 때는 주의사항이 있는데, 첫 번째 인수로서 기존 상태를 갖고 있는 state는 수정하지 않고 상태를 수정할 때는 새롭게 생성하여야 합니다. 이 주의사항으로 지킴으로써 각각의 액션이 발생할 때마다 새로운 상태의 객체가 생성되어 결과적으로는 Redux의 특징인 시간 여행 디버깅이 가능하게 됩니다.
스토어(Store)
Redux의 스토어는 Flux의 스토어와는 다소 차이가 있습니다. 먼저 Flux에서는 다수의 스토어를 가질 수 있었고, 각 스토어는 자신의 범위에 있는 애플리케이션의 상태를 변환할 수 있는 로직을 포함하고 있었습니다. 그러나 Redux는 하나의 스토어만을 가집니다. 또한 Redux의 스토어는 상태 트리(state tree) 전체를 유지하는 책임을 가지며, Flux의 디스패쳐(dispatcher)의 역할도 대신합니다.(Flux의 디스패쳐는 모든 스토어를 갖고 있고, 액션 생성자로부터 액션을 넘겨받으면 스토어에 전달합니다.) 따라서 Redux에서는 스토어에서 제공하는 dispatch 함수로 디스패쳐의 동작을 대신합니다.
Redux 구성요소
지금까지 Flux와 Redux의 차이점과 그로 인해 Redux가 가질 수 있게된 특징에 대해 알아보았습니다. 지금부터는 Redux의 구성요소를 살펴보겠습니다.
액션(Action)
액션은 애플리케이션의 상태를 갖고 있는 스토어로 전달하는 데이터 묶음입니다. store.dispatch() 를 통해 스토어에 액션을 전달할 수 있습니다.
액션은 평범한 자바스크립트 객체이며, type 속성을 갖고 있습니다. 이 type 속성은 액션을 전달받은 스토어가 애플리케이션의 상태변환 로직을 갖고 있는 리듀서를 참조할때 사용하게 됩니다.
액션 생성자(Action Creator)
액션 생성자는 액션을 만드는 함수입니다. Flux에서는 함수 내부에서 dispatch 함수를 통해 액션을 전달하지만 Redux의 액션 생성자는 단지 액션을 반환하기만 합니다. 실제 액션을 전달할때는 결과값을 dispatch 함수에 전달하거나 생성된 액션을 자동으로 보내주는 바인드된 액션 생성자를 만듭니다.
리듀서(Reducer)
액션은 무언가 일어나 상태가 변할것이라는 사실을 말할뿐, 그 결과 실제 애플리케이션의 상태가 어떻게 바뀌는지는 리듀서가 담당합니다. 리듀서는 이전 상태와 액션을 받아서 다음 상태를 반환하는 역할을 하는 순수 함수입니다. 따라서 항상 다음 상태를 계산해서 반환하는 역할만 합니다. API 호출이라던가, Date.now()나 Math.random() 과 같은 순수하지 않은 함수를 호출하는 일은 해서는 안됩니다.
Redux는 처음에 리듀서를 undefined 상태로 호출하여 초기 상태를 반환합니다. 리듀서는 서로 독립적으로 수행된다면 분리될 수 있고, 이 분리된 리듀서는 *루트 리듀서라는 하나의 객체로 조합될 수 있습니다. 결과적으로 처음에 undefined 상태로 호출되면 각각의 자식 리듀서들이 초기 상태를 반환하게 되고, 각각의 리듀서는 전체 상태에서 자신의 부분만을 관리합니다. 모든 리듀서의 state 매개변수는 서로 다르고, 자신이 관리하는 상태 부분에 해당합니다.
스토어(Store)
스토어는 “무엇이 일어날지”를 표현하는 액션과 이 액션에 따라 애플리케이션의 상태를 어떻게 수정할지를 나타는 리듀서를 함께 가져오는 객체입니다. 스토어는 다음과 같은 일들을 합니다.
애플리케이션의 상태를 저장
getState()를 통해 상태에 접근
dispatch(action)을 통해 상태를 수정할 수 있게 함
subscribe(listener)를 통해 리스너를 등록
Redux의 스토어는 Flux와는 달리 하나의 스토어만을 가질 수 있기 때문에 데이터를 다루는 로직을 나누고 싶다면 여러개의 리듀서를 조합하여 대신할 수 있습니다.
