Spring Boot에서의 Bean Validation (2)
해당 포스팅에서 사용된 예제 코드는 spring-boot validation example에서 확인 가능합니다.
해당 포스팅에서 사용된 예제 코드는 spring-boot validation example에서 확인 가능합니다.
Bean Validation은 Java 생태계에서 유효성(Validation) 검증 로직을 구현하기위한 사실상의 표준이다. Bean Validation은 Spring과 Spring Boot에도 잘 통합되어 있다.
여러 대의 DB 서버가 있을 때 각각의 DB 서버가 동일한 데이터를 유지하도록 하는 메커니즘 혹은 기법을 말한다.
Replication(리플리케이션)을 이용해서 백업과 부하분산같은 목적을 달성할 수 있다.
master 서버에 데이터가 기록(쓰기)되고, slave 서버들은 master에 기록된 데이터를 전파받으며 보통 읽기에 사용된다.
정리하면 한대의 master 서버는 쓰기, 여러대의 slave 서버들은 읽기에 사용되는 것이다.
master DB의 데이터가 빠른 속도로 slave DB에 복제되기 때문에 master DB에 문제가 생겼을 때, slave DB를 master DB로 대체해 빠르게 장애를 복구할 수 있다.
그렇지만 Replication 자체가 완전한 백업을 의미하는 것은 아니다. master DB에 의도하지 않은 작업(데이터를 잘못해서 대량으로 삭제)을 수행했을 때 해당 작업이 slave DB에도 전파가 되기 때문에 이러한 것들은 복구가 불가능하다.
그러므로 실시간 성의 백업은 Replication이 담당하고, 시간차를 두고 백업이 필요한 것은 보통 스케쥴링을 통하여 시간 간격을 두고 백업을 하는것이 바람직하다.
읽기와 관련된 부하분산을 할 수 있다는 것이 Replication의 장점이다. 한계라고 하면 쓰기와 관련된 부분인데, 한 대의 master DB에 쓰기가 집중되기 때문에 쓰기 작업에 부하가 많다면 문제가 생길 수 있다.
간략하게 Replication이 동작하는 방식을 확인해보자. 아래 그림은 master DB와 slave DB가 1대1로 연결되어 있는 구조이다.
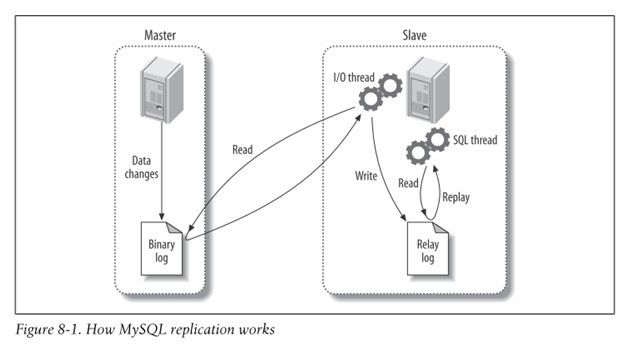
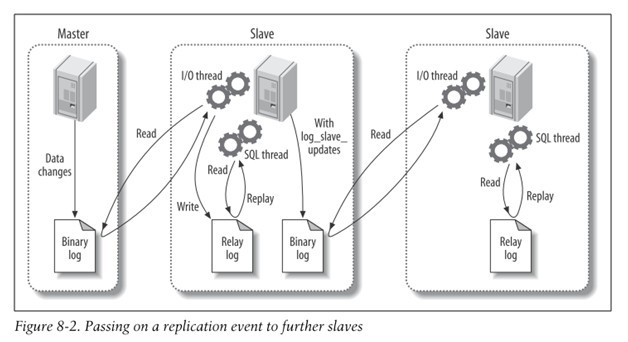
Binary log에 기록한다.I/O thread 이용해 Binary log를 가져온다.Relay log에 변경사항을 기록한다.SQL thread를 이용해 변경사항을 반영한다.아래 그림은 또 다른 구조의 Replication이다. master DB와 slave DB가 존재하고 slave DB에 다시 slave DB가 존재하는 구조이다.
가운데의 slave DB가 master DB 처럼 Binary log를 생성해서 다른 slave에게 전달하는 것이다. 이 경우 가장 마지막에 있는 slave DB가 직접 master DB에 접근하는 것이 아니기 때문에 master DB의 부담을 줄일 수 있다.
또한 가운데의 slave DB 역시 master DB 처럼 Binary log를 생성하고 있기 때문에 master DB에 문제가 생겼을 때, 빠르고 쉽게 master DB로 대체가 가능하다.
그럼 이제 간단하게 MySQL Replication을 구축해보자. 여러 대의 서버에 MySQL을 설치하고 준비하는 것은 번거롭기 때문에 간편하게 도커를 이용해서 진행해보자.
먼저 master DB 컨테이너를 생성하고 접속한다.
1 | docker run --name mysql-master -e MYSQL_ROOT_PASSWORD=asdf1234 -d mysql |
설치한 vim을 이용해 MySQL 설정 파일인 /etc/mysql/my.cnf 파일에 다음의 내용을 추가한다.
1 | [mysqld] |
- log-bin: 업데이트되는 모든 query들을 Binary log 파일에 기록한다는 의미이다.
기본적으로 Binary log 파일은 MySQL의 data directory인 /var/lib/mysql/ 에 호스트명-bin.000001, 호스트명-bin.000002 형태로 생성된다.
이때, log-bin 설정을 변경하면 Binary log 파일의 경로와 파일명의 접두어를 변경할 수 있다. log-bin=mysql 이라 설정하면 mysql-bin.000001, mysql-bin.000002 형태로 Binary log 파일이 생성된다.- server-id: Replication 설정에서 서버를 식별하기 위한 고유 ID값이다. master, slave 각각 다르게 설정해야 한다.
도커 컨테이너(MySQL)를 재시작해서 변경된 설정 파일을 반영한다.
1 | docker restart mysql-master |
변경한 설정이 잘 적용되었는지 확인해보자.
1 | docker exec -it mysql-master /bin/bash |
slave DB에서 접근할 수 있도록 master DB에 User 계정을 생성하고 REPLICATION SLAVE 권한을 부여한다.
1 | CREATE USER 'repl'@'%' IDENTIFIED BY 'replpw'; |
User가 생성되었는지 User 테이블을 확인한다.
1 | USE mysql; |
다음으로, Replication 테스트를 위한 DB와 테이블을 생성한다.
1 | CREATE DATABASE testdb; |
slave DB에서 master DB를 연결하기 전에 master DB의 현재 DB 상태(table과 data)를 slave DB에 그대로 반영하기 위해 dump한다.
1 | docker exec -it mysql-master /bin/bash |
dump된 파일을 slave DB 컨테이너에 옮기기 위해 먼저 로컬 PC로 복사한다.
1 | docker cp mysql-master:dump.sql . |
slave DB 컨테이너를 생성하고 접속한다.
1 | docker run --name mysql-slave --link mysql-master -e MYSQL_ROOT_PASSWORD=asdf1234 -d mysql |
설치한 vim을 이용해 MySQL 설정 파일인 /etc/mysql/my.cnf 파일에 다음의 내용을 추가한다.
slave 서버를 여러 대로 구축하고자 할 때에 각 slave 서버의 server-id는 각각 달라야 한다는 것에 주의하자. (2^32-1 까지 가능하다.)
1 | [mysqld] |
도커 컨테이너(MySQL)를 재시작해서 변경된 설정 파일을 반영한다.
1 | docker restart mysql-slave |
로컬 PC로 복사한 master DB의 dump 파일을 slave DB로 옮긴 후 반영한다.
1 | docker cp dump.sql mysql-slave:. |
다시 mysql에 접속해 testdb DB에 testtable 테이블과 데이터가 생성되어 있다면 정상적으로 dump 파일이 적용된 것이다.
1 | USE testdb; |
이제 마지막으로 slave 서버에서 master 서버와 연동하는 작업만 하면 된다.
그 전에 master DB의 mysql에 한번 더 접속하여 Binary log 파일의 현재 상태를 읽어야 한다. 이 Binary log 파일을 통해 master와 slave의 DB가 동기화되므로 반드시 동일한 로그의 위치를 서로 참조하고 있어야 한다.
1 | docker exec -it mysql-master /bin/bash |
출력된 결과에서 File, Position 필드의 값을 기억하도록 한다.File 은 현재 바이너리 로그 파일명이고, Position 은 현재 로그의 위치를 나타낸다. 앞서 DB와 테이블을 생성한 query가 추가됐으므로 이전에 SHOW MASTER STATUS\G 를 실행했을 때보다 Position 값이 증가했음을 볼 수 있다.
이제 slave 서버의 mysql에 접속하여 master 서버와의 연결에 필요한 변수들을 적절히 설정해주어야 한다.
1 | docker exec -it mysql-slave /bin/bash |
- MASTER_HOST : master 서버의 호스트명
- MASTER_USER : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 이름
- MASTER_PASSWORD : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 비밀번호
- MASTER_LOG_FILE : master 서버의 바이너리 로그 파일명
- MASTER_LOG_POS : master 서버의 현재 로그의 위치
아래의 명령어를 실행해 slave의 상태를 확인해보자.
1 | SHOW SLAVE STATUS\G |
문제 없이 Replication 설정이 완료되었다면 마지막으로 실제 잘 동작하는지 확인해보자.
master DB에서 데이터를 생성하고, slave DB에 복제되어 데이터가 조회되는지 확인한다.
master DB에서 데이터를 생성한다.
1 | docker exec -it mysql-master /bin/bash |
slave DB에서 데이터를 조회한다.
1 | docker exec -it mysql-slave /bin/bash |
“Reactive Streams란 non-blocking과 back pressure를 이용한 asynchronous 스트림 처리의 표준이다.” 라고 지난 글에서 이야기 했다.
이번에는 asynchronous(비동기 처리)에 대해서 이야기해보자.
먼저 아래 간단한 코드를 실행해보자.
1 |
|
subscriber를 publisher에 등록(subscribe)하고 처리(onSubscribe -> request -> next)가 끝나면 exit 로그를 마지막으로 종료된다. 이때 subscriber와 publisher의 진행은 모두 main 스레드에서 진행된다.
즉, subscriber를 등록 후 publisher가 데이터를 push하고 처리할 때까지 main 스레드를 붙잡고 있게 된다.
만약 publisher 혹은 subscriber의 처리가 지연된다면 main 스레드는 더욱 오래 사용해야 할 것이다.