뷰 레이어 바인딩(The view layer binding)
뷰 레이어 바인딩은 생성된 스토어를 뷰에 연결하기 위해 필요합니다. 뷰 레이어 바인딩은 connect() 을 통해 컴포넌트(뷰)가 애플리케이션의 상태 업데이트를 받을 수 있도록 모든 연결을 만들어줍니다.
루트 컴포넌트(Root component)
모든 React 애플리케이션은 루트 컴포넌트를 가집니다. 루트 컴포넌트는 계층 구조에서 가장 위에 위치하는 컴포넌트이며, 스토어를 생성하고 어떤 리듀서를 사용할지 알려주며 뷰 레이어 바인딩과 뷰를 불러옵니다.
Redux 사용 준비
애플리케이션을 생성하며 Redux의 구성요소들이 서로 연결됩니다.
**combineReducers()**를 통해 다수의 리듀서를 하나로 묶은 후 루트 컴포넌트가 **createStore()**를 이용해 스토어를 생성할때 전달합니다.
루트 컴포넌트는 공급 컴포넌트와 스토어 사이를 연결함으로써 스토어와 컴포넌트 사이의 커뮤니케이션을 준비합니다. (이후 컴포넌트에서 connect()를 통해 상태 업데이트를 받을 수 있습니다.)
Redux 데이터 흐름
Redux의 아키텍쳐는 엄격한 일방향 데이터 흐름에 따라 전개되며 데이터의 흐름은 4단계에 따라 진행됩니다.
1. 액션 생성 후 스토어에 전달 액션은 무언가 일어나 상태가 변할 것이라는 내용을 담고 있는 객체입니다. 액션 생성자를 통해 액션을 생성한 후 store.dispatch(action)을 통해 스토어에 전달합니다.
2. 스토어가 리듀서를 호출 스토어는 리듀서에 현재의 상태 트리와 전달받은 액션을 두 가지 인수로 전달합니다.
3. 루트 리듀서가 각 리듀서의 출력을 합쳐 하나의 상태 트리 생성 각각의 상태를 다루는 리듀서에 의해 생성된 결과를 하나로 합쳐 루트 리듀서가 하나의 상태 트리를 생성합니다.
4. Redux 스토어가 루트 리듀서에 의해 반환된 상태 트리를 저장 새로운 상태 트리가 앱의 다음 상태입니다. store.subscribe(listener)를 통해 등록된 모든 리스너가 불러내지고 이들은 현재 상태를 얻기 위해 store.getState()를 호출합니다. connect()를 통해 컴포넌트에 스토어가 연결되어 있다면 컴포넌트는 이를 반영하고 자신의 setState()나 forceUpdate() 메소드를 실행해 자동적으로 render() 메소드를 호출합니다.
React Native에서 Redux 사용하기
이제 React Native에서 Redux를 사용해보겠습니다. React Native를 위한 개발환경 설정은 공식홈페이지를 참조하시기 바랍니다. 이 예제 프로젝트에서는 간단하게 Redux를 사용하는 법에 초점을 맞춰 진행해보겠습니다. 간단히 카운팅하는 앱을 만들어보려 합니다. 완성 화면은 다음과 같습니다.
프로젝트 생성
먼저 React Native 프로젝트를 생성합니다. (현재 버전은 0.41.2 입니다)
1
react-native init example
다음으로 redux를 사용하기 위해 필요한 모듈들을 설치합니다.
1
npm install redux react-redux --save
이제 Redux의 구성요소를 참고하여 다음과 같이 새로운 폴더 구조를 생성합니다. (앞으로 사용할 폴더와 파일만 명시하였습니다.)
이제 Count.js 파일을 작성하여 Count 컴포넌트를 생성하겠습니다. Count 컴포넌트는 현재 카운트 되고 있는 숫자를 보여주는 텍스트와 카운트를 증가시키는 버튼으로 구성됩니다.
Count 컴포넌트를 app.js에서 사용합니다.
Count 컴포넌트를 추가한 후 화면입니다.