결국 publisher에 subscriber를 등록하면 별도의 스레드에서 진행하고 main 스레드는 계속해서 다른 작업을 진행하기를 원하는 것이다.
먼저 publisher가 main 스레드가 아닌 별도의 스레드에서 동작하도록 만들어보자.
1 | private static Publisher<Integer> publishOn(Publisher<Integer> pub) { |
파라미터로 전달받은 publisher의 subscribe 메서드를 별도의 스레드에서 실행하도록 하는 publisher를 새로 만들어서 반환한다. publishOn 메서드를 기존의 publisher에 적용해 실행하면 다음과 같이 실행결과를 확인할 수 있다.
1 | - 실행결과 |
main 스레드는 바로 해제되어 이후의 일을 진행할 수 있게 되었고 onSubscribe 이후의 처리는 모두 별도의 스레드에서 진행된다.
그러나 아직 “빠른 프로듀서”와 “느린 컨슈머”의 문제가 남아있다. publisher가 데이터를 빠르게 생산하지만 subscriber의 onNext에서 데이터를 소비하는 작업에 시간이 오래 걸리는 경우인 것이다.
이때는 subscriber 또한 별도의 스레드에서 onNext 처리를 하도록 함으로써 해결할 수 있다.
subscriber도 별도의 스레드에서 동작하도록 만들어보자.
1 | private static Subscriber<Integer> subscriberOn(Subscriber<Integer> sub) { |
파라미터로 전달받은 subscriber의 onSubscribe, onNext, onError, onComplete 메서드를 별도의 스레드에서 실행하도록 하는 subscriber를 새로 만들어서 반환한다. subscriberOn 메서드를 기존의 subscriber에 적용해 실행하면 다음과 같이 실행결과를 확인할 수 있다.
1 | - 실행결과 |
이제는 main 스레드는 subscriber를 publisher에 등록(subscribe)까지만 하고 그 이후의 작업은 publisher와 subscriber 모두 별도의 스레드에서 동작하게 되었다.
전체 코드는 다음과 같다.
1 |
|
지난번 Reactive Streams API를 구현한 예제를 바탕으로 간단한 Operator를 만들어보자.
Operator라 함은 Stream의 map연산 처럼 Publisher가 제공하는 data를 가공할 수 있도록 하는 것이다.
먼저 간단한 Publisher와 Subscriber 코드이다.
1 |
|
Publisher -> [Data1] -> Operator -> [Data2] -> Subscriber
위와 같이 Data1을 Data2로 변환하는 Operator를 만들어보자.
1 |
|
mapPub 메서드가 추가되었다. Data를 제공하는 Publisher와 가공에 사용할 Function을 받아 Operator(새로운 Publisher)를 반환한다.
실제 하는 일은 단순하다. 기존 Publisher와 Subscriber를 이어준다.
Operator가 기존 Publisher를 subscribe하고, 받게되는 Subscription을 기존 Subscriber에게 전달한다.
Operator가 하는 일은 기존 Publisher와 Subscriber를 이어주면서, onNext 부분에서 전달받은 Function을 적용해주는 것 뿐이다.
onNext를 제외하고는 Operator 마다 코드가 반복될 수 있기 때문에 해당 부분을 DelegateSub으로 분리해보자.
1 | public class DelegateSub implements Subscriber<Integer> { |
DelegateSub을 사용해서 기존 코드를 다음과 같이 수정할 수 있다. 필요한 onNext 메서드만 오버라이딩해서 사용한다.
1 |
|
이번에는 Publisher로부터 전달받은 Data를 전부 더하는 sum operation을 만들어보자.
기존 Publisher와 Subscriber를 onNext로 이어주지 않고, onComplete이 호출되었을 때, sum 값을 onNext로 전달한 뒤 onComplete을 호출해 종료한다.
1 |
|
reactive-streams.org 에서는 Reactive Streams를 다음과 같이 정의하고 있다.
Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.
Reactive Streams란 non-blocking과 back pressure를 이용한 asynchronous 스트림 처리의 표준이다.
중요한 키워드가 여러개 등장 했는데, 먼저 back pressure에 대해서 알아보자.
Back Pressure는 Reactive Streams에서 가장 중요한 요소라고 할 수 있다. Back Pressure가 등장하게 된 배경을 이해하기 위해서 먼저 옵저버 패턴을 이해하고 옵저버 패턴이 갖고 있는 문제점을 인식할 수 있어야한다.
옵저버 패턴(observer pattern) 은 객체의 상태 변화를 관찰하는 관찰자들, 즉 옵저버들의 목록을 객체에 등록하여 상태 변화가 있을 때마다 메서드 등을 통해 객체가 직접 목록의 각 옵저버에게 통지하도록 하는 디자인 패턴이다. 주로 분산 이벤트 핸들링 시스템을 구현하는 데 사용된다. 발행/구독 모델로 알려져 있기도 하다.
예를 들면, 안드로이드에서 Button이 클릭되었을 때 실행할 함수를 onclicklistener에 추가하는데 이와 같이 이벤트 핸들링 처리를 위해 사용되는 패턴이다. 이 패턴에는 Observable과 Observer가 등장한다.
Java는 이미 JDK 1.0 부터 옵저버 패턴을 쉽게 구현할 수 있는 인터페이스를 제공하고 있다. 아래의 코드는 JDK 1.0에 포함된 Observable과 Observer 인터페이스를 사용해 만든 간단한 예시 코드이다.
1 |
|
옵저버 패턴에서는 Publisher(Observable)이 Subscriber(Observer)에게 데이터(이벤트)를 Push(notifyObservers)하는 방식으로 전달한다. 이때, Publisher는 Subscriber의 상태에 상관없이 데이터를 전달하는데만 집중한다.
만약, Subscriber는 1초에 10개의 데이터를 처리할 수 있는데 Publisher가 1초에 20개의 데이터를 전달(Push)한다면 어떤 문제가 발생할까? 다음과 같은 문제가 발생할 수 있다.
Observable과 Observer의 문제를 어떻게 해결할 수 있을까? Publisher가 Subscriber에게 데이터를 Push 하던 기존의 방식을 Subscriber가 Publisher에게 자신이 처리할 수 있는 만큼의 데이터를 Request하는 방식으로 해결할 수 있다. 필요한(처리할 수 있는) 만큼만 요청해서 Pull하는 것이다. 데이터 요청의 크기가 Subscriber에 의해서 결정되는 것이다. 이를 dynamic pull 방식이라 부르며, Back Pressure의 기본 원리이다.
Reactive Streams는 표준화된 API이다. 2013년 netflix, pivotal, lightbend의 엔지니어들에 의해서 처음 시작되어, 2015 4월에 JVM에 대한 1.0.0 스펙이 릴리즈 되었다.
Java 9부터는 reactive streams이 java.util.concurrent의 패키지 아래 Flow라는 형태로 JDK에 포함되었다. 기존에 reactive streams가 가진 API와 스펙, pull방식을 사용하는 원칙을 그대로 수용하였다.
아래는 Reactive Streams API이다.
1 | public interface Publisher<T> { |
실제로 보면 굉장히 간단한 API들의 조합으로 이루어져 있다.
subscribe 메서드 하나만 갖는다.onNext, 에러를 처리하는 onError, 모든 데이터를 받아 완료되었을 때는 onComplete, 그리고 Publisher로부터 Subscription을 전달 받는 onSubscribe 메서드로 이루어진다.request와 구독을 취소하는 cancel을 갖는다.전체적인 흐름은 다음과 같다.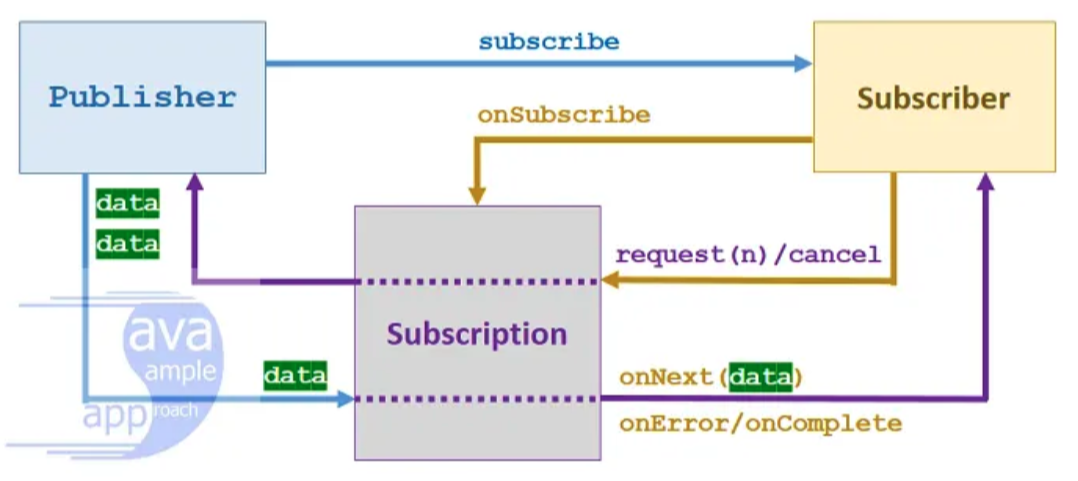
마지막으로 Reactive Streams API를 간단하게 구현해 테스트 해보자.
Reactive Streams API의 Interface는 간단해 보이지만 이를 구현한 구현체는 Reactive Streams Specification을 만족해야만 한다. 구현체가 Specification을 만족하는지는 Reactive Streams TCK(Technology Compatibility Kit)라는 도구를 이용해 검증할 수 있다.
1 |
|
최근 사내에서 Kafka 관련된 설정을 리팩토링하는 작업을 했습니다. SpringBoot를 도입하며 Kafka 설정 관련된 부분들을 SpringBoot의 @ConfigurationProperties를 이용하도록 변경하고, XML 기반의 빈 생성 부분을 Java Config 기반으로 변경했습니다.
현재 프로젝트에서는 여러가지 이유로 기존의 Kafka Producer를 확장(extends)해서 사용하고 있는데, 이번에 리팩토링 관련한 PR에서 확장해서 사용하고 있는 Kafka Producer에서 close 메서드를 구현하고 있는지 확인해달라는 리뷰를 받았습니다.