Count 액션 생성
액션은 애플리케이션의 상태를 갖고 있는 스토어로 전달하는 데이터 묶음이라고 했습니다. 이 카운팅 앱에서는 액션 객체의 type을 통해서 증가인지 감소인지, payload를 통해서는 증가 혹은 감소할 값을 전달할 것입니다.
먼저 actions/types.js를 작성합니다. types.js 에는 액션의 타입으로 사용될 값을 상수로 정의합니다. 타입은 후에 리듀서에서도 사용되기 때문에 미리 상수로 정의하는것이 실수를 줄일수도 있고, 후에 액션을 관리하는데에도 유용합니다.
이제 countAction.js를 작성합니다. type과 payload로 이루어진 액션 객체 액션 생성자를 통해 생성되어 스토어로 전달됩니다.
마지막으로 index.js를 작성합니다. index.js 에서는 여러개의 액션을 하나의 객체로 묶어 컴포넌트 파일에서 쉽게 사용할 수 있도록 해주는 역할을 합니다.
Count 리듀서 생성
액션을 전달받은 스토어가 상태를 변경하기 위해 리듀서에게 어떠한 상태변환을 해야하는지 요청합니다. 리듀서에서는 이 요청을 처리할 수 있도록 코드를 작성해야 합니다. countReducer.js를 작성합니다. 리듀서는 함수입니다. 첫 번째 인자로 이전의 상태를 전달받고, 두 번째 인자로는 액션을 전달받습니다. 전달 받은 액션의 type을 통해 새로운 상태를 반환하는것이 리듀서의 역할입니다. 애플리케이션 실행 후 Redux는 처음에 리듀서를 undefined 상태로 호출합니다. swtich문에서 default인 상태에서 초기 상태를 설정합니다.
액션과 마찬가지로 index.js를 작성합니다. 여러개의 리듀서를 묶어 컴포넌트 파일에서 쉽게 사용할 수 있도록 해주는 역할입니다. redux 모듈의 combineReducer는 트리 구조로 분리된 여러개의 상태를 하나의 단일 상태 트리로 조합합니다.
루트 컴포넌트에 스토어 연결
생성한 액션과 리듀서를 애플리케이션에서 사용할 수 있도록 루트 컴포넌트에 설정해주어야 합니다. 처음 작성했던 app.js를 다음과 같이 수정합니다. redux 모듈에 있는 createStore를 통해 스토어를 생성할 수 있습니다. store 생성시 인자로 리듀서를 필요로 합니다. 생성된 스토어를 React 에서 사용하기 위해 react-redux 모듈에서 Provider를 사용합니다.
Count 컴포넌트 바인딩
뷰 레이어 바인딩은 생성된 스토어를 뷰에 연결하기 위해 필요하다고 설명했습니다. 이제 생성한 액션과 리듀서를 Count 컴포넌트에서 사용할 수 있도록 connect를 통해 연결을 만들어줍니다. connect 메서드는 Store의 state를 컴포넌트의 props로 전달하고 상태의 변화가 있을 때 자동으로 컴포넌트의 render를 재호출합니다. connect 메서드는 다음의 인자를 가집니다.
mapStateToProps : 스토어의 state를 해당 컴포넌트의 props로 전달(mapping)합니다.
mapDispatchToProps : 스토어의 dispatch를 props에 전달합니다. dispatch를 통해 액션생성자에서 생성한 액션을 스토어로 전달할 수 있습니다.
간단한 카운팅앱이 완성되었습니다. 버튼을 통해 count의 값을 변경할 수 있습니다.
포스팅을 마치며
MVC 패턴에 익숙해져있던 저에게 Redux는 머리로는 이해할 수 있었지만 가슴으로는? 이해기 쉽지 않았었습니다. 이번 기회에 다시 하번 정리를 하며 제가 처음에 혼란스러워했던 부분들을 최대한 설명해드리려 노력했습니다. 위의 예제가 좋은 예제라고는 말할 수 없지만 그래도 React Native에서 Redux가 어떻게 사용되는지 전체적인 구조를 보는데에는 나쁘지 않다고 생각합니다. 액션과 리듀서를 생성하고 사용하는 부분에 있어서는 여러가지의 방법이 있지만 최대한 Redux를 쉽게 이해할 수 있도록 작성해보았습니다. 좀 더 효율적으로 작성하는 법은 다음에 기회가 된다면 포스팅해보겠습니다.