컨테이너에 등록된 Bean이 DisposableBean interface를 구현하고 있거나 @PreDestroy 어노테이션 또는 destroyMethod 속성을 사용하고 있다면 Bean의 Lifecycle 마지막에 자원을 해제하거나 필요한 작업을 수행할 수 있습니다. 그러나 위의 방법 말고도 Spring container에서 Bean을 제거 할 때, close() 와 shutdown() 메서드를 호출합니다.
Kafka Producer는 Closeable interface를 구현(implement)하고 있기 때문에 close 메서드를 포함하고 있습니다. Kafka Producer가 Bean으로 등록되어 있고 후에 소멸될 때 close 메서드가 호출되어 해당 자원이 모두 해제될 것입니다.
따라서 제가 받았던 리뷰는 기존 Kafka Producer를 확장한 것을 Bean으로 등록해 사용하고 있는데, 해당 확장 클래스가 close 메서드를 제대로 구현해 Bean이 소멸 될 때 호출될 close 메서드에서 자원이 제대로 해제하고 있는지 확인해 달라는 것이었습니다.
AutoCloseable 은 try-with-resource 구문과 함께 사용됩니다.
이번 리뷰를 통해 Bean의 LifeCycle과 close, shutdown 메서드에 대해 다시 살펴보는 계기가 되었습니다.
Initialize 메서드는 Bean Object가 생성되고 DI를 마친 후 실행되는 메서드입니다. 일반적으로 Object의 초기화 작업이 필요한 경우 생성자에서 처리하지만 DI를 통해 Bean이 주입된 후에 초기화할 작업이 있다면 초기화 메서드를 이용해서 초기화를 진행할 수 있습니다.
초기화 하고 싶은 메서드에 @PostConstruct 어노테이션을 붙여주면 Spring이 해당 메서드를 초기화시에 호출합니다. PostConstruct는 JSR-250 스펙에 포함되어 있기 때문에 JSR-250을 구현한 다른 프레임워크 혹은 라이브러리에서도 동작합니다. 다른 초기화 메서드에 비해 Spring에 의존적이지 않다는 장점이 있습니다.
JSR-250
JSR 250 is a Java Specification Request with the objective to develop annotations (that is, information about a software program that is not part of the program itself) for common semantic concepts in the Java SE and Java EE platforms that apply across a variety of individual technologies.
1 |
|
InitializingBean 인터페이스를 구현하면 Spring이 afterPropertiesSet 메서드를 초기화시에 호출합니다.
1 |
|
@Bean 어노테이션을 이용해 Bean을 생성할 때, @Bean 어노테이션의 initMethod 속성을 이용해 초기화 메서드를 지정할 수 있습니다.
1 |
|
Destroy 메서드는 스프링 컨테이너가 종료 될 때, 호출되어 Bean이 사용한 리소스들을 반환하거나 종료 시점에 처리해야할 작업이 있을 경우 사용합니다.
@PreDestroy 도 PostConstruct처럼 JSR-250 스펙에 포함되어 있기 때문에 JSR-250을 구현한 다른 프레임워크 혹은 라이브러리에서도 동작합니다. 컨테이너가 종료 될 때 실행하고 싶은 메서드에 어노테이션을 붙여주면 Spring이 컨테이너 종료 시 해당 메서드를 호출합니다.
1 |
|
DisposableBean 인터페이스를 구현하면 Spring이 destroy 메서드를 호출합니다.
1 | lf4j |
@Bean 어노테이션을 이용해 Bean을 생성할 때, @Bean 어노테이션의 destroyMethod 속성을 이용해 컨테이너 종료시 실행하고자 하는 메서드를 지정할 수 있습니다.
1 |
|
close와 shutdown 메서드는 DisposableBeanAdapter에 의해 실행됩니다.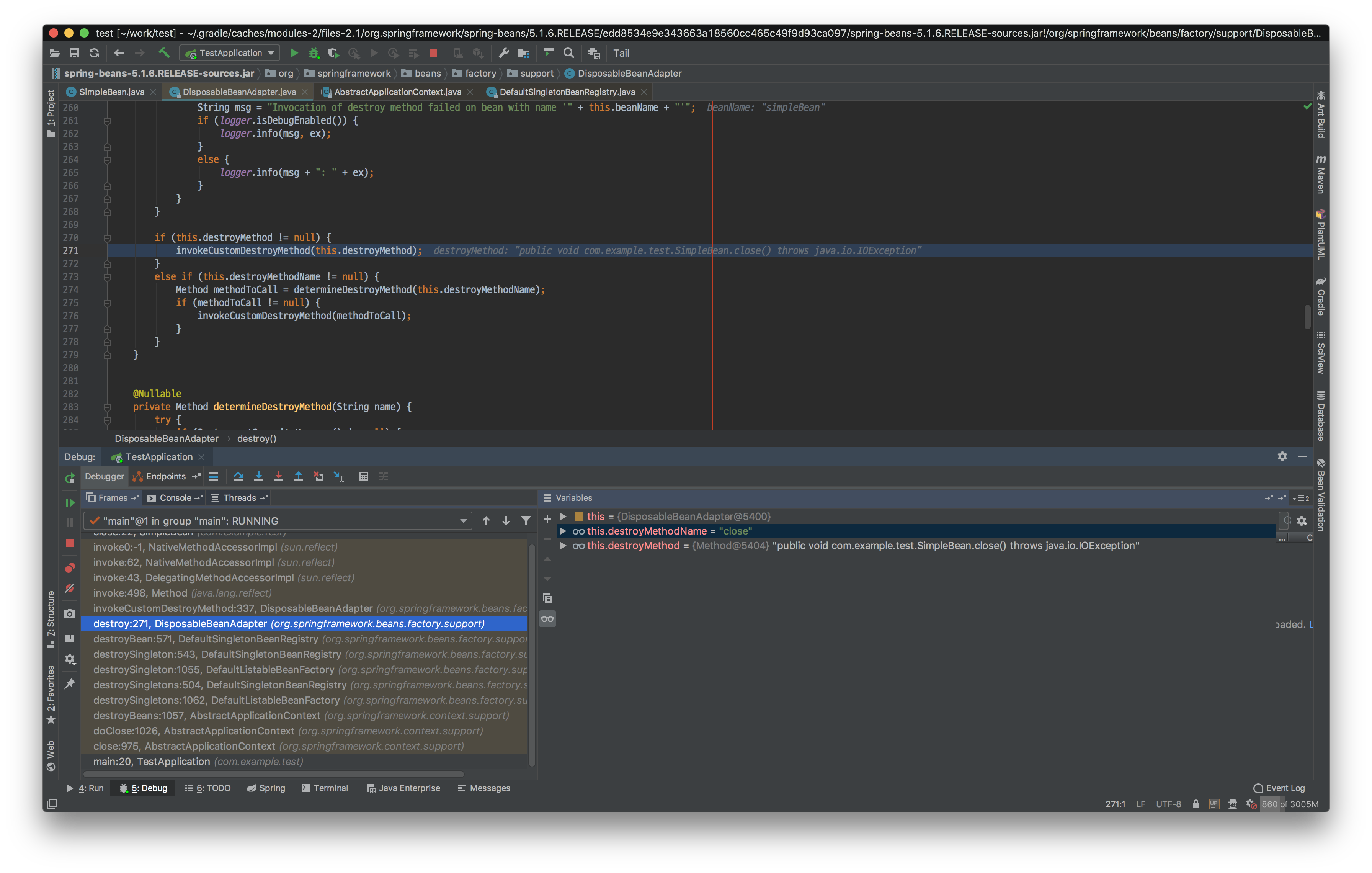
얼마 전 개발자 생에 처음으로 오픈소스에 컨트리뷰트를 하는 경험을 하였습니다. 이번 포스팅에서는 오픈소스 첫 컨트리뷰트 관련해 이야기 해보려 합니다.
개발자라면 한 번쯤 오픈소스에 기여하고 컨트리뷰터가 되어보고 싶다는 생각을 가져봅니다. 저 역시 언젠가 한 번쯤… 이라는 생각은 오래 전 부터 갖고 있었지만 막상 실행에 옮기기 까지가 쉽지 않았습니다. 이미 오픈소스에 기여해 본 많은 개발자 분들이 오픈소스 기여에 쉽게 입문 할 수 있도록 여러 가이드들도 많이 만들어 주셨지만 저는 그 마저도 이용을 하지 못하고 있었습니다. 그러던 도중 우연히 Armeria Sprint라는 좋은 기회가 찾아왔습니다.
LINE의 오픈소스와 Armeria에 대해 조금 더 알아보고 싶다면 다음 글들이 도움이 될 것 같습니다.
사내에서 개발하여 오픈소스로 공개한 프로젝트인 Armeria에 기여할 수 있도록 사내 개발자를 대상으로 Armeria Sprint 행사가 있었습니다.
오픈소스 스프린트란?
오픈소스 스프린트란 오픈소스에 관심있는 사람들이 모여서 오픈소스에 기여해 보는 것이라고 정의할 수 있습니다. 행사마다 편차가 있겠지만 보통 진행 기간을 하루 정도로 잡고 오전에는 다같이 모여서 각자 할 일(어떤 이슈를 맡아서 할지)을 정하고 오후에는 집중해서 코딩을 합니다.
참고 : GitHub Contributions 그래프를 푸릇푸릇하게 만들어보아요(feat. Armeria Sprint)
오픈소스에 기여해 보고 싶어도 여러 이유로 시작하지 못하고 있었던 저는 해당 행사의 인원 모집이 시작되자마자 고민없이 바로 신청해 참가할 수 있었습니다.
행사는 이틀에 나누어서 첫째 날에는 환영 세션이 2시간 동안 진행되었고, 둘째 날에는 스프린트가 4시간 동안 진행되었습니다. 행사 동안에는 간단한 자기 소개, 오픈소스에 기여하기 전에 알야아할 것, 스프린트 기간 동안 해결할 이슈 정하기, 그리고 마지막으로 집중해서 코딩하기와 같은 활동들이 있었습니다.
오픈소스에 처음 기여할 때 어려운 부분 중 하나가 **”어떤 이슈를 맡아 해결하여 기여를 할 것인가”**인데요. 저는 이번 Armeria Sprint를 통해 현재 해결해야 할 이슈들이 어떤 것들이 있는지, 해당 이슈는 어떤 부분에 대한 내용인지에 대해 직접 듣고 모르는 부분은 직접 물어보며 진행 할 수 있었기 때문에 조금은 더 수월하게 진행할 수 있었습니다.
아마 처음 온라인으로 직접 이슈를 처음 선택하기에는 어려운 부분이 있을 것 같은데요. Armeria에서는 good-first-issue 라는 이름의 Label을 붙여 조금은 해결하기 쉬운 이슈들을 표시해주고 있습니다.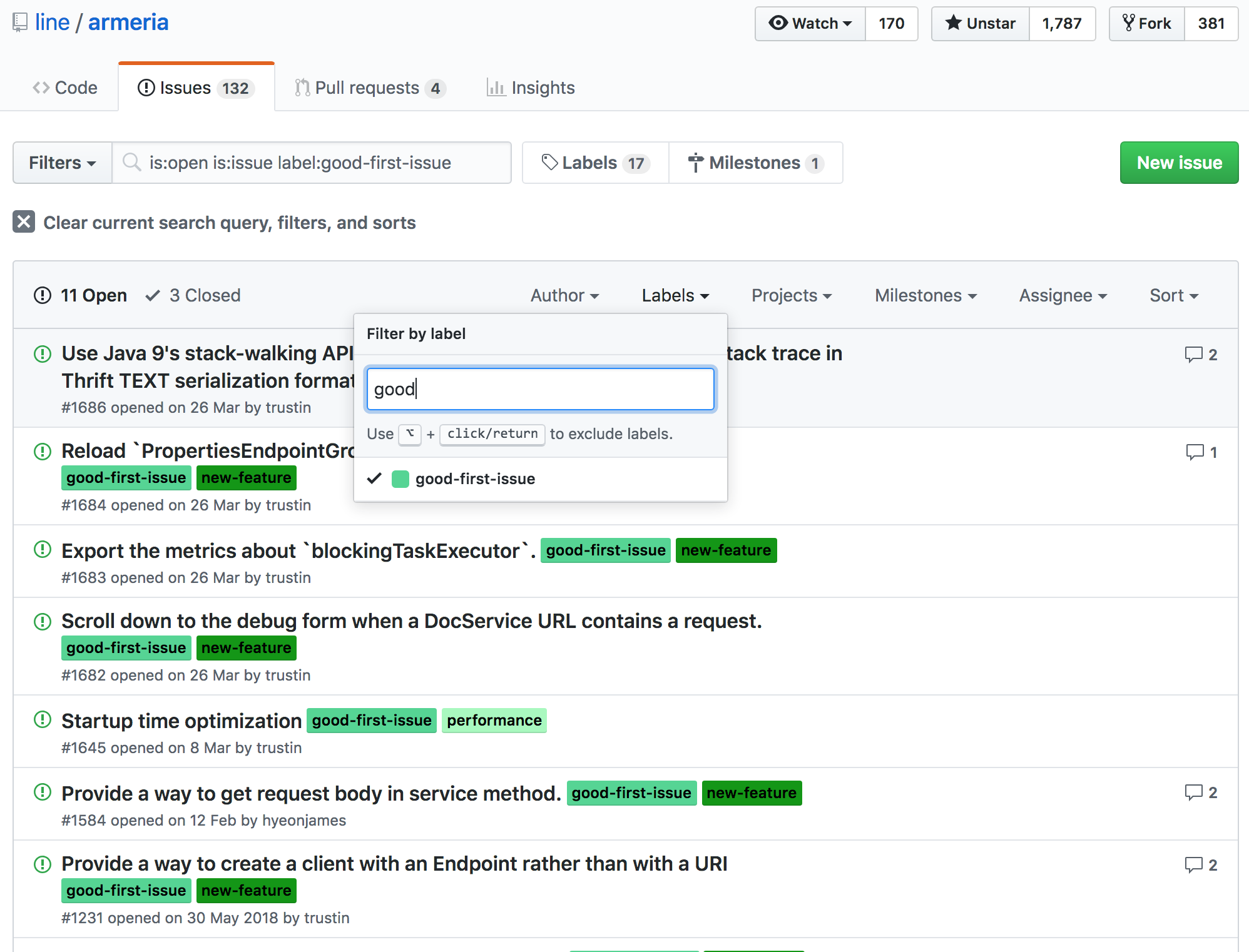
해당 이슈들 중 아는 부분이 있거나 해보고 싶은 이슈가 있다면 본인이 해결해 보겠다는 코멘트를 남긴 후 작업을 진행하면 됩니다.
내가 맡은 이슈가 어떤 문제를 해결(개선)하기 위한 것인지, 코드의 어떤 부분을 수정해야 하는지 파악하는 것이 처음에 가장 중요하다고 생각합니다. 이를 토대로 처음 PR을 올리게 되면 maintainer 분들이 꼼꼼한 리뷰와 함께 코멘트를 남겨주시기 때문에 같이 고민해가며 코드를 점차 개선해 나아갈 수 있습니다.
아래는 Armeria Sprint 동안 제가 맡았던 Issue와 PR입니다.
스프린트 2일차 때, 약 4시간 정도의 시간 동안 코딩을 하고 당일날 첫 PR을 올릴 수 있었습니다. 첫 PR을 올리고 다음날 maintainer 분들의 리뷰 코멘트가 달리기 시작했고, 틈틈히 코멘트 반영과 리뷰를 반복한 결과 약 3주 정도 후 첫 PR이 머지될 수 있었습니다.
위 과정을 반복하며 오픈소스에 기여하는데 있어 필요한 부분들을 다시 한 번 생각해 보게 되었습니다.
Armeria Sprint에서 기념품으로 컵을 받았는데요.
뒤에 이런 문구가 적혀 있었습니다. 오픈소스에 그리고 Armeria에 관심이 있다면 여러분들도 한 번 기여해보세요!
처음으로 오픈소스에 기여해보았다는 것, 그리고 그 오픈소스가 Armeria라는 것이 매우 재밌고 뜻 깊은 경험이었습니다. 저도 이번 첫 컨트리뷰트를 시작으로 가능하면 꾸준히 기여를 해보려고 합니다.
build script의 dependencies 블록에 여러 가지 다양한 종속성 구성(api, implementation, compileOnly, runtimeOnly, annotationProcessor)을 사용하여 라이브러리 종속성을 선언할 수 있습니다. 다양한 종속성 구성 중 api와 implementation의 차이에 대해서 알아봅니다.
Gradle document에서는 api와 implementation에 대해서 다음과 같이 설명하고 있습니다.
The dependencies required to compile the production source of the project which are part of the API exposed by the project. For example the project uses Guava and exposes public interfaces with Guava classes in their method signatures.
프로젝트에 의해 노출 된 API의 일부인 프로젝트의 프로덕션 소스를 컴파일하는 데 필요한 종속성
The dependencies required to compile the production source of the project which are not part of the API exposed by the project. For example the project uses Hibernate for its internal persistence layer implementation.
프로젝트에 의해 노출 된 API의 일부가 아닌 프로젝트의 프로덕션 소스를 컴파일하는 데 필요한 종속성
위 설명만 가지고는 이해하기가 쉽지 않습니다. Android Developers document에서는 같은 내용을 다음과 같이 한글로 설명하고 있습니다.
Gradle은 컴파일 클래스 경로 및 빌드 출력에 종속성을 추가합니다. 모듈에 api 종속성을 포함하면 다른 모듈에 그 종속성을 과도적으로 내보내기를 원하며 따라서 런타임과 컴파일 시 모두 종속성을 사용할 수 있다는 사실을 Gradle에 알려줄 수 있습니다.
이 구성은 compile(현재 지원 중단됨)과 똑같이 동작합니다. 다만 이것은 주의해서 사용해야 하며 다른 업스트림 소비자에게 일시적으로 내보내는 종속성만 함께 사용해야 합니다. 그 이유는 api 종속성이 외부 API를 변경하면 Gradle이 컴파일 시 해당 종속성에 액세스할 권한이 있는 모듈을 모두 다시 컴파일하기 때문입니다. 그러므로 api 종속성이 많이 있으면 빌드 시간이 상당히 증가합니다. 종속성의 API를 별도의 모듈에 노출시키고 싶은 것이 아니라면 라이브러리 모듈은 implementation 종속성을 대신 사용해야 합니다.
Gradle은 종속성을 컴파일 클래스 경로에 추가하여 종속성을 빌드 출력에 패키징합니다. 다만 모듈이 implementation 종속성을 구성하는 경우, 이것은 Gradle에 개발자가 모듈이 컴파일 시 다른 모듈로 유출되는 것을 원치 않는다는 것을 알려줍니다. 즉, 종속성은 런타임 시 다른 모듈에서만 이용할 수 있습니다.
api 또는 compile(지원 중단됨) 대신 이 종속성 구성을 사용하면 빌드 시스템이 재컴파일해야 하는 모듈의 수가 줄어들기 때문에 빌드 시간이 상당히 개선될 수 있습니다. 예를 들어, implementation 종속성이 API를 변경하면 Gradle은 해당 종속성과 그 종속성에 직접 연결된 모듈만 다시 컴파일합니다. 대부분의 앱과 테스트 모듈은 이 구성을 사용해야 합니다.
간단하게 차이점을 정리하면 다음과 같습니다.
해당 포스팅은 토비님의 토비의 봄 TV 11회 스프링 리액티브 프로그래밍 (7) CompletableFuture 라이브 코딩을 보며 따라했던 실습 내용을 바탕으로 정리한 글입니다.
실습 코드들은 IntelliJ를 이용해 SpringBoot 2.1.3.RELEASE 버전 기반으로 프로젝트를 생성 후(web, lombok 포함) 진행했습니다.
이번에는 자바8에 나온 CompletableFuture 라는 새로운 비동기 자바 프로그래밍 기술에 대해서 알아보고, 지난 3회 정도 동안 다루어 왔던 자바 서블릿, 스프링의 비동기 기술 발전의 내용을 자바 8을 기준으로 다시 재작성합니다.
먼저 간단한 코드를 통해서 CompletableFuture 사용법에 대해서 알아보겠습니다.
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
Spring 4.0에 들어간 AsyncRestTemplate이 return하는 것은 CompletableFuture가 아닌 ListenableFuture입니다.
Spring 4까지는 자바 6~8을 지원하기 때문에 CompletableFuture로 return을 만들지 못하고 계속 ListenableFuture를 유지했습니다. 따라서 ListenableFuture를 CompletableFuture로 만들어 체이닝하기 위해서는 유틸성 wrapper 메서드를 만들어 사용하면 됩니다.
1 |
|